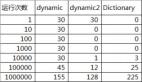
對比C#中for和foreach循環的性能
筆者在看了《Effective C#》了解到foreach循環,使用foreach循環語句,它會編譯為不同的代碼,自動將每一個操作數強制轉換為正確的類型。
大家先來看看如下三個循環:
- int[] foo = new int[100];
- 1, foreach (int i in foo)
- Console.WriteLine(i.ToString());
- 2,for(int index=0;index Console.WriteLine(foo[index].ToString());
- 3,int len=foo.Length;
- for(int index=0;index Console.WriteLine(foo[index].ToString());
這三個循環是我在看《Effective C#》中看到的,發現書中說第三個循環和如下代碼等效,經過使用ILDasm.exe工具查看IL代碼發現這個說法并不正確:
- int len=foo.Length;
- for(int index=0;index
- {
- if(index
- Console.WriteLine(foo[index].ToString());
- else
- throw new IndexOutOfRangeException();
- }
書中的看法是數組的邊界測試會被執行兩次(編譯器生成的代碼一次,JIT編譯階段還要執行一次檢查),但是的確沒有在IL代碼中發現C#的編譯器生成類似的邏輯,所以這個說法有問題!
一般C++轉過來的程序員都很喜歡這樣寫循環,認為這樣就不會每一次循環都計算一次Length屬性的值了,可以帶來性能上的提升!經查看IL代碼,實際情況也就是如此!
但是,這樣寫會帶來另外的問題,那就是破壞了JIT對代碼的進行的優化,這樣的寫法在每一次循環中都要做數組的邊界檢查,這樣也帶來了性能上的損失,而且這個損失要比每次計算Length要大,如果我們按第二種寫法,JIT只在第一次循環之前檢查一次數組界限(JIT這種優化只針對f循環中訪問一維0基數組,并且索引是0和Length之間的元素)
看來JIT不喜歡我們這樣幫助他優化代碼,這樣反而破壞了JIT本身的優化!
我們再來看看第一種寫法和第二種寫法,通過查看IL代碼,他們生成的代碼比較類似,差別是使用foreach循環是把數組元素放到i變量里!
C#編譯器對第一種寫法(使用foreach循環)針對數組做了特殊的處理,并沒有像其他集合那樣在內部使用迭代器,這里如果使用迭代器的話會導致裝箱和拆箱操作,這樣會帶來性能上的損失!看來C#編譯器總是可以為foreach生成很高效率的代碼,而且可以帶來很多其他的好處,例如簡化代碼的編寫,或是將來把foo變成其他集合 而foreach循環不必修改(使用for循環必須修改代碼),操作數強制類型轉換等.
【編輯推薦】