基于文件指紋的Web文本挖掘
在迅猛增加的海量異構的Web信息資源中,蘊含著巨大潛在價值的數據。如何從浩如煙海的Web資源中發現潛在有價值的知識成為迫在眉睫的問題。人們迫切需要能從Web上快速、有效地發現資源和數據的工具,以提高在Web上檢索信息、利用信息的效率。
目前Web文本挖掘大部分研究都是建立在詞匯袋(bag of words)或稱向量表示法(Vector Representation)的基礎上,這種方法將單個的詞匯看成文檔集合中的屬性,只從統計的角度將詞匯孤立地看待而忽略該詞匯出現的位置和上下文環境。詞匯袋方法的一個弊端是自由文本中的數據豐富,詞匯量非常大,處理起來很困難,為解決這個問題人們做了相應的研究,采取了不同技術,如信息增益,交叉熵、差異比等,其目的都是為了減少屬性。一個比較有意義的方法是潛在語義索引(Latent Semantic Indexing),它通過分析不同文檔中相同主題的共享詞匯,找到它們共同的根,用這個公共的根代替所有詞匯,以此來減少維空間。其它的屬性表示法還有詞匯在文檔中的出現位置、層次關系、使用短語、使用術語、命名實體等,目前還沒有研究表明一種表示法明顯優于另一種。
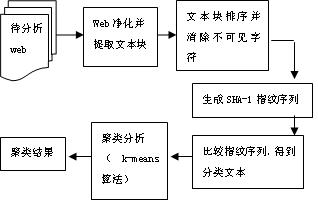
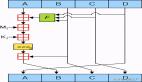
圖1 文本聚類模型
本文所提出的挖掘技術,不是基于詞匯屬性,而是文本塊。在利用網頁的標簽樹結構的基礎上,提取標題和文本塊生成SHA-1指紋序列,如果兩個頁面具有的相同的指紋塊在我們所設定的范圍內,那么就把這兩個頁面歸為一類,類值就是所要聚類的準確數目k,接下來用k-means進行文本聚類,達到文本挖掘的目的[2][3]。圖1是文本聚類模型。
文本預處理
◆網頁凈化
由于Web文本上存在大量的廣告、html標簽、相關鏈接等無用信息,所以首先要對所收集到的網頁進行凈化處理,也稱為網頁去噪,以提高聚類效果。我們把網頁設計者為了輔助網站組織而增加的文字定義為“噪聲”,把原本要表達的文字素材稱為“主題內容”。 這些噪音是與頁面主題無關(即瀏覽者不關心)的區域及項,包括廣告欄、導航條、修飾成分等。
這樣,我們對HTML源碼進行分析,根據起分隔作用的標記去掉噪音部分,提取出網頁正文[4]。
◆生成SHA-1指紋
SHA的全稱是Secure Hash Algorithm,即安全哈希算法。它是由美國國家標準和技術協會(NIST)開發,于1993年作為聯邦信息處理標準(FIPS PUB 180)公布。1995年又發布了一個修訂版FIPS PUB 180-1,通常稱之為SHA-1。現在已成為公認的最安全的散列算法之一,并被廣泛使用。該算法的思想是接收一段明文,然后以一種不可逆的方式將它轉換成一段(通常更小)密文,也可以簡單的理解為取一串輸入碼(稱為預映射或信息),并把它們轉化為長度較短、位數固定的輸出序列即散列值(也稱為信息摘要或信息認證代碼)的過程[5]。
由于sha-1算法的雪崩效應,對文本塊作信息摘要時,要消除文本塊中的不可見字符,而文本塊排序是為了降低算法的復雜度。對于凈化后的文本塊,通過格式分析生成M個文本塊B1,B2,…BM(文本塊按重要性排序),取前m(≤ M)個文本塊生成sha-1指紋sha-11,sha-12,…sha-1m。對于網頁對(pi,pj),定義STm (pi,pj)= m0/m,其中m0為pi,pj的相同sha-1指紋的個數。易得,給定范圍t,如果STm (pi,pj)∈t,則把兩個頁面歸為某一類。
文本聚類
目前,有多種文本聚類算法,常見的聚類方法有層次凝聚類方法和以k-means為代表的平面劃分法。
層次聚類方法能夠生成層次化的嵌套簇,且準確度較高。但是在每次合并時需要全局地比較所有簇之間的相似度,并選擇出最佳的兩個簇,因此運行速度較慢,不適合于大量文檔的集合。
近年來各種研究顯示,平面劃分法比層次凝聚法更適合對大規模文檔進行聚類,這是因為平面劃分法的計算量相對較小。如:層次凝聚法中的Single-link和group-average方法的時間復雜度為O(n2),complete-link法的時間復雜度為(n3),n為文檔數。而平面劃分法中的k-means法的時間復雜度為O(nKT),single-pass法的時間復雜度為O(nK),其中n為文檔數,k是最終聚類數目,T是迭代次數。
所以本文選取k-means算法進行文本聚類,k-means 算法接受輸入量 k;然后將n個數據對象劃分為 k個聚類以便使所獲得的聚類滿足,同一聚類中的對象相似度較高;而不同聚類中的對象相似度較小。聚類相似度是利用各聚類中對象的均值所獲得一個“中心對象”(引力中心)來進行計算的。
k-means 算法的工作過程說明如下:首先從n個數據對象任意選擇 k 個對象作為初始聚類中心;而對于所剩下其它對象,則根據它們與這些聚類中心的相似度(距離),分別將它們分配給與其最相似的(聚類中心所代表的)聚類;然后再計算每個所獲新聚類的聚類中心(該聚類中所有對象的均值);不斷重復這一過程直到標準測度函數開始收斂為止。一般都采用均方差作為標準測度函數。
雖然k-means算法對初始聚類中心選取較敏感,但在本文中,文本分成了多少個類,就有多少個k對象。以兩個文本塊相同的指紋數作為它們的相似度做聚類得到最終聚類結果。
總結
本文舍棄了常用的提取特征值,計算文本相似度的方法,而是對凈化的文本塊作分塊的信息摘要(即文件指紋),在比較相同指紋的基礎上對文本進行分類,以類值為k-means算法的初始聚類值,以兩文本的相同指紋數作為文本的相似度做文本聚類。
【編輯推薦】