數據百問系列:什么是 ETL ?ETL 的常見技術方案是什么?
本文轉載自微信公眾號「 木東居士」,轉載本文請聯系 木東居士公眾號。
0x00 前言
三年前寫過一篇ETL的文章,最近又被小伙伴問到了,因此略作整理放進數據百問系列。
雖然已經過去兩三年了,ETL 領域的一些組件也都有了一些更新,但是整體來看設計的理念變化不是特別大(比如實時處理以前流行的是Spark Streaming,現在流行 Flink,而對于組件,本文也不會講解他的一些使用教程。本文更多地是分享做ETL和數據流的思考。)
文章結構
先聊一下什么是 ETL。聊一下大致的概念和一般意義上的理解。
聊一聊數據流是什么樣子。因為 ETL 的工作主要會體現在一條條的數據處理流上,因此這里做一個說明。
舉個具體的例子來說明。
0x01 什么是 ETL
ETL,是英文 Extract-Transform-Load 的縮寫,用來描述將數據從來源端經過抽取(extract)、轉換(transform)、加載(load)至目的端的過程。
嗯,怎么理解 ETL 這個東西呢?直接上一個網上搜到的招聘信息看一下:
- 職位名稱:ETL工程師
- 職位職責:
- 負責ETL系統研發和對外支持工作;
- 設計科學的數據抽取、轉換、加載的工作流程,保證數據及時、正確地抽取到數倉中;
- 負責安排ETL工程流程的調度和成功執行;
- 協調數據建模建立風控模型、對數據進行挖掘、優化及統計。
- 職位要求:
- 熟練掌握數倉方法論,理解維度建模;
- 熟悉hadoop,hive,hbase,spark,flume等工作原理;熟悉kettle,informatica,sqoop等工作;
- 精通hive語法,熟練SQL優化,熟悉python/shell等一種腳本語言;掌握mysql,oracle,sqlserver等數據庫;
- 有互聯網大數據平臺數據開發經驗優先。
看上面的要求,有幾個點可以關注一下:
數倉的理論
- 計算引擎:Hadoop、Spark、hive
- 數據同步:Flume、Sqoop、Kettle
- 存儲引擎:Mysql、Oracle、Hbase等存儲平臺
我們大致分析一下這些內容。首先說數倉的理論,這個在前面的博客也都有提到,很重要,從理論上指導了怎么來進行數據處理。存儲引擎也就不提了。這兩者不太算是 ETL 的范疇。
那就聊一下計算引擎和數據同步的工具。我們可以大致理解 ETL 的主要工作就是利用這些工具來對數據進行處理。下面舉幾個栗子來說明 ETL 的場景:
- Nginx 的日志可以通過 Flume 抽取到 HDFS 上。
- Mysql 的數據可以通過 Sqoop 抽取到 hive 中,同樣 hive 的數據也可以通過 Sqoop 抽取到 Mysql 中。
- HDFS 上的一些數據不規整,有很多垃圾信息,可以用 Hadoop 或者 Spark 進行處理并重新存入 HDFS 中。
- hive 的表也可以通過 hive 再做一些計算生成新的 hive 表。
這些都算是 ETL,其中 1 和 2 都比較典型,它們把數據從一個存儲引擎轉移到另一個存儲引擎,在轉移的過程中做了一定的轉換操作。3 和 4 也同樣是 ETL 只是它們更側重的是數據的加工。
到了這一步,我們不再糾結于具體的 ETL 概念是什么,僅從自己的直觀理解上來定義 ETL,不管嚴謹不嚴謹,反正這些活 ETL 工程師基本都要干。
ETL 是對數據的加工過程,它包括了數據抽取、數據清洗、數據入庫等一系列操作,大部分和數據處理清洗相關的操作都可以算是 ETL。
0x02 數據流長什么樣子
舉個栗子
舉個簡單的栗子,下面是一個種數據流的設計,藍色的框框代表的是數據來源,紅色的框框主要是數據計算平臺,綠色的 HDFS 是我們一種主要的數據存儲,hive、Hbase、ES這些就不再列出來了。
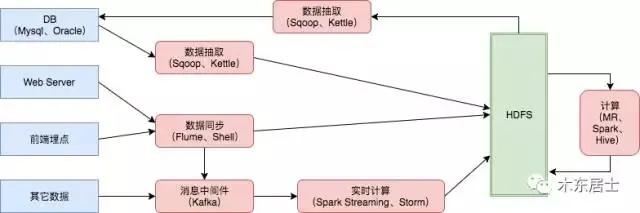
數據流的分類
我們常說的數據流主要分兩種:
- 離線數據
- 實時數據
其中離線數據一般都是 T+1 的模式,即每天的凌晨開始處理前一天的數據,有時候可能也是小時級的,技術方案的話可以用 Sqoop、Flume、MR 這些。實時數據一般就是指實時接入的數據,一般是分鐘級別以下的數據,常用的技術方案有 Spark Streaming 和 Flink。
現在的大部分數據流的設計都會有離線和實時相結合的方案,即 Lambda 架構,感興趣的同學可以了解一下。
0x03 舉個栗子
前段時間和一個哥們再聊數據流的設計,正好這里大概描述一下場景和解決方案。
一、場景
數據源主要為 Mysql,希望實時同步 Mysql 數據到大數據集群中(肯定是越快越好)。
目前每日 20 億數據,可遇見的一段時間后的規模是 100 億每日以上。
能快速地查到最新的數據,這里包含兩部分含義:從 Mysql 到大數據集群的速度快、從大數據集群中查詢的速度要快。
二、方案選型
遇到這個場景的時候,根據經驗我們主要考慮下面兩個點:數據抽取引擎和存儲引擎。
數據抽取引擎
這里我們主要考慮兩種方案:
Sqoop 定時抽取 Mysql 數據到 HDFS 中,可以每天全量抽取一份,也可以隔段時間就抽取一份變更的數據。
Canal 監聽 Mysql 的 binlog 日志,相當于是 Mysql 有一條數據久變動,我們就抽取一條數據過來。
優缺點的對比也很明顯:
- Sqoop 相對比較通用一些,不管是 Mysql 還是 PostgreSql都可以用,而且很成熟。但是實時性較差,每次相當于是啟動一個 MR 的任務。
- Canal 速度很快,但是只能監聽 Mysql 的日志。
存儲引擎
存儲引擎主要考慮 HDFS、Hbase 和 ES。
一般情況下,HDFS 我們盡量都會保存一份。主要糾結的就是 Hbase 和 ES。本來最初是想用 Hbase 來作為實時查詢的,但是由于考慮到會有實時檢索的需求,就暫定為ES
三、方案設計
最終,我們使用了下面的方案。

使用 Canal 來實時監聽 Mysql 的數據變動
使用 Kafka 作為消息中間件,主要是為了屏蔽數據源的各種變動。比如以后即使用 Flume 了,我們架構也不用大變
數據落地,有一份都會落地 HDFS,這里使用 Spark Streaming,算是準實時落地,而且方便加入處理邏輯。在 落地 ES 的時候可以使用 Spark Streaming,也可以使用 Logstach,這個影響不大
四、一些問題
有兩個小問題列一下。
小文件,分鐘級別的文件落地,肯定會有小文件的問題,這里要考慮的是,小文件的處理盡量不要和數據接入流程耦合太重,可以考慮每天、每周、甚至每月合并一次小文件。
數據流的邏輯復雜度問題,比如從 Kafka 落地 HDFS 會有一個取舍的考慮,比如說,我可以在一個 SS 程序中就分別落地 HDFS 和 ES,但是這樣的話兩條流就會有大的耦合,如果 ES 集群卡住,HDFS 的落地也會受到影響。但是如果兩個隔開的話,就會重復消費同一份數據兩次,會有一定網絡和計算資源的浪費。
0xFF 總結
仔細想了一下,數據流應該是我做的最多的一塊了,但是總結的時候感覺又有很多東西說不清楚,先簡單寫一部分。