Hadoop優點及其結構示意圖詳解
本節和大家一起學習一下Hadoop方面的知識,本節主要內容有Hadoop概念介紹,Hadoop結構示意圖和Hadoop的優點及使用場景,歡迎大家一起來學習Hadoop。首先看一下Hadoop的概念。
Hadoop概念
Hadoop是一個分布式系統基礎架構,由Apache基金會開發。用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力高速運算和存儲。
簡單地說來,Hadoop是一個可以更容易開發和運行處理大規模數據的軟件平臺。
Hadoop實現了一個分布式文件系統(HadoopDistributedFileSystem),簡稱HDFS。HDFS有著高容錯性(fault-tolerent)的特點,并且設計用來部署在低廉的(low-cost)硬件上。而且它提供高傳輸率(highthroughput)來訪問應用程序的數據,適合那些有著超大數據集(largedataset)的應用程序。HDFS放寬了(relax)POSIX的要求(requirements)這樣可以流的形式訪問(streamingaccess)文件系統中的數據。
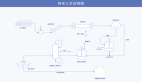
Hadoop結構示意圖
在Hadoop的系統中,會有一臺Master,主要負責NameNode的工作以及JobTracker的工作。JobTracker的主要職責就是啟動、跟蹤和調度各個Slave的任務執行。還會有多臺Slave,每一臺Slave通常具有DataNode的功能并負責TaskTracker的工作。TaskTracker根據應用要求來結合本地數據執行Map任務以及Reduce任務。
說到這里,就要提到分布式計算最重要的一個設計點:MovingComputationisCheaperthanMovingData。就是在分布式處理中,移動數據的代價總是高于轉移計算的代價。簡單來說就是分而治之的工作,需要將數據也分而存儲,本地任務處理本地數據然后歸總,這樣才會保證分布式計算的高效性。
為什么要選擇Hadoop?
說完了What,簡單地說一下Why。官方網站已經給了很多的說明,這里就大致說一下其優點及使用的場景(沒有不好的工具,只用不適用的工具,因此選擇好場景才能夠真正發揮分布式計算的作用):
可擴展:不論是存儲的可擴展還是計算的可擴展都是Hadoop的設計根本。
經濟:框架可以運行在任何普通的PC上。
可靠:分布式文件系統的備份恢復機制以及MapReduce的任務監控保證了分布式處理的可靠性。
高效:分布式文件系統的高效數據交互實現以及MapReduce結合LocalData處理的模式,為高效處理海量的信息作了基礎準備。
使用場景:個人覺得最適合的就是海量數據的分析,其實Google最早提出MapReduce也就是為了海量數據分析。同時HDFS最早是為了搜索引擎實現而開發的,后來才被用于分布式計算框架中。海量數據被分割于多個節點,然后由每一個節點并行計算,將得出的結果歸并到輸出。同時***階段的輸出又可以作為下一階段計算的輸入,因此可以想象到一個樹狀結構的分布式計算圖,在不同階段都有不同產出,同時并行和串行結合的計算也可以很好地在分布式集群的資源下得以高效的處理。本節關于Hadoop的介紹完畢,請關注本節其他相關報道。
【編輯推薦】