













鐵道部新客票系統設計(一)
非功能性要求
廢話不說,這里先脫離系統的整體架構,后續在不斷完善整體架構,這里首先討論的是數據庫層面的設計,因為對于整個架構系統來說,數據庫的設計是最為關鍵重要的,數據庫的設計好與壞,決定了整個系統的性能,可用性,擴展性。在考慮數據庫的設計之前,我們可以先拋開非業務功能的需求,先看看非功能性需求,主要包括
1 數據庫的類型選擇
目前市場上數據庫主要有:關系型數據庫(Oracle,DB2,Mysql),NOSQL類型數據庫(MogonDB),對象數據庫(不是很了解),面向文檔的數據庫(apache couchBD),面向統計的數據庫(HBASE)
根據客票系統的類型,應該是屬于OLTP類型的系統,但是考慮到商業上分析需求,也屬于OLAP型系統,由于本次討論OLTP系統的設計,優先選擇Oracle。為啥,用的公司多,市場上相關的技術工程師多,DBA管理員多,安全性和性能都不錯。就是有點貴,不過考慮到是鐵道部,完全忽略。對于部分客票系統非關鍵性業務也不重要的,這一部分數據可以考慮使用Mysql。至于NOSQL,沒有用過,這個主要是面向web2.0的,對于事務要求高的系統,不太適合。
2 多數據中心
在金融行業,都必須部署多個數據中心,避免在一個數據庫機房故障之后,全部數據都不可用。比如假如某地地震,數據庫所在機房宕機了,如果這個時候檢票或者買票,就sb了,所以需要盡快恢復。這樣必須馬上啟動另外一個數據庫機房配置。
除去災備情況,考慮到鐵路售票系統數據庫的巨大訪問量,2011年的鐵道部的旅客發送量---2011年全國鐵路運輸目標:旅客發送量19億人次,根據這個,初略估計一下一年估計要20億張票,這個只是2011年的量,按照未來的幾年的增長,按照目標值100億人次估計,相當于一天有2700W獨立UV,1億PV。考慮到春節這個變態的高峰期,瞬間的并發量比平時會高上千倍。如果只在一個數據庫只有一臺,數據庫就會存在單點,一旦數據庫掛掉了,需要盡快的恢復。這個時候不太可能啟用災備數據庫,因為災備是異地備份,備份數據庫同步數據比較慢(網絡延遲),所以必須必須在同一個城市在部署一套數據庫。這樣在單點數據庫故障的時候,可以馬上切到備份數據庫。
下面兩幅圖主要介紹異地災備以及同城異機房備份的實現原理。
同城備份
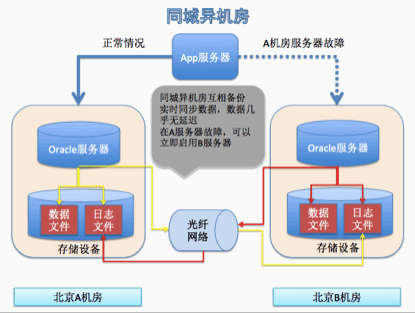
數據一次寫一份,日志寫兩份。由于日志文件實時同步,A服務器寫完B服務器的日志文件,B服務器馬上就寫自己的數據文件。這樣不會丟失數據。當A服務器故障,應用馬上就可以切換到B服務器。不會存在單點故障。但是考慮特殊情況,北京地震,A,B機房同時故障,整個數據都丟失了。所以必須由異地災備的數據中心。不過還有其他的方式,這里就不做敘述了。總之是要做好去除單點。
異地備份
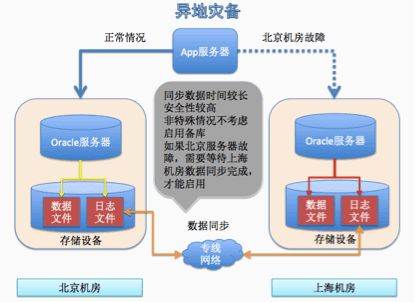
這個架構和同城備份有一點區別,就是A服務器只會寫A機房的日志文件,然后A異步同步日志到B機房的日志文件。這里面會有幾分鐘的網絡延遲。這里不實時寫B機房的日志文件,主要是性能。如果實時寫B機房的數據,一次更新操作,就會至少有一次網絡延遲(上海到北京的網絡傳輸時間)。會影響數據庫的性能。而同城市通過光纖連接,傳輸速率快,可以忽略網絡延遲。如果A機房故障(災難性的故障,比如地震,機房被恐怖分子襲擊),就會丟失一部分數據,丟失的數據就是網絡延遲同步的數據。對于購票業務來說,數據丟失幾分鐘的,是可以接受的,大不了我鐵道部虧一點,這幾分鐘丟失的數據我全部免票。也可以做一次好的營銷。但是對于金融行業來說,數據是不能丟失的,這里的異地備份就不符合金融業的要求。用性能換取可用性。就像atm取錢一樣,一次交易涉及幾分鐘。你的交易數據銀行至少會備份2份,一份同城的,一份異地的。
3 硬件配置
這一塊不是很熟悉,交給dba專業的人去做吧。小機 + 存儲(SAS)。不過對于鐵道部有錢,上大機即可。不過我們還是按照互聯網方式去分析設計系統,使用普通的存儲以及服務器。
功能性分析
1 業務流程分析
先簡單的了解一下購票系統的業務流程:旅客到互聯網(也可能是其他渠道)登錄,根據出發日期,起始站,終點站查詢車票,確定車次和座位,預定車票,然后進行支付,支付成功之后,發短信,之后客戶到線下去取票。一個簡單的流程就結束了。
從上面的流程可以看出,整個業務流程中有幾個以下幾個實體以及實體的重要屬性信息
1 旅客信息:假設都是實名的,至少有三個重要信息 姓名,身份證,手機號
2 車次信息:車次,起始站,終點站,類型,發車時間,到達時間
3 車次停靠信息:車次,停靠站,達到時間,停靠時間
4 余票信息:車次,起始站,終點站,發車日期,剩余座票,剩余臥鋪。。。
5 車票信息:車次,起始站,終點站,發車日期,購票日期,旅客姓名,身份證,手機號,狀態,購票渠道,支付日期
6 支付信息:金額,支付日期,支付銀行,支付金額,支付方式
7 短信信息:車票信息,驗證碼,短信內容
整個購票過程包括以上幾個重要的實體,其他的幾個字段可以先不管。我們可以假設一下每一個實體的數據規模
| 實體 | 數據量 | 日增量 |
| 旅客信息 | 上限-中國人口數 16億 | 這個真不好估計 |
| 車次信息 | 比較少,假設10萬 | 日增應該也不會超過10 |
| 車次停靠信息 | 車次信息 ×200 == 200W | 日增應該也不會超過100 |
| 車票信息 | 巨大,目前年增20億,未來年曾100億 | 自己換算一下,不過不會很平均,春節幾天會暴增 |
| 支付信息 | 和車票信息同數量級 | 和車票信息一樣 |
| 短信信息 | 少于車票信息,畢竟只有網絡訂票才會有短信,線下購票不會有 | 未知,假設100W |
| 余票信息 | 一年交易量 365×車次信息 == 5000W | 日增數據量 和 車次信息數量一致 假設10W |
從數據量來看 車票信息 > 支付信息 > 短信信息 > 余票信息 > 旅客信息 > 車次停靠信息 > 車次信息
從如此數據量來看,必須進行分庫分表。所以分庫分表就在設計庫的時候就顯的非常重要。
2 簡單分庫策略
旅客信息相關的信息單獨分在一個庫,這些數據相對來說是讀多寫少,并且可以大量進行緩存,是基礎相數據。
車次相關的信息,比如車次,車次停靠可以單獨放在一個標里面,這個標是保存原數據信息,數據量不大,數據完全可以緩存。可以考慮和余票庫放在一次。
剩下就是四大的實體信息,余票信息,車票信息,支付信息,短信通知信息,首先短信通知信息相對來說比較通用的,可能未來很多業務都會涉及到短信通知,所以短信相關的信息放在一個庫
在剩下就是考慮業務上比較耦合的三個實體:余票,車票,支付。
余票查詢頻繁,每出一張票,就會更新余票數
車票數據量巨大,有查詢和更新需求
支付信息:單筆查詢和更新需求
考慮到車票和支付信息在數據量級上遠遠高于余票信息,余票信息單獨一個庫,而車票信息和支付信息業務上差異比較大,也單獨分出來。
根據以上的分析,可以分出來5個邏輯庫:旅客庫,車票庫,短信庫,車次庫(車次信息,余票信息),支付庫。
繼續往下分析,在5個邏輯庫里面,由于旅客庫數據量有上線,只需要分配一個實體庫即可。 車次庫增長有限,也暫時分配一個實體庫里面。而車庫票,支付庫,短信庫數據量比較大,分配一個實體庫顯然不夠。下面單獨分析這三個邏輯庫的分庫策略
3 車票庫分庫策略
對于車票信息的分庫策略,需要考慮到以下幾個因素
1. 功能需求
查詢需求:按照購票日期 + 旅客信息 + 狀態 或者 旅客 + 發車日期 + 狀態
統計需求:按發車日期統計購票總數量和金額 或者其他幾個維度
交易需求:創建車票信息,更新車票狀態,創建關聯支付信息
對賬需求:(假設不考慮退票需求)按照支付日期統計支付流水總金額 以及 統計 支付成功的車票信息總金額
2. 負載均衡
按照數據庫處理實時要求進行分析,響應要求高的請求和耗時類請求分開,優先保證能夠賣出票,支付車票。同時不能所有的請求都指向一個庫。
3 高可用性
避免單點,否則購票功能就不可用。所以數據庫至少有備份機制。
4 數據均勻
避免大多數據都在同一個庫,否則遇到大數據查詢數據庫負載會很高,進而影響系統整體的可用性。因為大多數請求都會排隊,導致系統資源耗盡。
5 可擴展性
當數據增長過快時候,能夠很靈活的添加數據庫而整個應用不需要做太大的修改
根據以上幾個因素考慮,每一張車票生成一個全局的唯一性id,根據id最后一位數字/N平均把數據分配到N個數據庫中,這樣每張車票庫最多可以分成10個庫,可擴展性不強。也可以考慮一致性hash算法進行分庫,但是這個比較復雜。還有一種方式就是隨機分庫,好處是可以無限擴展數據庫,但是會給查詢帶來很大的影響。考慮到查詢需求,太多的庫可能導致查詢復雜,甚至在有限時間內無法查詢出來。這里采用最后數字/N的方式進行分庫,N為數據庫的個數。在這個基礎上,在增加一個庫,就是歷史庫,暫時只需要一個即可,把完結的歷史數據遷移到這個庫,一個季度之前的數據不需要在進行操作,一般只是查詢需求,就遷移到這個庫里面,減少交易庫的壓力。
這里分10個線上庫,一個歷史庫。一共11個庫。能夠支持年100億的交易規模。不過對于對賬的需求,可以考慮另外的方式來實現。這里以后在說。
下面一幅圖展示了分庫的模型:

通過以上的分庫策略,如果某一個庫宕機了,會影響1/10的購票用戶。
4 余票庫分庫策略
余票庫雖然數據量沒有車票庫數大,但是查詢和更新需求遠比車票庫頻繁。而且是整個業務的關鍵路徑。在考慮這個庫的只需要保持一個月的數據即可,一個月前的數據可以遷移走,不需要所有的數據。而在春運期間,這個庫的瞬間訪問量會飆升,相當于淘寶的秒殺,要求實時性比較高,所以不太可能讀寫分離。綜合考慮,可以分為兩個庫, 線上庫和歷史庫。歷史庫用來做分析。這個后續是設計的重點。
5 支付庫分庫策略
支付信息和車票信息這兩個庫有點類似,只是用戶查詢相對來說比較少。這個支付庫分庫策略和車票庫的策略可以一樣。
6 短信庫分庫策略
由于短信通知是全站業務,這個完全可以獨立與購票業務。消息量大,但非關鍵業務,非系統關鍵路徑,對實時行要求不高,所以簡單分成兩個庫即可。
在分庫之后,數據一致性要求就會比較高,涉及到分布式事務 ,后續會重點討論分布式事務的設計。
先寫到這里吧,下一篇 會分析表結構以及分表策略和索引。
原文鏈接:http://www.cnblogs.com/aigongsi/archive/2012/09/17/2683656.html
【編輯推薦】
- ASP.NET Web開發框架項目介紹
- YQBlog .NET MVC3博客系統之用戶系統實戰
- ASP.NET Cache的一些總結
- ASP.NET中常用的幾種身份驗證方式
- 各自為政:ASP.NET實現團隊分工的思考











