













海量數據處理之系統過載保護
前段時間在網上看到騰訊后臺開發總監bison分享的一篇文章《淺談過載保護》,讀來受益匪淺。剛好自己也在處理系統請求過載的問題,把自己的一些心得體會總結出來拿來與大家一起探討。
在bison的文章中談到:對于延時敏感的服務,當外部請求超過系統處理能力,如果系統沒有做相應保護,可能導致歷史累計的超時請求達到一定的規模,像雪球一樣形成惡性循環,由于系統處理的每個請求都因為超時而無效,系統對外呈現的服務能力為0,且這種情況不能自動恢復。我們的系統就是要盡量避免這種情況的出現,下面將詳細來分析一個現實中的案例。
一 有過載問題的系統
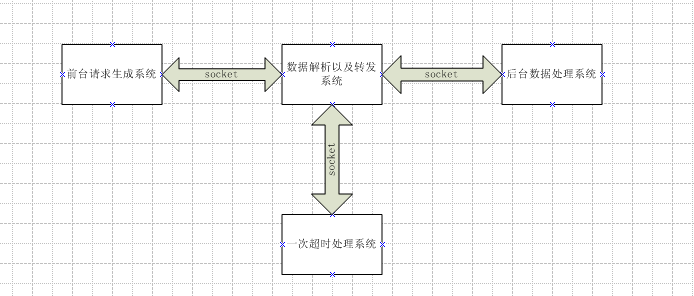
數據處理流程:
1) 前端將請求發送給數據解析及轉發系統,
2)數據解析及轉發系統將封裝好的數據發送后臺數據請求,設置超時時間(假設300ms),線程同步等待處理結果從后臺返回。
3)在300ms內正確返回結果后,則將處理的結果返回給前端,如果在300ms內超時,則將數據發送到一次超時處理系統(假設設置超時時間500ms),線程同步等待結果返回。
4)在500ms內正確返回結果后,則將處理的結果返回給前端,如果再一次超時,返回一個默認的處理結果給前端,后端對數據進行本地化,然后可以將數據發送到離線處理系統進行二次處理。
數據解析的機器為多核,數據解析及轉發系統采用的是單進程多線程模型,在前一篇文章《海量數據處理系列之Java線程池使用》詳細描述了多線程處理的實現,采取的是無界隊列線程池的實現,這樣從客戶端來的請求,會被這樣處理:
1) 如果線程池中有空閑線程,會將請求直接交給線程處理。
2) 如果沒有空閑線程,就將請求保存到任務隊列。
假設開50個線程,每個線程秒平均處理一個請求,那么系統每秒可以處理的最大請求數是50個。一旦前端數據請求超過50個每秒,在任務隊列中將會堆積大量的請求,前臺不斷發送過來,后來處理不過來,前端又設置了套接字超時,導致隊列中的大量請求超時,直接使得后端線程從隊列中取出套接字解析的時候,套接字已經被前臺關閉了,引發I/O異常。堆積的量一旦雪崩,將使前臺發送過來的請求全部I/O異常,后臺處理系統跟掛掉無異了。
二 相對完善的系統
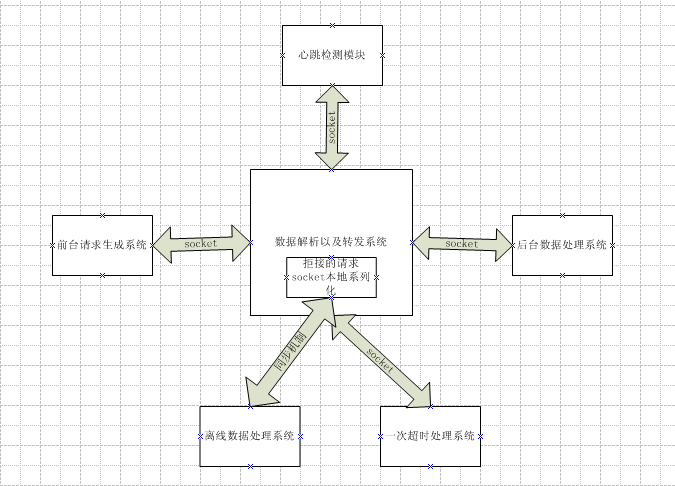
在上面的系統中,對請求是來者不拒的狀態,具體來講就是將所有的請求都保存到任務隊列。請求堆積到一定程度,隊列中的很多請求都超時,這是可以采取清空請求隊列的方式,這個可以通過采取一定的監控方式來實現。例如上圖中的心跳監控模塊,它可以通過這樣的方式來實現,就是模擬客戶端的請求,每隔一定時間發送一些請求過去,如果有大部分都正常返回,說明后端處理系統正常;當出現大部分超時的時候,說明后臺系統已經掛掉了,這時候重啟數據解析及轉發系統,清空系統中的任務請求隊列,這樣可以暫時處理請求高峰期的情況。
但是這個方式也是治標不治本的,后臺最多只能處理這么多請求,重啟后照樣會導致大量堵塞導致系統又掛掉,然后監控系統又重啟,這樣會使得很多的請求沒有得到有效的處理,大大降低系統的處理能力。為了保證后臺系統每時每刻都最大限度的發揮自己的處理能力,當負載超過系統自身的處理能力時,拒絕該請求。拒絕后可以將該請求本地系列化,保存相關的數據發送到離線數據處理系統進行處理。
在前一篇文章《海量數據處理系列之Java線程池使用》第四節中有界隊列線程池使用中有提到這種方式的具體實現。以上面的系統為例,有界線程池可以這樣配置,corePoolSize為30,maximumPoolSize為50,有界隊列為ArrayBlockingQueue<Runnable>(100)。這樣系統在處理請求的時候采用如下策略:
1) 當一個請求過來,線程池開啟一個線程來處理,直到30個線程都在處理請求。
2) 當線程池中沒有空閑線程了,就將請求添加到有界隊列當中,直到隊列滿為止。
3) 當隊列滿以后,在開啟線程來處理新的請求,直到開啟的線程數達到maximumPoolSize。
4) 當開啟的線程數達到maximumPoolSize后,任務隊列又已經滿了后,此時再過來的請求將被拒絕,被拒絕的請求在本地系列化,將保存的數據同步到離線數據系統進行處理。
海量數據處理都是采用分布式的,每臺機器的處理能力有限,可以將請求分布到不同的機器上去。如果每臺機器被拒絕的請求數過多的時候,就要考慮添加處理的機器了。
原文鏈接:http://www.cnblogs.com/cstar/archive/2012/06/25/2561388.html
【編輯推薦】
- 系統架構師談企業應用架構之開卷有益
- 系統架構師談企業應用架構之系統建模1
- 系統架構師談企業應用架構之系統建模2
- 系統架構師談企業應用架構之系統建模3
- 系統架構師談企業應用架構之系統建模4
- 系統架構師談企業應用架構之系統設計規范與原則1
- 系統架構師談企業應用架構之系統設計規范與原則2
- 系統架構師談企業應用架構之業務邏輯層



















