













Java進行HTML數據采集:淺談強大的group正則
簡 介
作為全球運用最廣泛的語言,Java 憑借它的高效性,可移植性(跨平臺),代碼的健壯性以及可強大的可擴展性,深受廣大應用程序開發者的喜愛. 作為一門強大的開發語言,正則表達式在其中的應用當然是必不可少的,而且正則表達式的掌握能力也是那些高級程序員的開發功底之體現,做一名合格的網站開發的程序員(尤其是做前端開發),正則表達式是必備的。
最近,由于一些需要,用到了java和正則,做了個的足球網站的數據采集程序,由于是***次做關于java的html頁面數據采集,必然在網上查找了很多資料,但是發現運用如此廣泛的java在使用正則做html采集方面的(中文)文章是少之又少,都是簡單的談了下java正則的概念,沒有真正用在實際網頁html采集,所以實例教程更是***(雖然java有它自己的Html Parser,而且十分強大),但個人覺得作為如此深入人心的正則表達式,理應有其相關的java實例教程,而且應該很多很全.于是在完成java版的html數據采集程序之后,本人便打算寫個關于正則表達式在java上的html頁面采集,以便有相關興趣的讀者更好的學習。
關于group正則
說到正則表達式是如何幫助java進行html頁面采集,這里簡要需要提一下正則表達式中的group方法:
- public static void main(String[] args){
- //Pattern 用于編譯正則 這里用到了3個正則 分別用括號()包住
- //匹配URL 當然這里的正則不一定準確 這個匹配URL的正則就是錯誤的 只是在這里剛好能匹配出來
- //第2個正則是用于匹配標題 SoFlash的
- //第3個正則用于匹配日期
- /*這里只用了一條語句便把url,標題和日期全部給匹配出來了*/
- Pattern p = Pattern.compile("='(\\w.+)'>(\\w.+[a-zA-Z])-(\\d{1,2}\\.\\d{1,2}\\.\\d{4})");
- String s = "<a href='www.cnblogs.com/longwu'>SoFlash-12.22.2011</a>";
- Matcher m = p.matcher(s);
- while(m.find()){
- //通過調用group()方法里的索引 將url,標題和日期全部給打印出來
- System.out.println("打印出url鏈接:"+m.group(1));
- System.out.println("打印出標題:"+m.group(2));
- System.out.println("打印出日期:"+m.group(3));
- System.out.println();
- }
- System.out.println("group方法捕獲的數據個數:"+m.groupCount()+ "個");
- }
我們看下輸出結果:
打印出url鏈接:www.cnblogs.com/longwu
打印出標題:SoFlash
打印出日期:12.22.2011
group方法捕獲的數據個數:3個
想了解更多的朋友請看 JAVA 正則表達式 (超詳細)
如果之前沒有學過正則的可以看看這個 正則表達式的元字符匹配
好了 group方法介紹完了 我們來簡單的使用下 group采集某個足球網站頁面的數據
頁面鏈接:http://www.footballresults.org/league.php?all=1&league=EngPrem
首先我們讀取整個html頁面,并打印出來 代碼如下:
- public static void main(String[] args) {
- String strUrl = "http://www.footballresults.org/league.php?all=1&league=EngPrem";
- try {
- // 創建一個url對象來指向 該網站鏈接 括號里()裝載的是該網站鏈接的路徑
- // 更多可以看看 http://wenku.baidu.com/view/8186caf4f61fb7360b4c6547.html
- URL url = new URL(strUrl);
- // InputStreamReader 是一個輸入流讀取器 用于將讀取的字節轉換成字符
- // 更多可以看看 http://blog.sina.com.cn/s/blog_44a05959010004il.html
- InputStreamReader isr = new InputStreamReader(url.openStream(),
- "utf-8"); // 統一使用utf-8 編碼模式
- // 使用 BufferedReader 來讀取 InputStreamReader 轉換成的字符
- BufferedReader br = new BufferedReader(isr);
- // 如果 BufferedReader 讀到的內容不為空
- while (br.readLine() != null) {
- // 則打印出來 這里打印出來的結果 應該是整個網站的
- System.out.println(br.readLine());
- }
- br.close(); // 讀取完成后關閉讀取器
- } catch (IOException e) {
- // 如果出錯 拋出異常
- e.printStackTrace();
- }
- }
打印出來的結果 是整個html頁面的源代碼 (部分截圖如下)
到這里,數據已經成功采集下來了,當然 我們想要的并不是整個html源代碼,我們需要的是網頁上的比賽數據。
首先 我們分析下 html源代碼結構 來到http://www.footballresults.org/league.php?all=1&league=EngPrem 頁面
右鍵該頁面 點擊 ‘查看源文件’ 如圖:
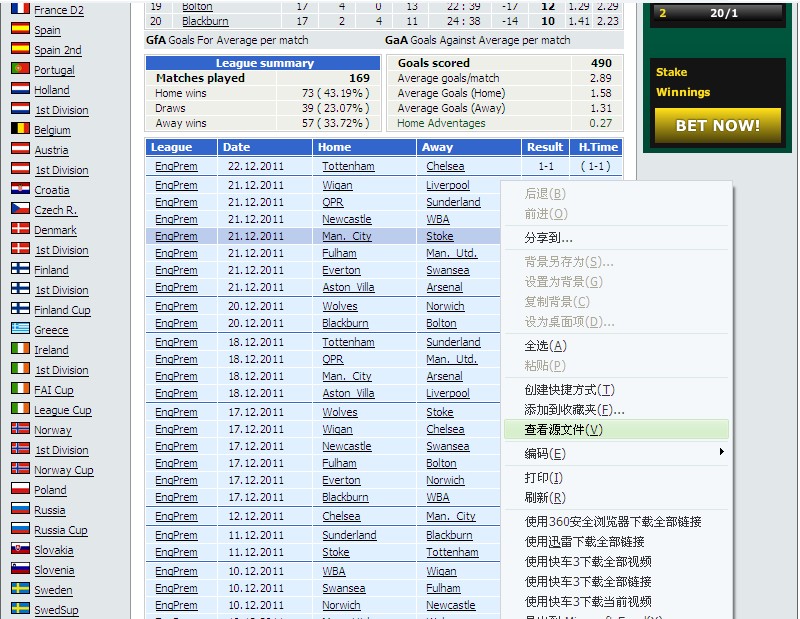
我們來看看 其內部的html代碼結構 以及我們需要的數據
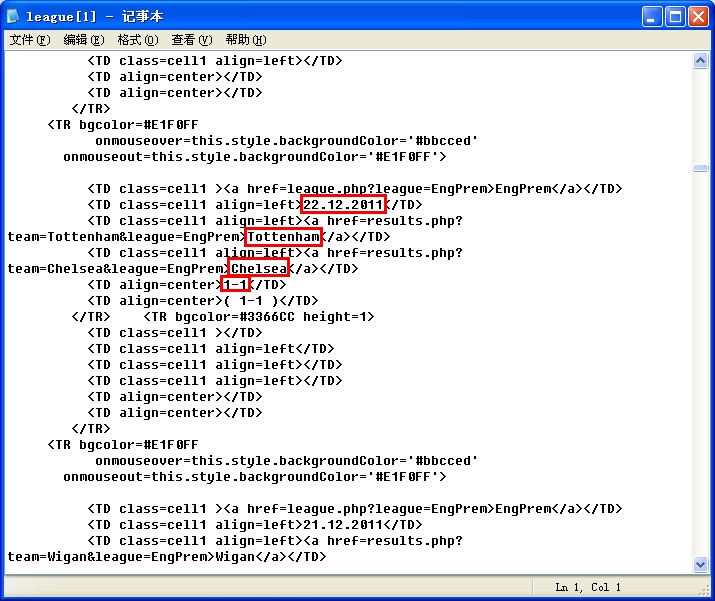
其對應的頁面數據
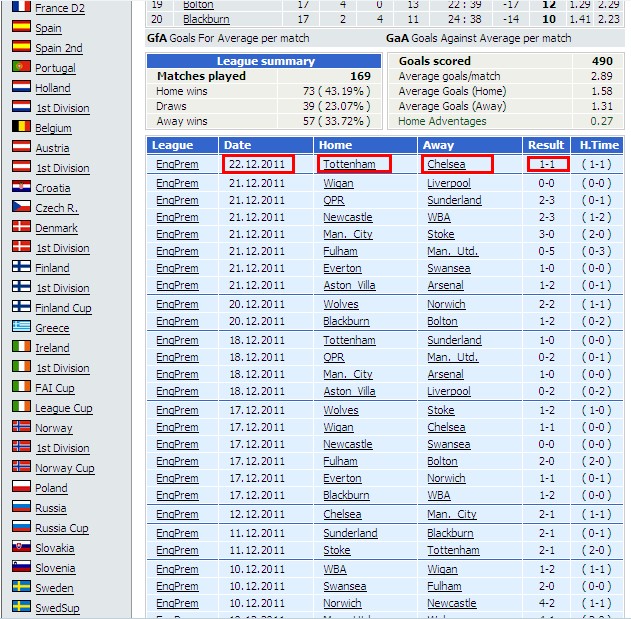
這時候,強大的正則表達式派上用場了, 我們需要寫幾個用來匹配我們需要數據的正則
這里需要用到 3個正則 包括 日期, 2個球隊的(主隊和客隊) 以及比賽結果的 如下
- String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})"; //日期正則
- String regularTwoTeam = ">[^<>][^<>]*</a>"; //球隊正則
- String regularResult = ">(\\d{1,2}-\\d{1,2})</TD>"; //比賽結果正則
寫好正則 我們便可以使用該正則來獲取 我們想要得到的數據了
首先 我們寫一個GroupMethod類 用于存放regularGroup()方法
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class GroupMethod {
- // 傳入2個字符串參數 一個是pattern(我們使用的正則) 另一個matcher是html源代碼
- public String regularGroup(String pattern, String matcher) {
- Pattern p = Pattern.compile(pattern, Pattern.CASE_INSENSITIVE);
- Matcher m = p.matcher(matcher);
- if (m.find()) { // 如果讀到
- return m.group();// 返回捕獲的數據
- } else {
- return ""; // 否則返回一個空值
- }
- }
- }
然后是寫主函數代碼
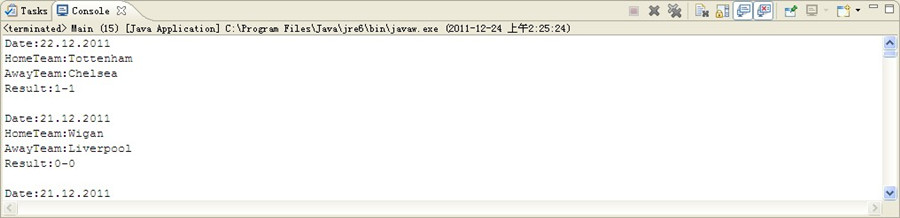
對比下 html上的數據 (部分截圖-初始階段)
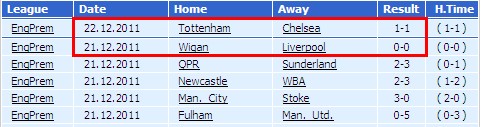
輸出結果(部分截圖-結束階段)
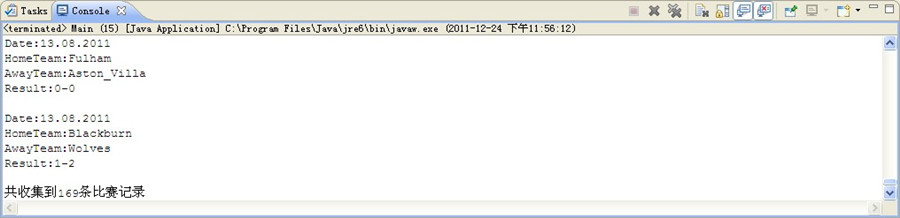
對比下 html上的數據 (部分截圖-結束階段)
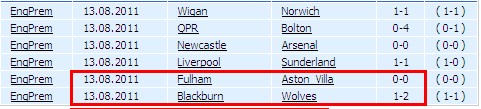
好了 這樣的html數據采集就完成了 :)
當然這里只是抓取了一個頁面的內容如果感興趣,想抓去更多的頁面內容,你可以分析下該鏈接后的聯盟名。例如 league=EngPrem 通過改變league名來獲取所有聯盟的比賽數據你可以寫個接口把所有球隊的名字放進去,當然還有更智能的方法你可以寫個方法,從http://www.footballresults.org/allleagues.php 頁面獲取所有球隊的名字 然后來附加到 "http://www.footballresults.org/league.php?all=1&league=" 鏈接后面 來補齊鏈接 循環讀取各個聯盟比賽頁面的內容。
原文鏈接:http://www.cnblogs.com/longwu/archive/2011/12/24/2300110.html
【編輯推薦】













