遞歸數據效率低怎么辦?用并行計算!
對于比較復雜的互聯網應用業務場景,比如海量數據商品搜索、廣告點擊算法、用戶行為挖掘、關聯推薦模型等等,由于數據量極大,對于數據處理的速度會要求非常高。要大幅提升算法的效率,最直接的方法就是:使用并行計算。
但是,并行計算有一個很大的問題:傳統的程序都是基于單機編寫的。要更改為多機并行的程序,需要耗費較大的學習成本。尤其在真實的場景當中,業務本身很復雜,初學者一頭扎進去,容易繞暈了頭。
因此,我們需要一個通俗易懂的例子來直接看到并行計算的優勢。
下面,淘寶網高級專家千峰就編寫了這樣的一個例子,51CTO受邀將這篇文章分享給大家。
文章概述
問題:
請寫一個程序,輸入M,然后打印出M個數字的所有排列組合(每個數字為1,2,3,4中的一個)。比如:M=3,輸出:
1,1,1 1,1,2 …… 4,4,4
共64個
注意:這里是使用計算機遍歷出所有排列組合,而不是求總數,如果只求總數,可以直接利用數學公式進行計算了。
傳統的單機解決方案:
1)單機遞歸
將n(1<=n<=4)看做深度,輸入的m看做廣度。當m數字很大時,會超出單臺機器的計算局限導致緩慢。
2)單機迭代
求m個數字的排列組合,實際上都可以在m-1的結果基礎上得到。但是,當m=14的時候,結果已經上億了。無論以什么格式存,最終在單機上都會內存溢出。
分布式并行計算解決方案:
1)多機遞歸
這是本篇文章的重點。
核心思想:重新設計算法,按多機進行拆分和合并,利用并行計算優勢去完成結果。
按照并行計算的算法,n臺計算機可以將遞歸降一級,n*n臺計算機可以將遞歸降兩級。理論上,只要機器足夠多,就能持續降低遞歸的復雜度。
運行步驟:
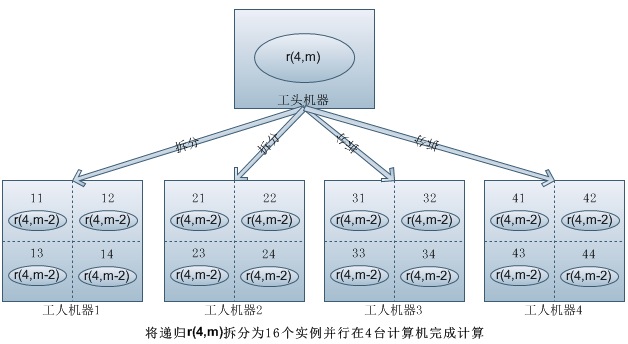
使用fourinone框架設計分布式并行計算。整個框架通過一個ParkServerDemo做整體的工人注冊和分布式協調,中間有作為包工頭的CombCtor(分配工作+統計結果),最下面有多個CombWorker作為工人實現(干活兒+返回結果)。
文中有多機遞歸實現的完整代碼。
2)多機迭代
本文提供了三個多機迭代的思路。相對多機遞歸的方式,多機迭代的方式在這個例子中并不高效,因此沒有提出實現方式。