線程池大小設置多少合理
大部分讀者可能都會看過網上的幾篇文章,對于線程數的設定基本都是采用下面這個公式:
計算密集型=CPU核心數+1
IO密集型=CPU核心數*2+1然而事實真的是這樣嗎?那么為什么tomcat服務器的核心線程數要設置為200呢?基于此問題,筆者也基于個人的經驗和實踐給出自己的一套方法論,希望對你有幫助。

一、線程池調測實踐
1. 單計算任務是否可以跑滿單個CPU
針對上述的公式,作者認為計算密集型的任務基本都在進行CPU運算,沒有所謂的IO等待,所以設置線程池參數時,只需設置為:
CPU核心數+1注意,這里的加1是為了保證及時因為偶發的缺頁中斷亦或者某些異常導致某個線程消亡,也能利用額外的一個線程跑滿CPU時鐘周期,以確保在單位時間內盡可能的利用到CPU。
所以我們是否可以得出這個結果,如果我們的計算密集型的任務不斷的循環跑,它就能跑滿單個CPU呢?
對此我們給出下面這樣一段代碼,在web程序啟動之后直接無限循環:
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
public class ThreadPoolApplication {
public static void main(String[] args) {
SpringApplication.run(ThreadPoolApplication.class, args);
//空跑一個循環
while (true) {
}
}
}
}將程序部署到服務器上啟動,可以看到在筆者16核的服務器上,Cpu6 跑滿100%,很明顯我們的程序霸占了這個CPU核心,由此可以印證對于CPU在單位時間內只能指向一個線程的指令:

2. 密集計算任務與CPU調度的關系
有了上面的理論基礎,我們將線程數設置為CPU核心數的一半,看看當前的服務器的運行情況:
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
public class ThreadPoolApplication {
public static void main(String[] args) {
SpringApplication.run(ThreadPoolApplication.class, args);
//創建CPU核心數一半的線程
for (int i = 0; i < Runtime.getRuntime().availableProcessors() >> 1; i++) {
new Thread(() -> {
//空跑一個循環
while (true) {
}
}).start();
}
}
}和預測的結果一樣,對于計算密集型的任務而言,每一個空循環的線程(即每一個線程的指令都會綁定一個CPU核心):

這也就意味著,對于計算型的任務,在滿載運行的情況下,可以完全利用單個CPU核心,由此也可推出,對于計算密集型的任務,滿載情況下,所有的CPU利用率都會達到100%。
對此我們不妨設置的更極端一點,嘗試將線程數設置為CPU核心數的2倍:
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
public class ThreadPoolApplication {
public static void main(String[] args) {
SpringApplication.run(ThreadPoolApplication.class, args);
//創建CPU核心數2倍的線程
for (int i = 0; i < Runtime.getRuntime().availableProcessors() << 1; i++) {
new Thread(() -> {
//空跑一個循環
while (true) {
}
}).start();
}
}
}可以看到此時利用率全滿了,并且對應的負載也非常顯著的提高了,在最近的一分鐘可以基本已經達到CPU核心數了:

這里補充一下負載的概念,在單核情況下,負載的值為在0~1之間,這就意味著當前cpu還未滿載,用一個比較通俗的比喻,假如單核CPU的負載值為0.5,這就意味著單條車道上有一半的車流經過,還可以容納一半的車駛入:

業內普遍認為在單核CPU的場景下,負載處于0.7是比較正常標準,如果超過這個值就說明過載了。
同理,筆者的服務器為16核,按照上述所說我們的服務器可以看到有16條車道,所以當負載值小于16即說明有CPU核心未跑滿載,一旦負載超過11.2(16*0.7)就意味著我們的系統可能過載了。
我們將執行計算密集型的任務的線程數設置為CPU核心數的2倍,負載不斷提升已經超過了11.2,所以對于計算密集型任務,本次線程數的設置是存在問題的:
top - 00:21:38 up 1:09, 1 user, load average: 17.69, 10.45, 8.23自此我們就印證了為什么對于計算密集型的任務,我們更簡易將線程數設置為趨近于CPU核心數的原因了。
3. IO密集型任務調測
為了實現IO密集型實驗,筆者基于一臺8核心的服務器編寫好程序,將計算時間和IO時間盡可能的設置為五五開,如下所示,讀者可結合自身服務器性能按需調整:
public static void main(String[] args) {
SpringApplication.run(ThreadPoolApplication.class, args);
ExecutorService threadPool = Executors.newFixedThreadPool(1);
//單線程的線程池執行一個計算和IO五五開的任務
threadPool.execute(() -> {
while (true) {
//執行循環空跑模擬計算
for (int i = 0; i < Integer.MAX_VALUE >> 4; i++) {
for (int j = 0; j < Integer.MAX_VALUE; j++) {
}
}
//休眠50ms
ThreadUtil.sleep(50);
}
});
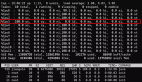
}性能監控結果如下,可以看到單核CPU利用率趨近于50%:
top - 17:29:01 up 3:05, 8 users, load average: 0.66, 0.52, 0.46
Tasks: 499 total, 1 running, 498 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu6 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
# 趨近于50%
%Cpu7 : 43.0 us, 0.0 sy, 0.0 ni, 57.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st基于這個比例,我們將線程數設置為CPU核心數再次運行,最終運行結果如下,可以看到所有的CPU利用率都趨近于50%:
Tasks: 494 total, 1 running, 493 sleeping, 0 stopped, 0 zombie
%Cpu0 : 53.2 us, 0.0 sy, 0.0 ni, 46.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 53.7 us, 0.0 sy, 0.0 ni, 46.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 49.3 us, 0.0 sy, 0.0 ni, 50.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 52.7 us, 0.0 sy, 0.0 ni, 47.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 52.7 us, 0.0 sy, 0.0 ni, 47.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 53.3 us, 0.3 sy, 0.0 ni, 46.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu6 : 53.2 us, 0.0 sy, 0.0 ni, 46.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu7 : 53.0 us, 0.0 sy, 0.0 ni, 47.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 7995716 total, 5055564 free, 1529664 used, 1410488 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 6155340 avail Mem4. 結合公式落地IO密集型任務線程池配置
根據《Java并發編程實戰》所說,對于IO密集型任務,線程數可按照如下公式獲取
nThread=nCPU * uCPU * (1+w/c)對應的參數含義是:
- nThread:表示程序中應該使用的線程數量。
- nCPU:表示系統中可用的CPU核心數量。
- uCPU:表示每個CPU核心的利用率(通常是一個介于0到1之間的值)。
- w/c:表示程序中等待時間(wait time)與計算時間(compute time)的比率。
因為我們的CPU為8核,我們希望全部利用,假設每個利用率為90%,按照我們IO時間和計算時間五五開來算,線程數的計算公式為:
nThread=nCPU * uCPU * (1+w/c)
= 8 * 0.9 * (1+1)
= 14.4
≈ 15因此我們將線程數設置為15個再次啟動并運行,可以看到最終的CPU利用率和預期的基本一致,我們可能還需要結合服務器的實際使用情況進行上下浮動調整:
top - 19:08:52 up 3:50, 8 users, load average: 1.16, 2.44, 2.65
Tasks: 499 total, 3 running, 496 sleeping, 0 stopped, 0 zombie
%Cpu0 : 89.7 us, 0.0 sy, 0.0 ni, 10.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 91.4 us, 0.3 sy, 0.0 ni, 8.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 87.0 us, 0.0 sy, 0.0 ni, 13.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 91.7 us, 0.0 sy, 0.0 ni, 8.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 87.7 us, 0.0 sy, 0.0 ni, 12.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 91.0 us, 0.0 sy, 0.0 ni, 9.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu6 : 93.7 us, 0.0 sy, 0.0 ni, 6.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu7 : 86.7 us, 0.0 sy, 0.0 ni, 13.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 7995716 total, 5025368 free, 1558680 used, 1411668 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 6125500 avail Mem二、關于線程池公式的更進一步討論
1. 計算密集型任務的公式的推導
關于計算密集型任務推導公式,很多讀者都是死記硬背,這里讀者從這里從工作機制和公式推導兩個角度進行補充說明。 計算密集型任務即任務不涉及任何IO操作導致阻塞而讓出CPU時間片,這意味著所有的任務都必須通過CPU完成運算才算結束,舉個例子:假設我們的服務器只有一個CPU,單個任務運算耗時為200ms,如果有1000個任務需要執行,無論如何這份任務在CPU上的執行總時間都是200000ms也就是200s:

操作系統在這其中唯一能做的,也就是為了避免任務饑餓在某個任務執行100ms時將其切換,執行另外一個任務,但是兩個任務總的耗時永遠是400ms,且必須在CPU上執行完成,所以即使設置再多的線程也沒有任何意義:

從公式的角度來說,對應計算密集型的任務w也就是程序因為IO的等待時長為0,按照極限思維來算,對應的推導過程如下
nThread= nCPU * uCPU * (1+w/c)
= nCPU * uCPU * (1+0/c)
= nCPU * uCPU最終推導出的線程數也就是基本等同于CPU核心數*CPU利用率也就是CPU核心數,考慮到一些計算異常亦或者缺頁中斷等原因導致線程消亡,我們一般會按照經驗法則多1個線程,這就是為什么計算密集型的公式為CPU核心數+1,同時也因為計算密集型的任務一般不會有太大的耗時,所以大部分情況下對于此類任務都沒有基于CPU利用率去限制線程數。
2. 為什么會出現IO密集型線程數為CPU核心數*2+1的錯誤說法
這個公式是很多八股文中經常會提及到的一點,按照筆者的推測,估計是某些博主沒有真正的理解線程數推導公式的含義就盲目按照理想情況下所得出的,本質上nThread= nCPU * uCPU * (1+w/c)這個公式的含義是:
利用任務IO阻塞的等待時長和計算時長的占比,推導出某些任務因為任務阻塞而掛起時可以順便執行多少計算任務
假設我們的任務查詢數據庫也就是IO耗時為100ms,計算時長也是100ms,按照公式計算為:
nThread= nCPU * uCPU * (1+w/c)
= nCPU * uCPU * (1+100ms/100ms)
= nCPU * uCPU * 2可以看到最終的結果就是nCPU * uCPU * 2,是不是覺得很熟悉?沒有錯,大部分錯誤的八股文把IO密集型任務都按照計算耗時與IO阻塞耗時五五開進行推導得出nCPU * uCPU * 2,然后也學著計算密集型的套路:
- 去掉CPU利用率
- 避免缺頁中斷等異常線程數+1
最終得出2* CPU +1,所以這也正是為什么筆者一直強調對于一些業界正確的實踐要參考一些權威性的書籍資料去了解掌握。
反駁了CPU核心數*2+1這個公式之后,我們再來說說正確公式的由來,在上文中筆者提到該公式本質上就是利用任務IO等待耗時和計算耗時的占比,來推算IO阻塞期間可以提前執行掉多少的運算任務,假設我們現在有這樣一個場景:
- 服務器CPU核心數為18
- 計算耗時為1ms
- IO耗時為200ms
實際上(1+w/c)這個過程本質上就是在計算針對這個任務,在IO阻塞期間可以提前完成多少計算操作,按照我們的計算比來說每個任務都有200ms的IO阻塞,這也就意味著在200ms的阻塞期間,理想情況下(如果CPU全心全意只執行我們這個程序的任務),阻塞期間可以處理w/c也就是200個計算操作:

基于上述單核的推導過程,我們再補充CPU核心數和利用率才有了下面的公式和計算過程:
nThread= nCPU * uCPU * (1+w/c)
= 18 * 1 * (1+200ms/1ms)
≈3600按照當前任務的說明,我們推算:
- 理想情況下單核CPU單位時間內可以處理1000個計算操作,換算成我們的18核服務器,也就是每秒可以處理大約18*1000也就是18000個任務。
- 基于我們推測的3600個線程數,按照每個任務200ms的IO來算,每個線程1s內可以處理大約1000/200也就是5個任務,那么3600個線程大約也是可以達到18000的任務
為了印證第一點的預期值和我評估的線程數值一致,我們寫下下面這樣一段代碼,查看當前線程數的設定在單位時間內是否可以處理18000個任務:
//qps 計數器
private static final AtomicInteger count = new AtomicInteger(0);
//按照 1ms cpu處理耗時,推算合理運算線程池數
private static final ExecutorService threadPool = Executors.newFixedThreadPool(3600);
public static void main(String[] args) {
int taskCount = 500_0000;
//計算每秒處理的任務數
new Thread(() -> {
while (true) {
Console.log("qps:{} ", count.get());
count.getAndSet(0);
ThreadUtil.sleep(1000);
}
}).start();
for (int i = 0; i < taskCount; i++) {
threadPool.execute(() -> {
ThreadUtil.sleep(200);
count.incrementAndGet();
});
}
}最終輸出結果如下,可以看到,在程序啟動后JIT預熱階段完成后,基于我們設定的線程數是可以完成單位時間內執行18000個任務:

同理,我們再補充一個案例來推導這個公式的實效性以避免欠擬合:
- 服務器18核
- 計算耗時2ms
- IO耗時 200ms
同理按照公式推導大約需要1800個線程,結合驗證:
- 單核CPU單位時間內可以處理1000/2也就是500個任務,也就是最終結果應該是9000個任務
- 我們推算出的1800個線程,單位時間內每個線程可以處于1000/202≈5,1800*5也可以達到9000
基于筆者的機器性能,筆者也出這樣一段耗時2ms的代碼:
public static int sum() {
long begin = System.currentTimeMillis();
long sum = 0;
for (int i = 0; i < 800_0000; i++) {
sum += i;
}
long end = System.currentTimeMillis();
if (sum != 1) {
return (int) (end - begin);
}
return 0;
}同理壓測代碼如下:
//qps 計數器
private static final AtomicInteger count = new AtomicInteger(0);
//按照 1ms cpu處理耗時,推算合理運算線程池數
private static final ExecutorService threadPool = Executors.newFixedThreadPool(1800);
public static void main(String[] args) {
int taskCount = 500_0000;
//計算每秒處理的任務數
new Thread(() -> {
while (true) {
Console.log("qps:{} ", count.get());
count.getAndSet(0);
ThreadUtil.sleep(1000);
}
}).start();
for (int i = 0; i < taskCount; i++) {
threadPool.execute(() -> {
sum();
ThreadUtil.sleep(200);
count.incrementAndGet();
});
}
}最終輸出結果如下,可以看到理想情況下,基于該公式是可以得到預期的結果:

三、小結
上述的線程池設置更多是基于理想情況下的調整設置,讀者在進行壓測調整時,還需要結合機器實際使用情況進行適當增減,所以總的來說線程池參數的設定需要符合以下幾個原則:
- 計算密集型任務應該為CPU核心數上下浮動。
- IO密集型應該通過公式2得到一個預估的值并結合生產環境的情況不斷測試得到一個理想的數值。
- 大部分場景下我們的系統并沒有太大的壓力,不需要那么合適的線程數,對于這種簡單的異步場景,我們只需設置為CPU核心數即可。