













教你面試的時候如何迅速完成90%以上的海量數據處理題

上篇文章《??美團二面:如果每天有百億流量,你如何保證數據一致性???》,初步給大家分析了一下,一個復雜的分布式系統(tǒng)中,數據不一致的問題是怎么產生的。
簡單來說,就是一個分布式系統(tǒng)中的多個子系統(tǒng)(或者服務)協作處理一份數據,但是最后這個數據的最終結果卻沒有符合期望。
這是一種非常典型的數據不一致的問題。當然在分布式系統(tǒng)中,數據不一致問題還有其他的一些情況。
比如說多個系統(tǒng)都要維護一份數據的多個副本,結果某個系統(tǒng)中的數據副本跟其他的副本不一致,這也是數據不一致。
但是這幾篇文章,說的主要是我們上篇文章分析的那種數據不一致的問題到底應該如何解決。
一、多系統(tǒng)訂閱數據回顧
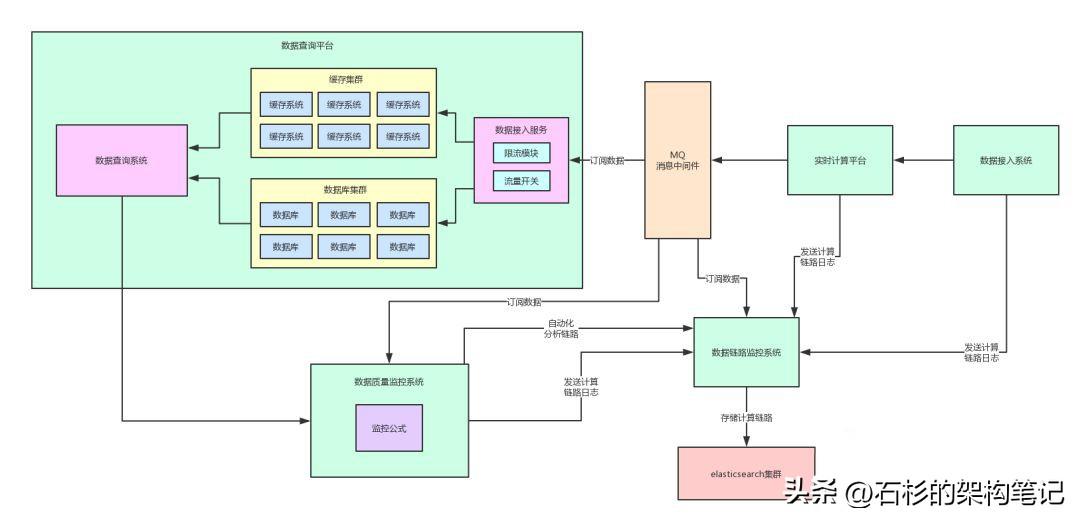
我們先來看一張圖,是之前講系統(tǒng)架構解耦的時候用的一張圖。
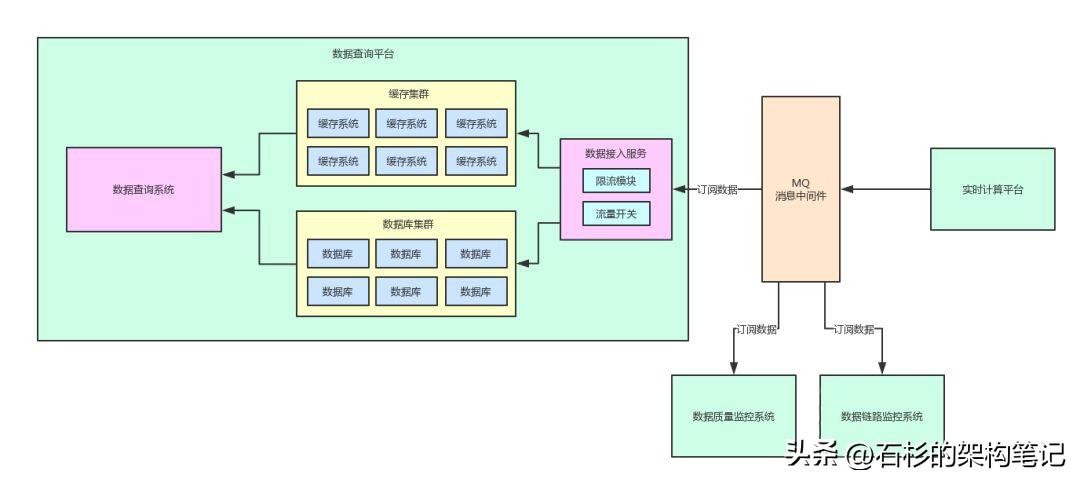
好!通過上面這張圖,我們來回顧一下之前做了系統(tǒng)解耦之后的一個架構圖。
其實,實時計算平臺會把數據計算的結果投遞到一個消息中間件里。
然后,數據查詢平臺、數據質量監(jiān)控系統(tǒng)、數據鏈路追蹤系統(tǒng),各個系統(tǒng)都需要那個數據計算結果,都會去訂閱里面的數據。
這個就是當前的一個架構,所以這個系列文章分析到這里,大家也可以反過來理解了之前為什么要做系統(tǒng)架構的解耦了。
因為一份核心數據,是很多系統(tǒng)都可能會需要的。通過引入MQ對架構解耦了之后,各個系統(tǒng)就可以按需訂閱數據了。
二、核心數據的監(jiān)控系統(tǒng)
如果要解決核心數據的不一致問題,首先就是要做核心數據的監(jiān)控。
有些同學會以為這個監(jiān)控就是用falcon之類的系統(tǒng),做業(yè)務metrics監(jiān)控就可以了,但是其實并不是這樣。
這種核心數據的監(jiān)控,遠遠不是做一個metrics監(jiān)控可以解決的。
在我們的實踐中,必須要自己開發(fā)一個核心數據的監(jiān)控系統(tǒng),在里面按照自己的需求,針對復雜的數據校驗邏輯開發(fā)大量的監(jiān)控代碼。
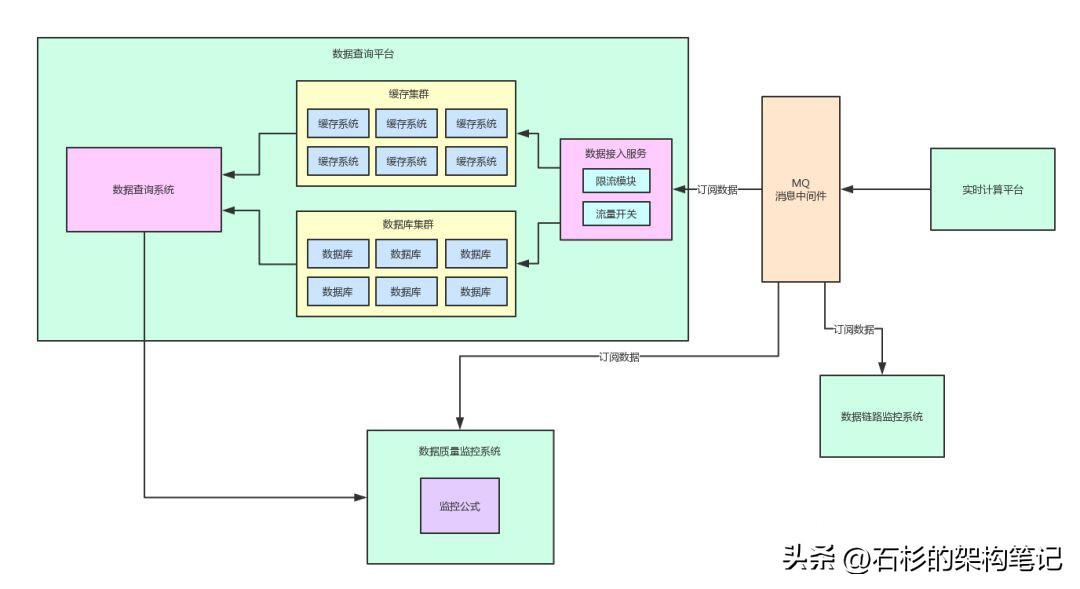
我們用那個數據平臺項目來舉例,自己寫的數據質量監(jiān)控系統(tǒng),需要把核心的一些數據指標從MQ里消費出來,這些數據指標都是實時計算平臺計算好的。
那么此時,就需要自定義一套監(jiān)控邏輯了,這種監(jiān)控邏輯,不同的系統(tǒng)都是完全不一樣的。
比如在這種數據類的系統(tǒng)里,很可能對數據指標A的監(jiān)控邏輯是如下這樣的:
- 數據指標A = 數據指標B + 數據指標C - 數據指標D * 24。
每個核心指標都是有自己的一個監(jiān)控公式的,這個監(jiān)控公式,就是負責開發(fā)實時計算平臺的同學,他們寫的數據計算邏輯,是知道數據指標之間的邏輯關系的。
所以此時就有了一個非常簡單的思路:
- 首先,這個數據監(jiān)控系統(tǒng)從MQ里消費到每一個最新計算出來的核心數據指標。
- 然后根據預先定義好的監(jiān)控公式,從數據查詢平臺里調用接口獲取出來公式需要的其他數據指標。
- 接著,按照公式進行監(jiān)控計算。
如果監(jiān)控計算過后發(fā)現幾個數據指標之間的關系居然不符合預先定義好的那個規(guī)則,那么此時就可以立馬發(fā)送報警了(短信、郵件、IM通知)。
工程師接到這報警之后,就可以立馬開始排查,為什么這個數據居然會不符合預先定義好的一套業(yè)務規(guī)則呢。
這樣就可以解決數據問題的第一個痛點:不需要等待用戶發(fā)現后反饋給客服了,自己系統(tǒng)第一時間就發(fā)現了數據的異常。
同樣,給大家上一張圖,直觀的感受一下。
三、電商庫存數據如何監(jiān)控
如果用電商里的庫存數據來舉例也是一樣的,假設你想要監(jiān)控電商系統(tǒng)中的核心數據:庫存數據。
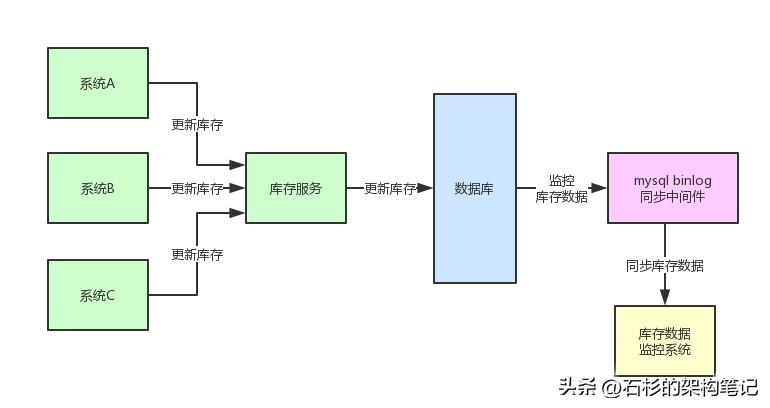
首先第一步,在微服務架構中,你必須要收口。
也就是說,在徹底的服務化中,你要保證所有的子系統(tǒng) / 服務如果有任何庫存更新的操作,全部走接口調用請求庫存服務。只能是庫存服務來負責庫存數據在數據庫層面的更新操作,這樣就完成了收口。
收口了之后做庫存數據的監(jiān)控就好辦了,完全可以采用MySQL binlog采集的技術,直接用Mysql binlog同步中間件來監(jiān)控數據庫中庫存數據涉及到的表和字段。
只要庫存服務對應的數據庫中的表涉及到增刪改操作,都會被Mysql binlog同步中間件采集后,發(fā)送到數據監(jiān)控系統(tǒng)中去。
此時,數據監(jiān)控系統(tǒng)就可以采用預先定義好的庫存數據監(jiān)控邏輯,來查驗這個庫存數據是否準確。
這個監(jiān)控邏輯可以是很多種的,比如可以后臺走異步線程請求到實際的C/S架構的倉儲系統(tǒng)中,查一下實際的庫存數量。
或者是根據一定的庫存邏輯來校驗一下,舉個例子:
- 虛擬庫存 + 預售庫存 + 凍結庫存 + 可銷售庫存 = 總可用庫存數。
當然,這就是舉個例子,實際如何監(jiān)控,大家根據自己的業(yè)務來做就好了。
四、數據計算鏈路追蹤
此時我們已經解決了第一個問題,主動監(jiān)控系統(tǒng)中的少數核心數據,在第一時間可以自己先收到報警發(fā)現核心是護具有異常。
但是此時我們還需要解決第二個問題,那就是當你發(fā)現核心數據出錯之后,如何快速的排查問題到底出在哪里?
比如,你發(fā)現數據平臺的某個核心指標出錯,或者是電商系統(tǒng)的某個商品庫存數據出錯,此時你要排查數據到底為什么錯了,應該怎么辦呢?
很簡單,此時我們必須要做數據計算鏈路的追蹤。
也就是說,你必須要知道這個數據從最開始到底是經歷了哪些環(huán)節(jié)和步驟,每個環(huán)節(jié)到底如何更新了數據,更新后的數據又是什么,還有要記錄下來每次數據變更后的監(jiān)控檢查點。
比如說:
- 步驟A -> 步驟B -> 步驟C -> 2018-01-01 10:00:00。
第一次數據更新后,數據監(jiān)控檢查點,數據校驗情況是準確,庫存數據值為1365。
- 步驟A -> 步驟B -> 步驟D -> 步驟C -> 2018-01-01 11:05:00。
第二次數據更新后,數據監(jiān)控檢查點,數據校驗情況是錯誤,庫存數據值為1214。
類似上面的那種數據計算鏈路的追蹤,是必須要做的。
因為你必須要知道一個核心數據,他每次更新一次值經歷了哪些中間步驟,哪些服務更新過他,那一次數據變更對應的數據監(jiān)控結果如何。
此時,如果你發(fā)現一個庫存數據出錯了,立馬可以人肉搜出來這個數據過往的歷史計算鏈路。
你可以看到這條數據從一開始出現,然后每一次變更的計算鏈路和監(jiān)控結果。
比如上面那個舉例,你可能發(fā)現第二次庫存數據更新后結果是1214,這個值是錯誤的。
然后你一看,發(fā)現其實第一次更新的結果是正確的,但是第二次更新的計算鏈路中多了一個步驟D出來,那么可能這個步驟D是服務D做了一個更新。
此時,你就可以找服務D的服務人問問,結果可能就會發(fā)現,原來服務D沒有按照大家約定好的規(guī)則來更新庫存,結果就導致庫存數據出錯。
這個,就是排查核心數據問題的一個通用思路。
五、百億流量下的數據鏈路追蹤
如果要做數據計算鏈路,其實要解決的技術問題只有一個,那就是在百億流量的高并發(fā)下,任何一個核心數據每天的計算鏈路可能都是上億的,此時你應該如何存儲呢?
其實給大家比較推薦的,是用elasticsearch技術來做這種數據鏈路的存儲。
因為es一方面是分布式的,支持海量數據的存儲。
而且他可以做高性能的分布式檢索,后續(xù)在排查數據問題的時候,是需要對海量數據做高性能的多條件檢索的。
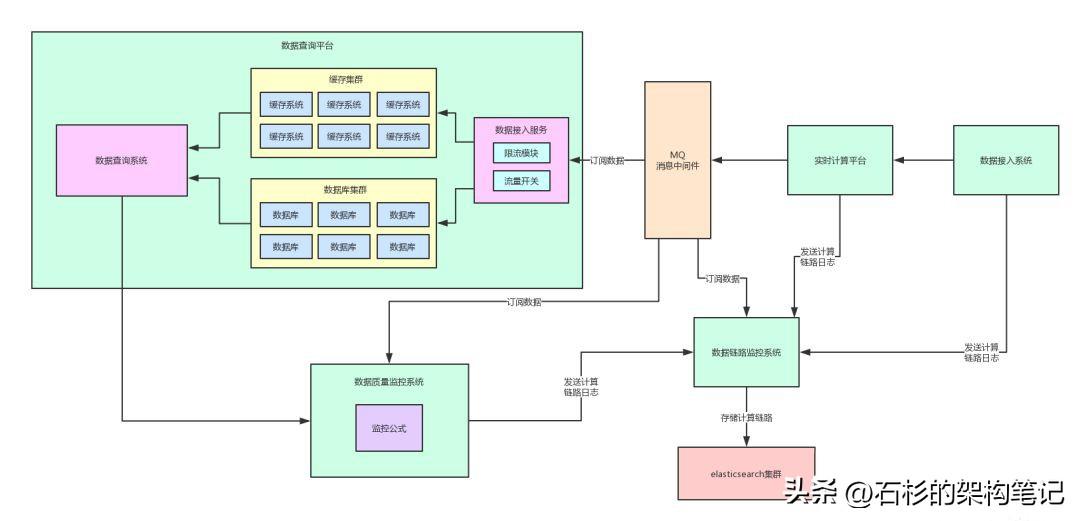
所以,我們完全可以獨立出來一個數據鏈路追蹤系統(tǒng),并設置如下操作:
- 數據計算過程中涉及到的各個服務,都需要對核心數據的處理發(fā)送一條計算鏈路日志到數據鏈路追蹤系統(tǒng)。
- 然后,數據鏈路追蹤系統(tǒng)就可以把計算鏈路日志落地到存儲里去,按照一定的規(guī)則建立好對應的索引字段。
- 舉個例子,索引字段:核心數據名稱,核心數據id,本次請求id,計算節(jié)點序號,本次監(jiān)控結果,子系統(tǒng)名稱,服務名稱,計算數據內容,等等。
此時一旦發(fā)現某個數據出錯,就可以立即根據這條數據的id,從es里提取出來歷史上所有的計算鏈路。
而且還可以給數據鏈路追蹤系統(tǒng)開發(fā)一套用戶友好的前端界面,比如在界面上可以按照請求id展示出來每次請求對應的一系列技術步驟組成的鏈路。
此時會有什么樣的體驗呢?我們立馬可以清晰的看到是哪一次計算鏈路導致了數據的出錯,以及過程中每一個子系統(tǒng) / 服務對數據做了什么樣的修改。
然后,我們就可以追本溯源,直接定位到出錯的邏輯,進行分析和修改。
說了那么多,還是給大家來一張圖,一起來感受一下這個過程。
六、自動化數據鏈路分析
到這里為止,大家如果能在自己公司的大規(guī)模分布式系統(tǒng)中,落地上述那套數據監(jiān)控 + 鏈路追蹤的機制,就已經可以非常好的保證核心數據的準確性了。
通過這套機制,核心數據出錯時,第一時間可以收到報警,而且可以立馬拉出數據計算鏈路,快速的分析數據為何出錯。
但是,如果要更進一步的節(jié)省排查數據出錯問題的人力,那么可以在數據鏈路追蹤系統(tǒng)里面加入一套自動化數據鏈路分析的機制。
大家可以反向思考一下,假如說現在你發(fā)現數據出錯,而且手頭有數據計算鏈路,你會怎么檢查?
不用說,當然是大家坐在一起唾沫橫飛的分析了,人腦分析。
比如說,步驟A按理說執(zhí)行完了應該數據是X,步驟B按理說執(zhí)行完了應該數據是Y,步驟C按理說執(zhí)行完了應該數據是Z。
結果,誒!步驟C執(zhí)行完了怎么數據是ZZZ呢??看來問題就出在步驟C了!
然后去步驟C看看,發(fā)現原來是服務C更新的,此時服務C的負責人開始吭哧吭哧的排查自己的代碼,看看到底為什么接收到一個數據Y之后,自己的代碼會處理成數據ZZZ,而不是數據Z呢?
最后,找到了代碼問題,此時就ok了,在本地再次復現數據錯誤,然后修復bug后上線即可。
所以,這個過程的前半部分,是完全可以自動化的。也就是你寫一套自動分析數據鏈路的代碼,就模擬你人腦分析鏈路的邏輯即可,自動一步步分析每個步驟的計算結果。這樣就可以把數據監(jiān)控系統(tǒng)和鏈路追蹤系統(tǒng)打通了。
一旦數據監(jiān)控系統(tǒng)發(fā)現數據出錯,立馬可以調用鏈路追蹤系統(tǒng)的接口,進行自動化的鏈路分析,看看本次數據出錯,到底是鏈路中的哪個服務bug導致的數據問題。
接著,將所有的信息匯總起來,發(fā)送一個報警通知給相關人等。
相關人員看到報警之后,一目了然,所有人立馬知道本次數據出錯,是鏈路中的哪個步驟,哪個服務導致的。
最后,那個服務的負責人就可以立馬根據報警信息,排查自己的系統(tǒng)中的代碼了。
七、總結
到這篇文章為止,我們基本上梳理清楚了大規(guī)模的負責分布式系統(tǒng)中,如何保證核心數據的一致性。


















