深度挖掘 Web 緩存體系
前言
很高興認識大家,之前做過很多分享,今天這次終于講到正題了。因為之前一直講自動化運維,其實做這么多年運維,自動化運維沒干多少年。這幾年很多公司各方面機器數量多了,規模大了才開始去做自動化運維。
今天的課題是高性能Web架構之緩存體系,之所以講這個體系是因為作為一名運維工程師,我們經常會遇到Web站點訪問很慢的情況。要解決這個問題,直接找開發,問題也不一定能解決。因為這個問題不僅僅是開發的問題,
這個問題涉及到瀏覽器從發出請求到響應請求的一系列問題,所有地方都需要一點點摸清楚才能***找到問題所在。
1、認識Web緩存知識體系
1.1從HTTP請求說起
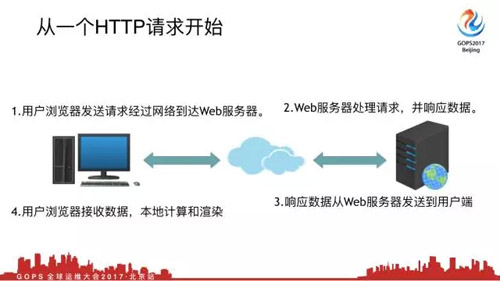
我們從一個Http的請求開始,先介紹下環境,左邊是我們的用戶端瀏覽器,右邊是我們的Web服務器,當然Web服務器后面整體架構就不說了。
- ***步,當用戶瀏覽器發出一個請求,這個請求會經過網絡到達Web服務器。這句話說明了當一個數據包從用戶端發送到Web服務器端,這個時間是時網絡延遲時間。
- 第二步,Web服務器處理請求,并響應數據。如果是動態請求我需要查緩存,查數據庫,最終把請求返回給瀏覽器,這個時間是響應時間。
- 第三步,響應數據從Web服務器發送給用戶端,這又是網絡傳輸時間。
- 第四步,用戶瀏覽器接收數據,本地計算和渲染。這個時間就是計算和渲染的時間,你的JS腳本不一樣,渲染時間也是不一樣的,但是這個時間是比較小的。
1.2 處理數據的時間去哪了?
Web訪問時間大家看主要花費在哪幾個方面,客戶端請求,從用戶端發到服務器端,服務器端響應,服務器端發回用戶端,還有一個比較大的時間是處理數據的時間。
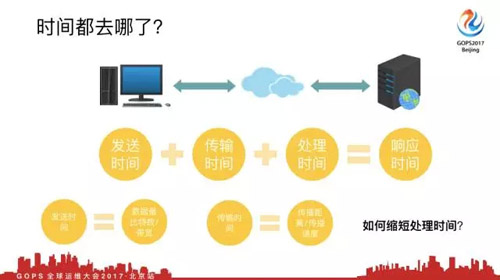
我們來研究一下時間都去哪兒了,發送時間+傳輸時間+處理時間=響應時間。發送時間=數據量比特數/帶寬,傳輸時間=傳輸距離/傳輸速度,這就是整個數據包的傳輸時間。
目前網絡的處理時間很多時候我們不是說不能去優化,至少可以說我們普通的運維和開發在這塊接觸的少一些。現在可能也有很多做網絡傳輸優化的產品,這里我們暫不討論。
1.3 如何縮短處理時間
我們今天討論,如何縮短處理時間。因為返回數據我們可以通過各種各樣方式解決。那么處理時間如何縮短也有很多方式。比如你去提高服務器并發,修改架構等等有非常多的處理方式。咱們今天講如何使用緩存來減少處理時間這是今天的重點。
就像我說的在網上找不到一個完整的請求從出來一直到***所經歷的緩存,怎么辦?自己寫一個,我按照一個Http請求從瀏覽器發出一直到***,把所經歷的緩存全部做了一遍。
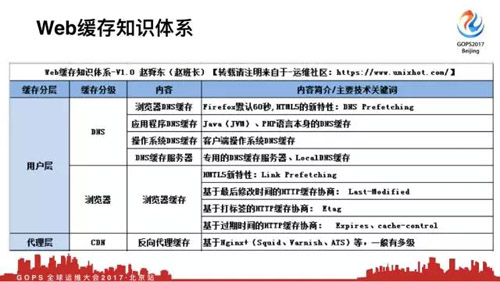
首先用戶層在瀏覽器輸入一個域名,這個時候***步不是DNS解析。***步是瀏覽器DNS緩存,比如谷歌、火狐瀏覽器默認的就是60秒。這沒有嚴格意義上的上下級,應用程序DNS緩存,操作系統DNS緩存,DNS緩存服務器。***解析出IP地址,然后到瀏覽器緩存。
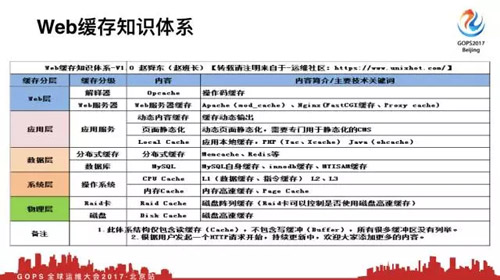
我們會講瀏覽器緩存協商的三種辦法。然后請求繼續往下就走到代理層,CDN代理緩存。
然后請求會到達Web服務器,然后到應用層,然后到數據庫,有數據庫緩存,然后到系統層面。
***要訪問硬盤上某一個文件,有系統層面緩存。***到物理層,要訪問硬盤上的某一個數據,要讀寫某一個blog,這就涉及到物理層。我們僅包括讀緩存,沒有包括寫緩存。
2、關于Buffer與Cache
2.1什么是Buffer和Cache?
- Buffer一般用于寫操作,我們稱之為寫緩沖。為什么會有Buffer呢?因為不同的計算設備它的速度不同,比如說CPU能直接往硬盤寫數據嗎?因為硬盤太慢了,所以CPU只能寫在內存里,內存再往硬盤寫,我們稱之為緩存。
- Cache一般用于讀操作,我們可以稱之為讀緩存,我們把正常取用的數據放在離我們最近的地方,我們可以快速取到。
2.2 什么是Cache
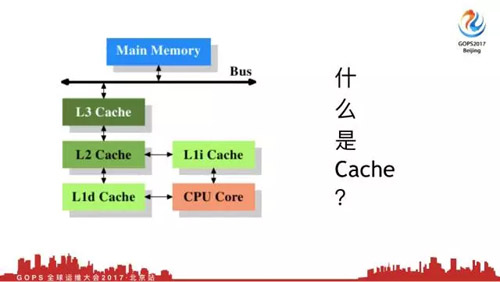
這是一個Cache案例,這是CPU有三級緩存,三級Cache,然后內存。現在先不要考慮Cache和Buffer的區別。
2.3 什么是Buffer?
白色曲線區域是左轉彎待轉區,它的作用是:比如現在是紅燈,但是我們車可以越過停止線到左轉彎待轉區,待轉區是弧形的,離目的地更近的區域,這就是生活中Buffer的案例。
我將車停在離目的地更近的地方,這樣轉彎的時候一下子就可以轉過去,我可以轉得更快,轉得更快就可以減少道路的擁堵,這就是Buffer的作用。
2.4 再次定義Buffer與Cache!
在我們計算機中也是一樣的,CPU寫數據不能直接寫硬盤,因為硬盤太慢了,我不能等待,這時候我把數據寫在內存中返回,剩下內存再往硬盤里寫。
但是很多時候我們不會特別區分Buffer和Cache,因為很多的區域會發現,不僅僅有讀緩存Cache的功能,也有寫緩存Buffer的功能。所以你經常看到有些區域是Buffer開始,或者統一叫做開始,這個時候怎么分辨呢?
根據它的功能不同來區分是Buffer還是Cache,有的Cache就僅僅指的是讀緩存,它沒有Buffer功能,但是有的Cache里面有Cache有Buffer,比如內存就是典型的。我們寫數據寫內存,讀數據也是內存里面讀,這個就是典型的名詞的問題。所以很多時候我們不用糾結它是Buffer還是Cache,我們怎么分辨呢?
我們通過它的功能來分辨:
- Cache一般用于讀緩存,用于將頻繁讀取的內容放入緩存,下次再讀取相同的內容,直接從緩存中讀取,提高讀取性能,緩存可以有多級。
- Buffer一般用于寫緩沖,用于解決不同介質直接存儲速度的不同,將數據寫入到比自己相對慢的不是很多的中間區域就返回,然后最終再寫入到目標地址,提高寫入性能,緩沖也可以有多級。就像內存寫硬盤也很難,所以硬盤都會用緩存。
我們都知道硬盤都會有一個Cache,這個Cache其實有Buffer的功能,也有Cache的功能。因為寫數據只要往硬盤里寫數據,就會經過Cache區域,讀數據,我們很多有預讀的功能也要經過這個區域,這個區域就叫做Buffer開始或者簡稱開始。
可以看到緩存和緩沖都可以有多級,或者說可以分層。咱們很多做開發的,應該會知道分層分級這種設計是一個架構師最基本的設計方式。
- 3.關于Cache
- 3.1存放位置

Cache存放位置,我們還是站在Web架構角度。
- 客戶端,我這個網頁要存在客戶端當然快了,用戶根本不用發請求直接就打開了,這時候就是瀏覽器緩存。瀏覽器就是把我的緩存存在用戶客戶端,所以用戶打開頁面就會非常快。
- 內存,內存就分為最快本機內存,但是本機內存的容量有限,這時候可以存在遠程服務器內存。比如分布式緩存其實就是存在遠程服務器的內存,當然性能沒有本地內存好,因為要經過網絡傳輸。網絡傳輸就會有時間,會有性能的影響。
- 硬盤,本機硬盤是***的,再往下遠程服務器硬盤,比如我們用的分布式軟件系統,或者共享文件系統,這就是典型的遠程服務器硬盤。
3.2 內存文件存儲之tmpfs介紹
還有一種方式,像這樣存在本機內存,比如我們寫一個應用程序,這個應用程序要把數據存在本機內存,開發就很容易做到。
舉個例子,對于運維來說,我有一些數據訪問非常頻繁,但是我又沒法快速把它放在內存中,這時候怎么辦?其實linux系統給我們提供了一個文件系統,可以把我們數據直接放在內存中,就是tmpfs。
如果大家是老運維,你工作至少在七八年以上的運維,應該對這個比較熟悉,因為最早的時候基本都會用到tmpfs,tmpfs是怎么玩的呢?它是把數據直接放在共享內存中,它是特殊文件系統,我這里做了一個案例。
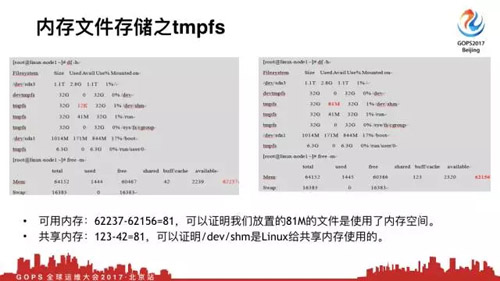
我們可以看到這個tmpfs,是系統默認的,是32G,使用率12k,這個時候我僅需放81兆文件,你會馬上發現dev/shm目錄就占用81兆,可用內存同62237變成62156,共享內存從42變成123。
這個時候做一個小學計算題,可用內存,說明我們放81兆文件是占用了內存空間的。然后共享內存,可以證明我們/dev/shm是Linux給共享內存用的,這就是典型的案例。
3.4 內存文件存儲之tmpfs使用方法

這個tmpfs怎么用呢?直接#就可以了,當然你還可以設置不同大小。用tmpfs有什么優勢呢?
- ***,存儲空間的設置和動態變化,放里面就增加,刪了就自動縮減。
- 第二,速度。天下武功,唯快不破,因為它是內存。
- 第三,沒有持久性,這是它的缺點也是優點。為什么是缺點呢?機器一重啟數據丟失了,為什么是優點呢?因為有些場景下機器重啟就要讓他丟失。
這就看你怎么用了,比如我把緩存數據放在這兒就會比較快,如果說你又想用它的優勢,又想保持持久性,方式也很多,只要每次數據可實時同步就可以解決。
另外我們做反向代理緩存,數據是要落盤的,這時候可以考慮使用tmpfs。還有session文件放在tmpfs,還有將socket文件放在tmpfs,還有其他需要高性能讀寫的場景。
3.5 內存文件存儲之tmpfs優勢對比

為什么講這個呢?因為我們之前有一個案例就使用到tmpfs,是電商有一次做活動,我們內部剛好有一個需求,需要一個性能讀寫的場景,要不停地寫,不停地讀,這個時候我們考慮了非常多其他的方案,發現I/O就是扛不住,這時候就想起了tmpfs,直接就可以用。這是講Cache的存儲位置就帶出了tmpfs。
3.6 Cache的幾個重要指標
這里有一個面試題,我們手機常用的一個功能,云備份,可以備份你的圖片和短信到云端,這樣的功能是否需要CDN加速,為什么?我的手機短信備份到云上,換一個手機再下載下來,這樣的需求需要使用CDN加速嗎?其實答案非常明確,不需要。當然有別的疑惑一會兒再說,我只是說云備份的場景是不需要的,為什么?

這就涉及到緩存幾個重要的特性。緩存的***率,所有緩存如果沒有***率,只會加慢整個流程,為什么?
因為我們加緩存相當于數據訪問和讀取加了一層路徑,這個路徑如果沒有發揮作用就會變慢,所以緩存***率是緩存非常重要的指標,就可以解釋為什么說這樣的需求不需要CDN加速,原因是因為沒有***率。
我的圖片、短信只有我自己能訪問到,我同步到云端,換手機的時候,只有我自己才下,緩存***率是0%,當然是不需要CDN加速的。
但是還有一種場景可能會需要,就是云盤。但云盤有兩種不同場景,我們現在用的把數據同步到云盤上,這個是不是需要CDN加速呢?不一定,一般這種云盤都非常智能的,它在下載的時候會判斷你這個資源的熱度。
具體怎么做,因為我沒有干過不知道,但是我們有類似相關系統,給資源熱度打分。比如說當資源熱度很高的時候,這個時候說明下載的人比較多,這個時候可以考慮放在CDN上。
但是存儲的時候還有很多的比如驗證,可能就不會上傳等等很多存儲功能,今天主要是緩存為主,講讀緩存。這個時候有可能需要CDN加速,但是云備份場景是不需要的。這就是說我們掌握問題要掌握知識的最根本的地方,這個時候不管我們做什么,你會發現所有問題都會迎刃而解。
4、關于客戶端的優化
4.1瀏覽器與DNS緩存
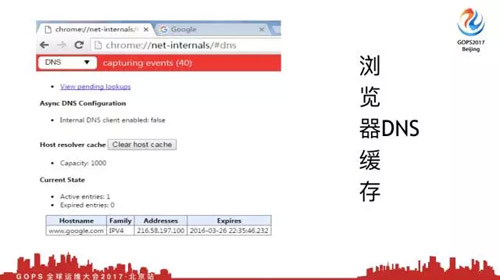
當我們發出一個Http請求,***步要做DNS解析。這是一個谷歌瀏覽器的截圖,這就是DNS緩存保存的地方。可以看到我訪問谷歌,我訪問的時間剛好是1分鐘60秒,下面這是瀏覽器DNS緩存。
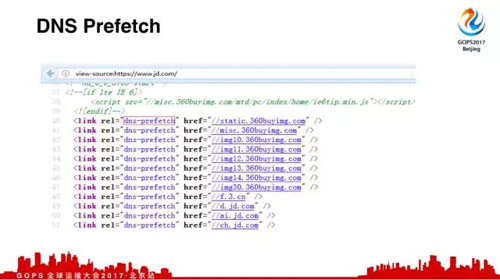
現在像HTML5有一個新特性,叫做DNS運貨區,這是京東首頁,可以看到很多的鏈接,什么意思呢?一個頁面組件最多的是圖片等等東西。我先講一個前置條件,Http協議我們通常稱為流式的,為什么?
因為我是邊下載邊渲染,一個瀏覽器首先會請求Web服務器,拿到整個HTML頁面,瀏覽器會從上往下挨行讀,每讀到一個行,瀏覽器會提一個新的線程下載新的頁面組件資源,下載完成就直接渲染出來了。
為什么我們打開網頁會慢
問題一、當遇到阻塞的時候網頁打開慢
當遇到什么情況下會阻塞?當遇到加載JS會阻塞,你會看到一個頁面一直在轉圈,JS阻塞,因為JS有可能會修改頁面的道路數,所以加載JS的時候要等JS下載完畢,并執行完畢,才能繼續往下加載。
所以我們經常做Web優化的時候,我們會把CSS放在頁面頂端,把JS在頁面放在底部,因為JS下載會阻塞。
問題二、為什么一個文件有多個域名
第二個問題,你會懷疑京東一個圖片為什么值得上10—30這么多個域名呢?是因為瀏覽器訪問一個Web站點,瀏覽器是有并發限制的,不可能單進程跑,像火狐這種一般不同版本可能6—8個并發,但是并發是針對的域名,所以他搞了很多域名,這樣就可以讓頁面打開更快。
但是域名多了就會產生另外一個問題,DNS解析就多了,這時候怎么辦呢?HTML5有一個新特性叫做DNS運貨區,我可以把先把DNS解析獲取一遍,等你下面用的時候直接用就可以了,不用再解析了。
這些手段其實都是來加快前端優化的手段,當然還有很多,比如減少頁面組件,頁面組件少了當然打開就快了。或者合并請求,比如咱們做運維,做淘寶的,就支持做組件合并,比如把某些小的CSS、JS合并起來發送,這樣就會更快。
如何優化
當然還有CSS背景偏移,很多小圖標,我其實只是一個圖片,我下載下來再通過背景偏移技術,再把它展示在頁面上。還有比如懶加載,為了加快首屏時間,我使用懶加載。我先把首屏需要的資源加載下來,鼠標往下拖的時候再一點點加載,這些手段都是加快首屏時間或者Web頁面打開的時間。
當然DNS緩存還有很多其他的,除了瀏覽器DNS緩存,剩下的就是系統文件。系統DNS緩存,到localDNS,localDNS也是集群,有緩存,所以每一級都是DNS緩存。
很多時候我們對于一些比如你要改某一個DNS的A記錄,我們會怎么做呢?我會提前把A記錄TTL生存周期時間改得很短,這樣我改A記錄的時候就會很快,當然大家做運維會知道,中國有很多小的運營商耍流氓,把DNS緩存設了很長,我還見過設好幾天的,所以改完以后在一些小的地方就是不生效。
DNS解析完畢,解析成公網IP地址,瀏覽器就會往公網IP地址發起請求。當然中間涉及到網絡傳輸,一個request的網絡傳輸,一個數據的網絡傳輸,這個時候就涉及到Http緩存線上,一個客戶端和server端要對話就是通過Http對話。
我發一個request告訴你服務器能不能使用本地緩存,緩存有沒有過期,服務器告訴他你可以使用本地緩存。
4.2關于瀏覽器緩存

瀏覽器緩存協商有三種方式,首先我們看瀏覽器緩存在什么地方,上圖是火狐瀏覽器,火狐放在內存和磁盤。有的時候火狐瀏覽器大家發現會打開比較慢,加載緩存,內存里有很多這樣的數據。
4.2.1 基于Last-Modifiedh緩存協議
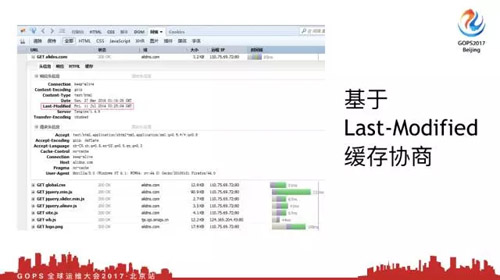
我們看***種緩存協商方式,基于***修改時間的緩存協商,我們都知道默認情況下,所有的系統都會有三個時間。
我們有一個***修改時間,那我們所有的Web瀏覽器都很聰明,默認情況下都會通過SDNT系統調用,可以獲取到靜態文件***修改時間。當你請求一個靜態頁面的時候,瀏覽器默認會返回給你這個頁面***修改時間是什么。
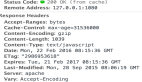
***次請求會發現都是200,我們看一下request頭部,請求頭,響應頭,在響應頭里可以看到***修改時間是2016年,這就是我的文件修改時間,瀏覽器默認會把這個時間帶上。
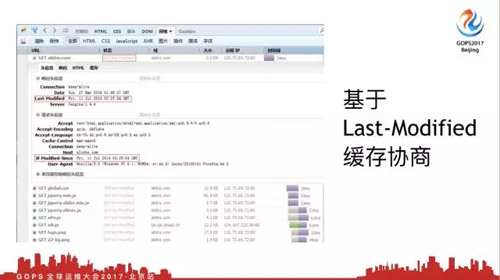
現在我點擊刷新按鈕,你會發現Web服務器返回了304,這就是基于***修改時間的緩存協商。這個時候請求頭請求的時候怎么請求呢?
它會問瀏覽器,你告訴我這個頁面保存修改時間是這個,你告訴我有沒有改,瀏覽器就告訴它,兄弟這個頁面沒有改過,你直接使用本地緩存就可以。這個時候我們Web服務器不會發數據給瀏覽器,瀏覽器直接使用本地緩存就可以了。
但是你說動態的行不行,行,為什么?你偽造一個Http頭部是可以的。所以為什么講這個,不是說搞笑說段子。你要明白客戶端、瀏覽器通過什么溝通,就是通過Http協議,只要你返回的時候返回一個頭部有***修改時間,就能實現這個功能,只不過這是瀏覽器一個默認的行為。
4.2.2 基于Etag緩存協議
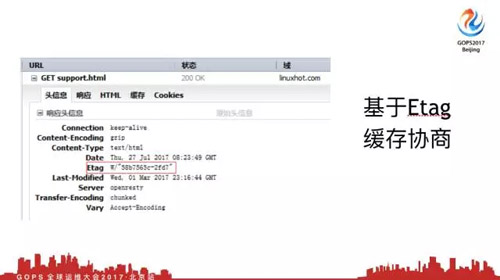
第二種緩存協商方式打標簽,一個頁面頻繁在***修改時間變動,但是內容沒有變,我的頁面是每次重新生成的,但是頁面內容并沒有變。如果基于***修改時間,這個緩存就失效了,這時候就通過打標簽方式,通過不同算法給頁面算一個值,然后發給瀏覽器。
每次你問我這個值有沒有發生改變,但這個算法每個瀏覽器都不一樣,如果你不好理解,可以理解為做了HTML5給客戶端,每次拿HTML5來問我對不對,但是它其實不是做HTML5加密出來的。
上面兩種緩存協商都有一個問題,因為要發起協商,我發給你,你再發給我,雖然沒有發生任何數據的產生,但是至少我返回了一個數據,證明你要給我建一個TCP三次握手和建立Http,這會占用我的資源。
4.2.3 基于Expires緩存協商cedilla消滅連接

第三次緩存協商就是基于過期時間,這個是針對運維的,對于開發知道就行了。那么客戶端和服務器時間不同步怎么辦?其實瀏覽器很聰明,它還有一個Cache—Control,它會算一個本地頭部時間,告訴你文件生存周期多久,不管你客戶端時間對不對,你都能正確使用過期時間。
4.3 你真的會刷新嗎?

如果有了這些緩存,我們就來看一下到底會不會使用瀏覽器刷新。比如火狐瀏覽器有一個刷新按鈕,你按刷新按鈕的時候,這個時候對于基于***修改時間和打標簽的方式就會受影響。
但是基于過期時間是不受影響的,所以說很多時候我只要設了一年過期,你狂點F5是沒有用的。那么怎么辦呢?強制刷新,ctrl+F5強制刷新,瀏覽器這時候就會發起一個全新的請求,不會使用任何緩存,所以我之前看到很多前端開發人員不會使用刷新,我覺得好尷尬,點了半天不起作用。跑過來問運維,運維說你怎么刷新的,F5,F5不行,要ctrl+F5。
這就延伸出另外一個問題,比如我給某個資源設過期時間一年,但是不到一年我想改怎么辦,你總不能讓我通知幾千萬用戶按一下ctrl+F5吧。有幾種方式,***是直接修改文件名,第二是使用時間戳。
當然這個時候如果還用到CDN的時候,就要注意了,我們做CDN配置的時候有兩種,一種是URL帶時間戳,一種是不帶時間戳,URL做緩存的時候不帶時間戳,那你就只能改名了,要不然你還要在CDN做強制刷新,當然也可以,不是說不可以。你做一個小系統,你直接調CDN做緩存刷新也是可以的,就比較費勁了,這個就看需求。
5、關于工作中的一些感悟
我看大家在座的都工作時間比較久,大家可以想工作時間早和工作時間久回答問題發生什么變化。我剛工作的時候別人問我問題我馬上回答,我直接回答說這樣是對的,等工作時間久了別人問我問題我會回答不一定,無論什么問題回答都是不一定。
為什么?要看你的需求,不同需求我的回答就是不一樣的。所以后來別人說班長問什么你都不一定,我說是的,你以前學技術的時候,你只需要做到這個就可以了,當你知道多的時候就會發現就是不一定。我們為開始學的時候搞一個負載均衡,我覺得這就是集群。后來所有東西都是不一定,一定要看你的需求。
更有甚者在群里問,班長支撐千萬PV是什么架構?“不一定”。這就很難說了,這一定要看需求的,你說一個小型網站,就一個Http頁面,支持幾十億PV都沒有問題。所以要看你的業務類型,如果說電商那就復雜了,電商的體系體量整個業務就很復雜,所以不同業務,不同架構就是不一樣的。
這里延伸出另外一個問題,大家現在工作不好干,為什么不好干?不管你是做開發還是做運維,現在互聯網發展都開始有場景化,你之前是做電商的,不管是開發還是運維,你跳一家游戲公司,想薪資翻倍不可能,因為你的經驗復制不過去。
你之前是做支付接口開發的,現在跳到Web商城,沒有支付是完全不同的。咱們做運維也是一樣的,所以咱們要不停學習,如果不學習只能慢慢被淘汰。