













Hadoop目前只是“窮人的ETL”
雖然企業部署Hadoop大數據系統的最終目的是進行“性感”的分析應用,但是大多數企業距離這一目標還很遠很遠。
根據IDC發布的Hadoop-MapReduce軟件生態系統預測報告,Hadoop市場正在以60%的年復合增長率高速擴張。但是該報告也揭示了一個讓人吃驚的事實,作為大數據分析應用的代名詞,Hadoop的流行其實與數據分析無關。實際上大多數采用Hadoop的公司都沒有將Hadoop用于大數據分析,而是把Hadoop作為一種廉價的海量存儲和ETL(抽取、轉換、加載)系統。
窮人的ETL
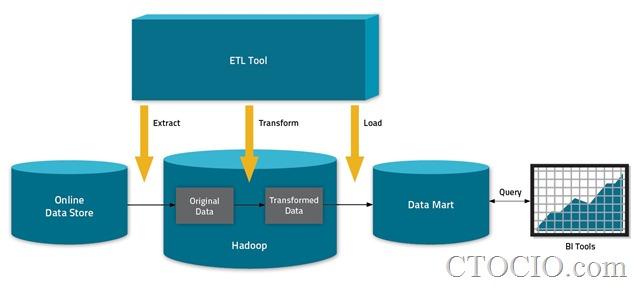
雖然被打上了“大數據分析工具”的標簽,但在大多數企業眼里,Hadoop是“窮人的ETL”。目前確實有個別企業將Hadoop用于運行激動人心的分析工作,但這只是個案。Cloudera曾提出Hadoop的三大應用模式:Transform、Active Archive和Exploration,但是業內人士分析,目前至少有75%的部署Hadoop的企業還都只是停留在前兩個模式中:將Hadoop作為廉價的ETL方案,或者用作垃圾數據填埋場(編者注:離線歷史數據倉庫,存儲海量的價值較低的歷史數據,例如淘寶光棍節的交易數據)。
Hadoop之路
Hadoop誕生已經7年了,但是Hadoop在企業中的應用還有很長的路要走。451研究所的分析師Matt Aslett在Hadoop峰會上的演講指出,企業采用Hadoop需要經歷三個發展階段,從一開始用來存儲海量數據,到對數據進行處理和轉換,到最終開始分析這些數據。我們還處于Hadoop市場和技術生命周期的早期階段,Rainstor的調查顯示,即使是***級的Hadoop用戶,也認為Hadoop***的挑戰是時間(26%)和編程(25%)。根據Gartner的調查,目前只有6%的企業開始部署大數據項目,企業還需要更多成功案例指路,同時也需要更多時間消化相關技術。
原文鏈接:http://www.ctocio.com/ccnews/12345.html


















