帶你快速搭建Hadoop運行環境
Hadoop 是一個分布式系統基礎架構,在大數據領域被廣泛的使用,它將大數據處理引擎盡可能的靠近存儲,Hadoop 最核心的設計就是 HDFS 和 MapReduce,HDFS 為海量的數據提供了存儲,MapReduce 為海量的數據提供了計算。這篇文章主要就是介紹一下如何搭建一個 Hadoop 運行環境。

我們使用 Linux 操作系統來搭建環境,下面的信息是用來準備搭建 Hadoop 環境的電腦環境信息。
- hadoop@ubuntu:~$ cat /etc/os-release
- NAME="Ubuntu"
- VERSION="14.04.5 LTS, Trusty Tahr"
- ID=ubuntu
- ID_LIKE=debian
- PRETTY_NAME="Ubuntu 14.04.5 LTS"
- VERSION_ID="14.04"
- HOME_URL="http://www.ubuntu.com/"
- SUPPORT_URL="http://help.ubuntu.com/"
- BUG_REPORT_URL="http://bugs.launchpad.net/ubuntu/"
緊接著來新建一個用戶,這一步其實也可以省略的,可以根據實際情況來決定,這里是新建了一個叫 hadoop 的新用戶。
- #創建新用戶
- sudo useradd -m hadoop -s /bin/bash
- #設置密碼
- sudo passwd hadoop
- #為hadoop用戶增加管理員權限
- sudo adduser hadoop sudo
- #切換到hadoop用戶
- su hadoop
我們首先來設置一下 SSH 無密碼登錄,這一步建議都設置一下,因為分布式系統環境都是由多臺服務器構成的,設置免密碼登錄會方便使用。
- #先檢查下是否可以在沒有密碼的情況下ssh到localhost
- ssh localhost
- #如果在沒有密碼的情況下無法ssh到localhost,請執行以下命令
- ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- chmod 0600 ~/.ssh/authorized_keys
上面是一些準備工作,接下來就正式開始部署 Hadoop 環境了。我們先在 Apache 官網(http://hadoop.apache.org)這里下載最新的穩定版本的 Hadoop 發行版,然后解壓到指定目錄并進入這個目錄,執行 ./bin/hadoop 和 ./bin/hadoop version 可以分別顯示 hadoop 腳本的使用文檔和版本信息,然后修改一下 ./etc/hadoop/core-site.xml 和 ./etc/hadoop/hdfs-site.xml這兩個配置文件,配置修改分別如下所示。
修改 ./etc/hadoop/core-site.xml 配置文件,添加如下配置:
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:9090</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>file:/opt/bigdata/hadoop/tmp</value>
- <description>A base for other temporary directories.</description>
- </property>
- </configuration>
修改 ./etc/hadoop/hdfs-site.xml 配置文件,添加如下配置:
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/opt/bigdata/hadoop/tmp/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/opt/bigdata/hadoop/tmp/dfs/data</value>
- </property>
- </configuration>
配置修改好之后,執行格式化文件系統,操作如下。
- hadoop@ubuntu:/opt/bigdata/hadoop$ ./bin/hdfs namenode -format
- #執行后輸出會比較多,看到下邊這條信息表示成功
- INFO common.Storage: Storage directory /opt/bigdata/hadoop/tmp/dfs/name has been successfully formatted.
在格式化 NameNode 的時候可能會遇到下面這樣的兩個問題。
- 提示 Error: JAVA_HOME is not set and could not be found. 的錯誤,這說明 JAVA_HOME 環境變量沒有配置好,重新配置一下,或者修改 ./etc/hadoop/hadoop-env.sh 文件把 export JAVA_HOME=${JAVA_HOME} 直接修改成絕對目錄 export JAVA_HOME=/usr/lib/jvm/java-8 既可解決。
- 提示 ERROR namenode.NameNode: java.io.IOException: Cannot create directory /opt/bigdata/hadoop/tmp/dfs/name/current 的錯誤,這是因為配置的 /opt/bigdata/hadoop/tmp 目錄的寫入權限有問題,可以直接執行 sudo chmod -R a+w /home/hadoop/tmp 即可解決。
接下來執行 ./sbin/start-dfs.sh 來開啟 NameNode 和 DataNode 守護進程,然后檢查 NameNode、DataNode 和 SecondaryNameNode 是否都已經啟動成功,操作如下:
- hadoop@ubuntu:/opt/bigdata/hadoop$ jps
- 4950 Jps
- 3622 SecondaryNameNode
- 3295 DataNode
- 2910 NameNode
啟動成功之后可以用瀏覽器來打開 http://localhost:50070/ 瀏覽 NameNode 的Web界面。
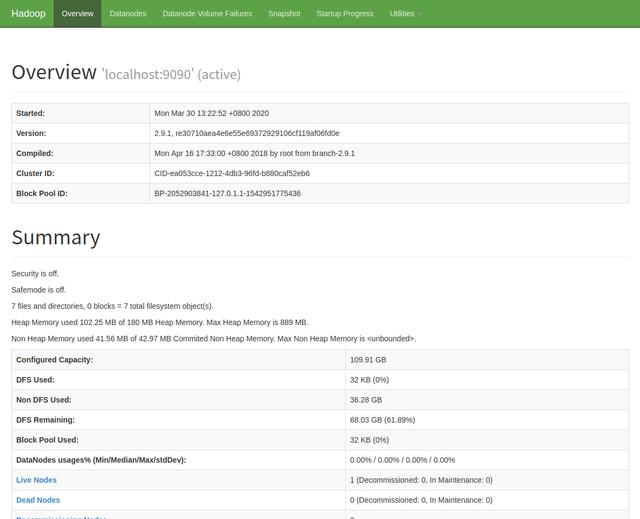
到此為止,Hadoop 單節點集群(偽分布式)環境搭建就已經成功了, 接下來運行一個 Hadoop 偽分布式實例。因為 Hadoop 單機模式是運行的本地文件系統,(偽)分布式模式則是運行的 HDFS 上的數據。我們現在 HDFS 中創建用戶目錄,執行目命令 ./bin/hdfs dfs -mkdir -p /user/hadoop 即可,執行如下命令將輸入文件復制到分布式文件系統中。
- #這個可以不執行,因為會自動創建好目錄的
- #./bin/hdfs dfs -mkdir input
- ./bin/hdfs dfs -put etc/hadoop input
- #查看復制到HDFS的文件列表
- ./bin/hdfs dfs -ls input
接下來運行一個 Hadoop 自帶的 mapreduce 實例看看效果吧,直接執行如下命令。
- ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-
- 2.9.1.jar grep input output 'dfs[a-z.]+'
使用 ./bin/hdfs dfs -cat output/* 命令查看運行后在 HDFS 上的輸出文件列表,或者使用下面的命令拷貝到本地查看。
- ./bin/hdfs dfs -get output output
- ./cat output/*
關閉 Hadoop 直接使用 ./sbin/stop-dfs.sh 命令即可。

這里介紹了 Hadoop 環境搭建的最基本最簡單的方法,我建議最好是邊看邊動手操作一下,這樣可以加深印象和理解,更加有利于掌握相關知識點。當然,Hadoop 環境搭建還有其他一些方法,也是實際開發中常用的方法,比如基于 Yarn、Mesos 等資源調度系統搭建、使用 Docker 搭建等等,有興趣的朋友們可以嘗試一下這些方法,也歡迎留言交流。