













淺談C#匹配字符串
C#匹配字符串
大多數重要的正則表達式語言運算符都是非轉義的單個字符。轉義符 \(單個反斜杠)通知正則表達式分析器反斜杠后面的字符不是運算符。例如,分析器將星號 (*) 視為重復限定符,而將后跟星號的反斜杠 (\*) 視為 Unicode 字符 002A。
使用一般表達式要習慣的一點是,查看像這樣怪異的字符序列,但這個序列的工作是非常邏輯化的。轉義序列\S表示任何不適空白的字符。*稱為數量詞,其含義是前面的字符可以重復任意次,包括0次。序列\S*表示任何不適空白的字符。因此,上面的模式匹配于以n開頭,以ion結尾的任何單個字。下表中列出的字符轉義在正則表達式和替換模式中都會被識別。
表1:特定字符或轉義序列
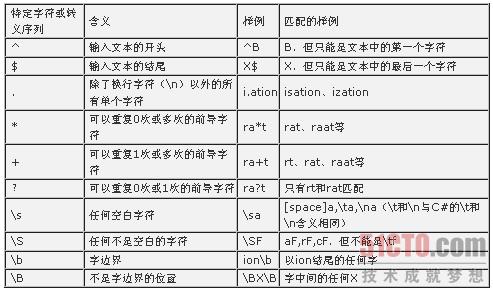
如果要搜索一個元字符,也可以通過帶有反斜杠的轉義字符來表示。例如,.表示除了換行字符以外的任何字符,而\.表示一個點。
可以把可替換的字符放在方括號中,請求匹配包含這些字符。例如,[1|c]表示字符可以是1或者是c。如果要搜索map或者man,可以使用序列"ma[n|p]"(僅指引號內字符,下面雷同)。在方括號中,也可以制定一個范圍,例如"[a-z]"表示所有的小寫字母(使用連字號 (-) 允許指定連續字符范圍),"[B-F]"表示B到F之間的所有大寫字母,"[0-9]"表示一個數字,如果要搜索一個整數(該序列只包含0到9的字符),就可以編寫"[0-9]+"(注意,使用+字符表示至少要有這樣一個數字,但可以有多個數字,所以9、83和3443等都是匹配的。)
下面看看一般表達式的結果,編寫一個實例RegularExpressionsZzy。建立幾個一般表達式,顯示其結果,讓用戶了解一下表達式是如何工作的。
該實例的核心是一個方法WriteMatches(),它把MatchCollection中的所有匹配以比較詳細的方式顯示出來。對于每個匹配,它都會顯示該匹配在輸入字符串中所在的索引,C#匹配字符串和一個略長的字符串,其中包含輸入文本中至多8個外圍字符,其中至少有5個字符放在匹配的前面,至多5個字符放在匹配的后面(如果匹配的位置在輸入文本的開頭或結尾5個字符內,則結果中匹配前后的字符就會少于4個)。換言之,靠近輸入文本末尾的匹配應是"and messaging ofd",匹配的前后各有5個字符,但位于輸入文本的***一個字上的匹配就應是"g of data",匹配的字后只有一個字符。因為在該字符的后面是字符串的結尾。這個長字符串可以更清楚地表明一般表達式是在什么地方查找到匹配的:
- staticvoidWriteMatches(stringtext,MatchCollectionmatches)
- {
- Console.WriteLine("Originaltextwas:\n\n"+text+"\n");
- Console.WriteLine("No.ofmatches:"+matches.Count);
- foreach(MatchnextMatchinmatches)
- {
- intIndex=nextMatch.Index;
- stringresult=nextMatch.ToString();
- intcharsBefore=(Index<5)?Index:5;
- intfromEnd=text.Length-Index-result.Length;
- intcharsAfter=(fromEnd<5)?fromEnd:5;
- intcharsToDisplay=charsBefore+charsAfter+result.Length;
- Console.WriteLine("Index:{0},\tString:{1},\t{2}",Index,result,
- text.Substring(Index-charsBefore,charsToDisplay));
- }
- }
在這個方法中,處理過程是確定在較長的字符串中有多少個字符可以顯示,而無需超限輸入文本的開頭或結尾。注意在Match對象上使用了另一個屬性Value,它包含標識該C#匹配字符串,而且,RegularExpressionsZzy只包含名為Find_po,Find_n等的方法,這些方法根據本文執行某些搜索操作。
【編輯推薦】










