為什么要使用集合框架?
題序:很多時候,我們專心研究一個東西的時候,往往忘記了我們最初的目的是什么。
曾經研究過那么久的Java集合框架,為了搞清里面的細節,甚至都跑去重新買了一本數據結構,終于知道了線性表,知道了樹,知道了查找表。也自己動手實現了ArrayList,LinkedList,HashMap等。
今天在公交車上,突然想到“我們為什么要使用Java集合框架呢?”竟然一時語塞,半天想不起來,也說不出個所以然呢。頓時悲從中來啊。還是決定再次好好復習一把,現總結如下:
PS.還是那句老話,如果這些問題您都能輕松解答,沒必要再浪費時間看下去了。
Question one:我們為什么要使用集合框架?
Question two:關于ArrayList 和Vector (HashMap和HashTable)PS
Question three:總體把握,集合框架的繼承圖
Question four:set 于map的關系(見李興華書)
Question five:關于set(底層實現,關于TreeSet,關于排序,關于比較對象相等)
Question six: 已經存在了那么多的動態結構,為什么需要hash表?
Question seven:TreeMap 底層實現
Question One:我們為什么使用集合框架?
大家還記得我們為什么要使用數組嘛?
當我們需要保持一組一樣(類型相同)的元素的時候,我們應該使用一個容器來保存,數組就是這樣一個容器。
那么,數組的缺點是什么呢?
數組一旦定義,長度將不能再變化。
然而在我們的開發實踐中,經常需要保存一些變長的數據集合,于是,我們需要一些能夠動態增長長度的容器來保存我們的數據。
而我們需要對數據的保存的邏輯可能各種各樣,于是就有了各種各樣的數據結構。我們將數據結構在Java中實現,于是就有了我們的集合框架。
Question Two: List和Vector,HashMap和 HashTable 的區別在哪里呢?
前者都是在JDK1.2后推出的,在前者中,因為采用異步處理方式,性能更高。
(其實就是刪掉了后者中操作數據{add ,remove等}時的線程同步鎖,這樣,效率更高了,但是卻不再是線程安全的了,要線程安全,必須用戶在程序中使用時自己控制。)
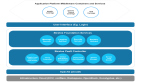
Question Three:集合框架繼承圖
本來想自己畫個簡圖的,結果悲催的Rational Rose一直在抽風,也沒時間去弄那個了。就網上Down了一個,暫且用著吧

從這個圖中,我們可以發現:Collection 接口包括List和Set兩個子接口(其實還有Queue和Sorted兩個子接口)
另外,也驗證了我們前面說的,Array和Collection都是用來保存數據的容器。
Question Four:Set 和 Map 有什么關系?
從Question Three的繼承圖中,我們很明顯的發現:Map雖然不像Set那樣屬 于 Collection,但是Set和Map的繼承圖是如此的相似。那么,他們之間到底有什么樣的 關系呢?
從邏輯上來說:首先,如果我們只考察Map中的key,那么顯然,這個key的集合就是一 個set:不能重復,無序。(Map中有keyset()的方法,能直接得到key的set)另外一 個層面,如果我們 將Map中的key何value當做一個整體,那么,顯然,這個時候 的Map其實就是一個Set(在Map的實現中,都是通過一個內部類來將key和value當做 一個整體entity),
從代碼角度本身角度來看,無論是HashSet還是TreeSet其實使用的都是對應 的Tree來實現的,我們用一個默認的Object,這樣就可以存了。
而事實上Set的底層實現中,我們也可以發現,都是用對應的Map來實現的,只是,在每次存key-value 對的時候,都默認給了一個Object 類作為Value的默認值,
Question five:關于set(底層實現,關于TreeSet,關于排序,關于比較對象相等)
我們知道,Set是無序的,同時又是不能重復的,那么,這種不能重復性,是如何保證的呢? 其實這個問題問的還是不到位,Question Four已經說了,底層是由Map實現的,那么都是由Map來實現的。
為了唯一性,重點是能識別相同的元素(如何判斷相等)
在Java中,=號,表示內存地址相等,即是指向堆內存的同一引用,那么此時,顯然兩個元素是相等的。
當不是指向堆內存的同一引用時。我們就需要重寫Object類的equals()方法了。在此,我們判斷,如果我們需要比較的各個屬性相等的話,那么則可認為這兩個對象相等(關于屬性相等的比較與此類似)
Question six: 已經存在了那么多的動態結構,為什么需要Hash表?
其實這個問題其實問的不恰當,應該是,有了諸如順序表和有序表這樣的靜態表,諸如二叉排序樹 平衡二叉樹這樣的動態表,為什么還需要Hash表呢?
因為記錄在表中的位置和它的關鍵字之間不存在一個確定的關系。查找的過程為給定值依次和關鍵字集合中各個關鍵字進行比較。查找的效率取決于和給定值進行比較的關鍵字個數。
Question Seven: TreeMap 底層實現
TreeMap 底層由紅黑樹(Red-Black tree)實現。因為此部分內容包括算法分析,具體代碼實現以及性能分析,內容比較多,所以本部分內容稍后專門用一個日志來推出。(形式類似HashMap那篇日志)
【編輯推薦】