Facebook分享:解決Hadoop的單一故障點
譯文【51CTO快譯】Facebook的工程師們開發出了一種方法,以規避Hadoop數據分析平臺的一個根本缺點:只依賴單單一臺名稱服務器來協調所有運營。
在本周于加利福尼亞州圣何塞召開的Hadoop峰會上,Facebook工程師Andrew Ryan討論了這種變通方法。他還在Facebook上發布了其演講的摘要內容。
Facebook擁有可能是世界上規模最龐大的基于Hadoop分布式文件系統(HDFS)的數據集,總共超過100PB,散布于其諸數據中心的100個不同的集群之間。
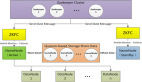
盡管Hadoop越來越經常用于大規模數據分析任務,但是用專業的話來說,它存在單一故障點。雖然部署的Hadoop系統可能橫跨數百臺、乃至數千服務器,但是整個運營依賴一臺叫做名稱節點(namenode)的單一服務器,負責協調諸數據節點之間的所有流量。要是這一個名稱節點停止運行,那么諸數據節點就無法通信,整個系統將停止運行。
Facebook估計,如果可以克服這個缺點,就能將其數據倉庫的停機時間縮短幾乎一半。
為了解決這個問題,Facebook開發出了一款名為Avatarnode的軟件:萬一主名稱節點由于某種原因而失效,該軟件就會切換至備用名稱節點。在這種架構中,每個數據節點會向主名稱節點和備用名稱節點定期發送***數據。萬一主名稱節點停止運行,那么備用名稱節點就會頂上來,繼續運行。這款軟件以詹姆斯•卡梅隆執導的影片《阿凡達》命名,它依賴Hadoop Zookeeper配置管理工具。
這家公司將阿凡達節點作為一款開源軟件來提供,希望Hadoop管理員們能夠得益于使用該軟件。Facebook早在2010年發布了該軟件,后來被用于處理該公司的生產任務。
Ryan寫道:“如今,阿凡達節點在運行我們Facebook內部要求***的生產工作負載,它會繼續大幅提升HDFS集群的可靠性和可管理性。展望未來,我們會努力進一步改進阿凡達節點,并且將它與一種可以自動安全地進行故障切換的通用高可用性框架集成起來。”
不止Facebook這一家公司在試圖解決Hadoop存在的這個問題。MapR和Cloudera的Hadoop發行版同樣都隨帶冗余的名稱節點功能。
原文:Facebook tackles Hadoop Achilles' Heel