微軟發布學術版分布式計算技術Dryad和DryadLINQ
Dryad和DryadLINQ是微軟硅谷研究院創建的研究項目,旨在提供一個分布式計算平臺,近年來這個平臺已經在微軟內部得以廣泛使用(如微軟AdCenter中的數據分析)。在近日舉行的微軟2009年研究院教員峰會上,微軟發布了Dryad/DryadLINQ的學術版,以及Trident項目(一個基于Dryad/DryadLINQ及微軟其他一些技術的科研工作流平臺)的CTP版本。
Dryad是微軟分布式并行計算基礎平臺,使程序員可以利用數據中心的服務器集群對數據進行并行處理。Dryad程序員在操作數千臺機器時,無需關心并行處理的細節。據Dryad論文描述:
Dryad被設計為伸縮于各種規模的計算平臺:從單臺多核計算機、到由幾臺計算機組成的小型集群,直至擁有數千臺計算機的數據中心。Dryad執行引擎負責處理大型分布式、并行應用程序中會出現的各種難題:對計算機和它們的CPU進行調度,從通信或計算機的失敗中恢復,以及數據在節點之間的傳遞等等。
DryadLINQ的目標是提供一種高級語言接口,使普通程序員可以輕易進行大規模的分布式計算,它結合了微軟Dryad和LINQ兩種關鍵技術。
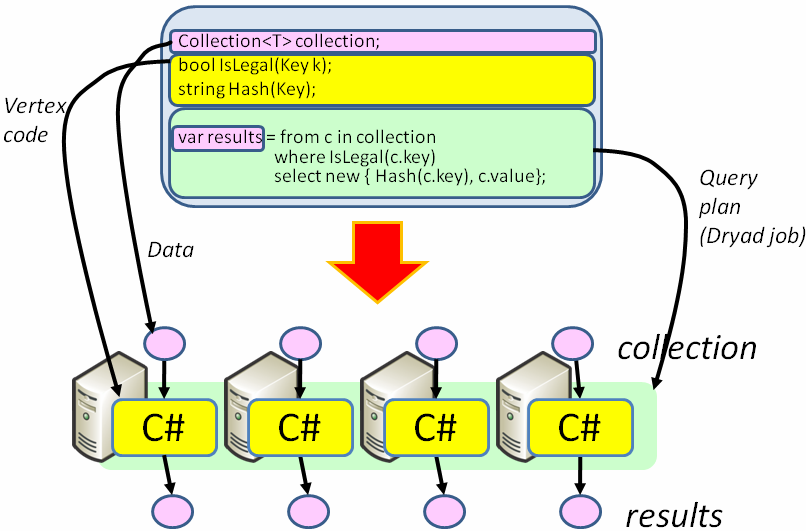
LINQ的理念為“代碼即數據(treat code as data)”。如上圖所示,DryadLINQ可以根據程序員給出的LINQ查詢生成可以在Dryad引擎上執行的分布式運算規則,并負責任務的自動并行處理及數據傳遞時所需要的序列化等操作。此外,它還提供了一系列易于使用的高級特性,如強類型數據,Visual Studio集成調試,以及豐富的任務優化規則等等。以下是使用DryadLINQ獲取一個柱狀圖所需數據的方式(引用自微軟發布的示例代碼):
- static IQueryable<Pair> Histogram(IQueryable<string> input, int k)
- {
- IQueryable<string> words = input.SelectMany(x => x.Split(' '));
- IQueryable<IGrouping<string, string>> groups = words.GroupBy(x => x);
- IQueryable<Pair> counts = groups.Select(x => new Pair(x.Key, x.Count()));
- IQueryable<Pair> ordered = counts.OrderByDescending(x => x.count);
- IQueryable<Pair> top = ordered.Take(k);
- return top;
- }
談到大規模分布式計算技術,便不得不提起著名的Google MapReduce。據DryadLINQ論文(該論文獲得OSDI 08最佳論文獎)所述,DryadLINQ與MapReduce的區別在于:
MapReduce同樣提供了能夠快速進行編程的簡化抽象,但是,使用這種編程模型來實現一些最常見的操作,如數據庫Join都要使用較為有技巧(tricky)的做法。還有,我們經常需要把MapReduce計算嵌入一種腳本語言來實現多次歸并或排序操作。每個MapReduce階段(stage)都是自治的(self-contained),因此無法跨越邊界進行優化。此外,缺少類型系統來連接不同的MapReduce階段,迫使程序員必須顯式跟蹤階段間傳遞的對象,這導致軟件長期維護以及組件的復用變得麻煩。
因此,出現了一些構建于MapReduce抽象上的DSL為程序員隱藏了一些復雜性,如Sawzall、Pig、以及其他一些未發表的系統,如Facebook的HIVE。這些DSL簡單地結合了聲明式與命令式的編程方式,并生成類似SQL存儲過程的模型,這樣便可以對跨越MapReduce階段的邊界進行一些整體的自動優化。然而,這些做法也帶來了一些SQL的缺點,如過于簡單的自定義類型系統,以及有限的交互式計算能力。它們提供的優化不如DryadLINQ來的有效,一部分原因在于Dryad比MapReduce執行平臺的靈活性要高的多。
此外,微軟發布的Trident項目是一個科學工作流控制臺,為科學家們提供了一個靈活而強大的方式,可以對大規模的,變化紛繁的數據集進行分析。它提供了可視化工具來創建、管理和分享工作流,并且可以在Windows HPC Server 2008集群上執行這些工作流。Trident基于Dryad/DryadLINQ和WF開發,并提供了WPF和Siverlight兩種版本的可視化界面。開發人員還可以擴展Trident,并與Word,SQL Server,Data Service等多種技術進行集成,使Trident的適用范圍更為廣泛。
【編輯推薦】