大數據系列之并行計算引擎Spark介紹
Spark:
Apache Spark 是專為大規模數據處理而設計的快速通用的計算引擎。
Spark是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用并行框架,Spark擁有Hadoop MapReduce所具有的優點;但不同于MapReduce的是Job中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark能更好地適用于數據挖掘與機器學習等需要迭代的MapReduce的算法。
Spark 是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越,換句話說,Spark 啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。
Spark 是在 Scala 語言中實現的,它將 Scala 用作其應用程序框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合對象一樣輕松地操作分布式數據集。
盡管創建 Spark 是為了支持分布式數據集上的迭代作業,但是實際上它是對 Hadoop 的補充,可以在 Hadoop 文件系統中并行運行。通過名為 Mesos 的第三方集群框架可以支持此行為。Spark 由加州大學伯克利分校 AMP 實驗室 (Algorithms, Machines, and People Lab) 開發,可用來構建大型的、低延遲的數據分析應用程序。
Spark的性能特點:
1.更快的速度:內存計算下,Spark 比 Hadoop 快100倍。
- 內存計算引擎,提供Cache機制來支持需要反復迭代計算或者多次數據共享,減少數據讀取的I/O開銷
- DAG引擎,減少多次計算之間中間結果寫到HDFS的開銷;
- 使用多線程池模型來減少task啟動開銷,shuffle過程中避免不必要的sort操作已經減少磁盤I/O操作;
2.易用性:
- Spark 提供了80多個高級運算符。
- 提供了豐富的API,支持JAVA,Scala,Python和R四種語言;
- 代碼量比MapReduce少2~5倍;
3.通用性:Spark 提供了大量的庫,包括SQL、DataFrames、MLlib、GraphX、Spark Streaming。 開發者可以在同一個應用程序中無縫組合使用這些庫。
4.支持多種資源管理器:Spark 支持 Hadoop YARN,Apache Mesos,及其自帶的獨立集群管理器
Spark基本原理:
Spark Streaming:構建在Spark上處理Stream數據的框架,基本的原理是將Stream數據分成小的時間片斷(幾秒),以類似batch批量處理的方式來處理這小部分數據。Spark Streaming構建在Spark上,一方面是因為Spark的低延遲執行引擎(100ms+),雖然比不上專門的流式數據處理軟件,也可以用于實時計算,另一方面相比基于Record的其它處理框架(如Storm),一部分窄依賴的RDD數據集可以從源數據重新計算達到容錯處理目的。此外小批量處理的方式使得它可以同時兼容批量和實時數據處理的邏輯和算法。方便了一些需要歷史數據和實時數據聯合分析的特定應用場合。
Spark背景:
1.MapReduce局限性:
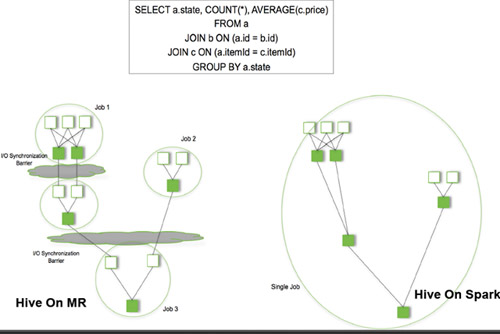
1.僅支持Map和Reduce兩種操作;
2.處理效率低效;不適合迭代計算(如機器學習、圖計算等),交互式處理(數據挖掘)和流失處理(日志分析)
3.Map中間結果需要寫磁盤,Reduce寫HDFS,多個MR之間通過HDFS交換數據;
4.任務調度和啟動開銷大;
5.無法充分利用內存;(與MR產生時代有關,MR出現時內存價格比較高,采用磁盤存儲代價小)
6.Map端和Reduce端均需要排序;
7.MapReduce編程不夠靈活。(比較Scala函數式編程而言)
8.框架多樣化[采用一種框架技術(Spark)同時實現批處理、流式計算、交互式計算]:
- 批處理:MapReduce、Hive、Pig;
- 流式計算:Storm
- 交互式計算:Impala
Spark核心概念:
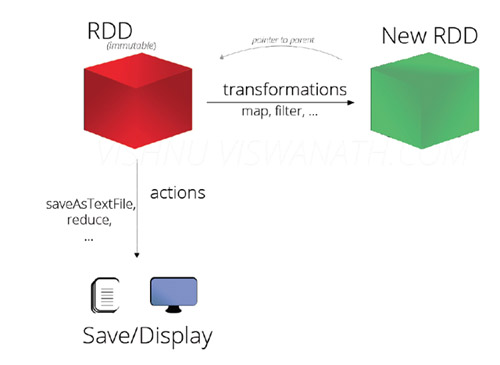
- RDD:Resilient Distributed Datasets,彈性分布式數據集

- 分布在集群中的只讀對象集合(由多個Partition 構成);
- 可以存儲在磁盤或內存中(多種存儲級別);
- 通過并行“轉換”操作構造;
- 失效后自動重構;
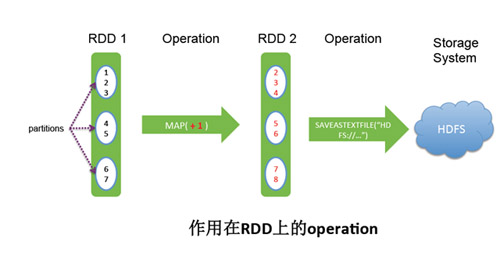
- RDD基本操作(operator)
Transformation具體內容
- map(func) :返回一個新的分布式數據集,由每個原元素經過func函數轉換后組成
- filter(func) : 返回一個新的數據集,由經過func函數后返回值為true的原元素組成
*flatMap(func) : 類似于map,但是每一個輸入元素,會被映射為0到多個輸出元素(因此,func函數的返回值是一個Seq,而不是單一元素)
- flatMap(func) : 類似于map,但是每一個輸入元素,會被映射為0到多個輸出元素(因此,func函數的返回值是一個Seq,而不是單一元素)
- sample(withReplacement, frac, seed) :
根據給定的隨機種子seed,隨機抽樣出數量為frac的數據。
- union(otherDataset) : 返回一個新的數據集,由原數據集和參數聯合而成
- groupByKey([numTasks]) :
在一個由(K,V)對組成的數據集上調用,返回一個(K,Seq[V])對的數據集。注意:默認情況下,使用8個并行任務進行分組,你可以傳入numTask可選參數,根據數據量設置不同數目的Task
- reduceByKey(func, [numTasks]) : 在一個(K,V)對的數據集上使用,返回一個(K,V)對的數據集,key相同的值,都被使用指定的reduce函數聚合到一起。和groupbykey類似,任務的個數是可以通過第二個可選參數來配置的。
- join(otherDataset, [numTasks]) :
在類型為(K,V)和(K,W)類型的數據集上調用,返回一個(K,(V,W))對,每個key中的所有元素都在一起的數據集
- groupWith(otherDataset, [numTasks]) : 在類型為(K,V)和(K,W)類型的數據集上調用,返回一個數據集,組成元素為(K, Seq[V], Seq[W]) Tuples。這個操作在其它框架,稱為CoGroup
cartesian(otherDataset) : 笛卡爾積。但在數據集T和U上調用時,返回一個(T,U)對的數據集,所有元素交互進行笛卡爾積。
- flatMap(func) :
類似于map,但是每一個輸入元素,會被映射為0到多個輸出元素(因此,func函數的返回值是一個Seq,而不是單一元素)
Actions具體內容
- reduce(func) : 通過函數func聚集數據集中的所有元素。Func函數接受2個參數,返回一個值。這個函數必須是關聯性的,確保可以被正確的并發執行
- collect() : 在Driver的程序中,以數組的形式,返回數據集的所有元素。這通常會在使用filter或者其它操作后,返回一個足夠小的數據子集再使用,直接將整個RDD集Collect返回,很可能會讓Driver程序OOM
- count() : 返回數據集的元素個數
- take(n) : 返回一個數組,由數據集的前n個元素組成。注意,這個操作目前并非在多個節點上,并行執行,而是Driver程序所在機器,單機計算所有的元素(Gateway的內存壓力會增大,需要謹慎使用)
- first() : 返回數據集的***個元素(類似于take(1))
saveAsTextFile(path) : 將數據集的元素,以textfile的形式,保存到本地文件系統,hdfs或者任何其它hadoop支持的文件系統。Spark將會調用每個元素的toString方法,并將它轉換為文件中的一行文本
- saveAsSequenceFile(path) : 將數據集的元素,以sequencefile的格式,保存到指定的目錄下,本地系統,hdfs或者任何其它hadoop支持的文件系統。RDD的元素必須由key-value對組成,并都實現了Hadoop的Writable接口,或隱式可以轉換為Writable(Spark包括了基本類型的轉換,例如Int,Double,String等等)
- foreach(func) : 在數據集的每一個元素上,運行函數func。這通常用于更新一個累加器變量,或者和外部存儲系統做交互
算子分類
大致可以分為三大類算子:
- Value數據類型的Transformation算子,這種變換并不觸發提交作業,針對處理的數據項是Value型的數據。
- Key-Value數據類型的Transfromation算子,這種變換并不觸發提交作業,針對處理的數據項是Key-Value型的數據對。
- Action算子,這類算子會觸發SparkContext提交Job作業。
- Spark RDD cache/persist
Spark RDD cache
1.允許將RDD緩存到內存中或磁盤上,以便于重用
2.提供了多種緩存級別,以便于用戶根據實際需求進行調整

3.cache使用

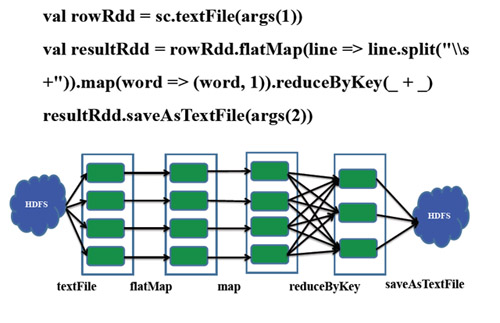
- 之前用MapReduce實現過WordCount,現在我們用Scala實現下wordCount.是不是很簡潔呢?!
- import org.apache.spark.{SparkConf, SparkContext}
- object SparkWordCount{
- def main(args: Array[String]) {
- if (args.length == 0) {
- System.err.println("Usage: SparkWordCount <inputfile> <outputfile>")
- System.exit(1)
- }
- val conf = new SparkConf().setAppName("SparkWordCount")
- val sc = new SparkContext(conf)
- val file=sc.textFile("file:///hadoopLearning/spark-1.5.1-bin-hadoop2.4/README.md")
- val counts=file.flatMap(line=>line.split(" "))
- .map(word=>(word,1))
- .reduceByKey(_+_)
- counts.saveAsTextFile("file:///hadoopLearning/spark-1.5.1-bin-hadoop2.4/countReslut.txt")
- }
- }
- 關于RDD的Transformation與Action的特點我們介紹下;
1.接口定義方式不同:
Transformation: RDD[X]–>RDD[y]
Action:RDD[x]–>Z (Z不是一個RDD,可能是一個基本類型,數組等)
2.惰性執行:
Transformation:只會記錄RDD轉化關系,并不會觸發計算
Action:是觸發程序執行(分布式)的算子。
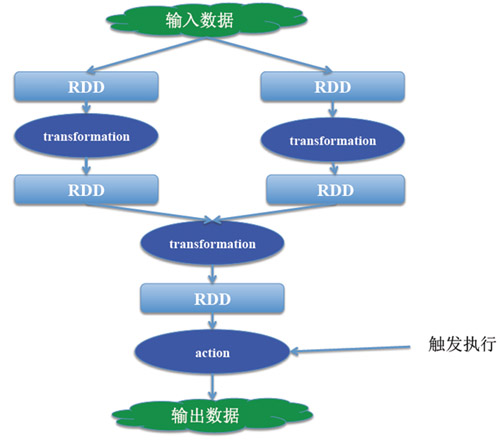
程序的執行流程:
Spark運行模式:
Local(本地模式):
1.單機運行,通常用于測試;
- local:只啟動一個executor
- local[k]:啟動k個executor
- local[*]:啟動跟cpu數目相同的executor
2.standalone(獨立模式)
獨立運行在一個集群中

3.Yarn/mesos
1.運行在資源管理系統上,比如Yarn或mesos
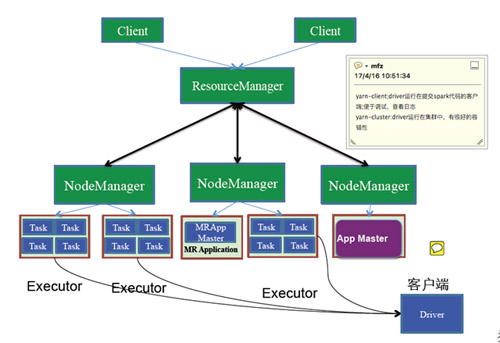
2.Spark On Yarn存在兩種模式
yarn-client
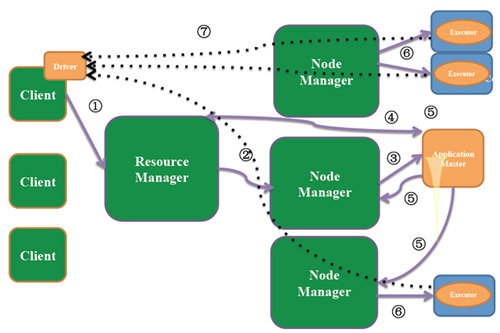
yanr-cluster

兩種方式的區別:
Spark在企業中的應用場景
- 基于日志數據的快速查詢系統業務;
構建于Spark之上的SparkSQL ,利用其快速以及內存表等優勢,承擔了日志數據的即席查詢工作。
- 典型算法的Spark實現
預測用戶的廣告點擊概率;
計算兩個好友間的共同好友數;
用于ETL的SparkSQL和DAG任務。