實(shí)現(xiàn)Hadoop集群性能優(yōu)化,Hadoop機(jī)架感知如何配置?
本節(jié)和大家一起學(xué)習(xí)一下Hadoop集群方面的內(nèi)容,主要介紹一下Hadoop集群網(wǎng)絡(luò)性能優(yōu)化的背景,及Hadoop配置等,歡迎大家一起來學(xué)習(xí)有關(guān)Hadoop集群方面的知識。
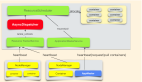
Hadoop集群網(wǎng)絡(luò)性能優(yōu)化:Hadoop機(jī)架感知實(shí)現(xiàn)及配置
背景
分布式的集群通常包含非常多的機(jī)器,由于受到機(jī)架槽位和交換機(jī)網(wǎng)口的限制,通常大型的分布式集群都會跨好幾個機(jī)架,由多個機(jī)架上的機(jī)器共同組成一個分布式集群。機(jī)架內(nèi)的機(jī)器之間的網(wǎng)絡(luò)速度通常都會高于跨機(jī)架機(jī)器之間的網(wǎng)絡(luò)速度,并且機(jī)架之間機(jī)器的網(wǎng)絡(luò)通信通常受到上層交換機(jī)間網(wǎng)絡(luò)帶寬的限制。
具體到Hadoop集群,由于Hadoop的HDFS對數(shù)據(jù)文件的分布式存放是按照分塊block存儲,每個block會有多個副本(默認(rèn)為3),并且為了數(shù)據(jù)的安全和高效,所以Hadoop默認(rèn)對3個副本的存放策略為:
在本地機(jī)器的hdfs目錄下存儲一個block
在另外一個rack的某個datanode上存儲一個block
在該機(jī)器的同一個rack下的某臺機(jī)器上存儲***一個block
這樣的策略可以保證對該block所屬文件的訪問能夠優(yōu)先在本rack下找到,如果整個rack發(fā)生了異常,也可以在另外的rack上找到該block的副本。這樣足夠的高效,并且同時做到了數(shù)據(jù)的容錯。
但是,Hadoop對機(jī)架的感知并非是自適應(yīng)的,亦即,Hadoop集群分辨某臺slave機(jī)器是屬于哪個rack并非是只能的感知的,而是需要Hadoop的管理者人為的告知Hadoop哪臺機(jī)器屬于哪個rack,這樣在Hadoop的namenode啟動初始化時,會將這些機(jī)器與rack的對應(yīng)信息保存在內(nèi)存中,用來作為對接下來所有的HDFS的寫塊操作分配datanode列表時(比如3個block對應(yīng)三臺datanode)的選擇datanode策略,做到Hadoopallocateblock的策略:盡量將三個副本分布到不同的rack。
接下來的問題就是:通過什么方式能夠告知Hadoopnamenode哪些slaves機(jī)器屬于哪個rack?以下是配置步驟。
配置
默認(rèn)情況下,Hadoop的機(jī)架感知是沒有被啟用的。所以,在通常情況下,Hadoop集群的HDFS在選機(jī)器的時候,是隨機(jī)選擇的,也就是說,很有可能在寫數(shù)據(jù)時,Hadoop將***塊數(shù)據(jù)block1寫到了rack1上,然后隨機(jī)的選擇下將block2寫入到了rack2下,此時兩個rack之間產(chǎn)生了數(shù)據(jù)傳輸?shù)牧髁浚俳酉聛恚陔S機(jī)的情況下,又將block3重新又寫回了rack1,此時,兩個rack之間又產(chǎn)生了一次數(shù)據(jù)流量。在job處理的數(shù)據(jù)量非常的大,或者往Hadoop推送的數(shù)據(jù)量非常大的時候,這種情況會造成rack之間的網(wǎng)絡(luò)流量成倍的上升,成為性能的瓶頸,進(jìn)而影響作業(yè)的性能以至于整個集群的服務(wù)。
要將Hadoop機(jī)架感知的功能啟用,配置非常簡單,在namenode所在機(jī)器的Hadoop-site.xml配置文件中配置一個選項(xiàng):
- <property>
- <name>topology.script.file.name</name>
- <value>/path/to/script</value>
- </property>
這個配置選項(xiàng)的value指定為一個可執(zhí)行程序,通常為一個腳本,該腳本接受一個參數(shù),輸出一個值。接受的參數(shù)通常為某臺datanode機(jī)器的ip地址,而輸出的值通常為該ip地址對應(yīng)的datanode所在的rack,例如”/rack1”。Namenode啟動時,會判斷該配置選項(xiàng)是否為空,如果非空,則表示已經(jīng)用機(jī)架感知的配置,此時namenode會根據(jù)配置尋找該腳本,并在接收到每一個datanode的heartbeat時,將該datanode的ip地址作為參數(shù)傳給該腳本運(yùn)行,并將得到的輸出作為該datanode所屬的機(jī)架,保存到內(nèi)存的一個map中。
至于腳本的編寫,就需要將真實(shí)的網(wǎng)絡(luò)拓樸和機(jī)架信息了解清楚后,通過該腳本能夠?qū)C(jī)器的ip地址正確的映射到相應(yīng)的機(jī)架上去。一個簡單的實(shí)現(xiàn)如下:
- #!/usr/bin/perl-w
- usestrict;
- my$ip=$ARGV[0];
- my$rack_num=3;
- my@ip_items=split/\./,$ip;
- my$ip_count=0;
- foreachmy$i(@ip_items){
- $ip_count+=$i;
- }
- my$rack="/rack".($ip_count%$rack_num);
- print"$rack";
請期待下節(jié)Hadoop集群網(wǎng)絡(luò)性能優(yōu)化。
【編輯推薦】
- 專家指導(dǎo) 如何實(shí)現(xiàn)Hadoop集群搭建
- Hadoop集群搭建過程中相關(guān)環(huán)境配置詳解
- Hadoop文件系統(tǒng)如何快速安裝?
- Hadoop集群搭建過程中相關(guān)環(huán)境配置詳解
- Hadoop完全分布模式安裝實(shí)現(xiàn)詳解