














譯者 | 布加迪
審校 | 重樓
提取、轉換和加載(ETL)的三個階段通常涉及多個任務,每個任務都可以獨立執行。你可以將每個任務作為微服務來開發。
公司企業每天從各種業務運營中生成大量數據。比如說,每當客戶在零售店結賬時,可以在銷售點(PoS)系統獲取諸如客戶標識符、零售店標識符、結賬時間、購買物品列表和總銷售額之類的數據。同樣,現場銷售人員可能會將潛在的銷售機會錄入到電子表格中。此外,大多數商業通信是通過電子郵件進行的,這使得電子郵件成為一個大有價值的數據源。為了在整個組織保持信息的一致性,并從這些數據中獲得業務洞察力,從這些分散的數據源中提取必要的細節并保持所有的相關信息集中化就顯得至關重要。
提取、轉換和加載(ETL)技術側重于這個問題:從多個數據源提取數據,將提取到的數據轉換成所需的格式,最后將其加載到相關的數據存儲或系統中。然而,由于業務和技術的進步,ETL應用生態也在迅速發生變化。其中面臨一些挑戰:
- 使用人工智能從自然語言或非結構化數據源中提取信息。
- 使用人工智能來轉換數據。
- 與基于云的系統連接以提取或加載數據。
- 在混合云環境中靈活部署ETL流。
- ETL流的可擴展性。
- 像微服務那樣敏捷和快速地部署ETL流。
- 支持流式ETL操作。
- 針對小規模用例的低成本ETL部署。
我們在下文將討論構建這種敏捷ETL流的體系結構以及快速部署這些ETL流的方法。
用于構建敏捷ETL流的體系結構
ETL的每個提取、轉換和加載階段通常涉及多個任務。比如說,提取階段可能涉及從CSV文檔和電子郵件中提取數據的任務。與之相仿,轉換階段可能涉及刪除缺失字段的數據項、連接字段、分類以及將數據從一種格式映射到另一種格式等任務。最后,加載階段可能涉及加載到數據倉庫、更新數據庫中的數據項或將數據插入不同系統中等任務。這樣的ETL流如下圖所示:
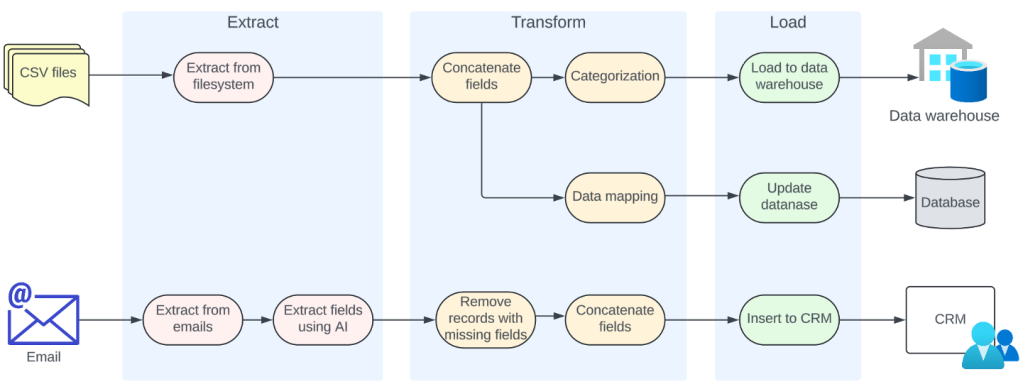
圖1
一旦提供了原始數據或另一個任務的輸出,這些任務中的每一個都可以獨立執行。因此,可以使用合適的技術實現這每一個任務,并將它們作為可獨立部署和擴展的集群加以執行。這使得我們可以將每個任務作為微服務來開發。
此外,任務之間存在依賴關系。比如說,“連接字段”任務依賴“從文件系統中提取”任務。可以使用多種方法在這類相關任務之間傳遞數據。一種簡單的方法就是使用REST API調用在這些任務之間進行聯系。然而,如果在任務之間使用消息傳遞系統,就可以促進解耦并提高可靠性。然后,每個任務使用來自消息傳遞系統中某個主題的數據,并在處理完成后將輸出數據發布到另一個主題。這種方法有諸多優點:
- 每個任務可以以自己的速度工作,而不會被前一個任務的請求過載。
- 如果任務失敗,數據不會丟失。
- 可以將另外的任務添加到ETL流中,而不會影響當前任務。
將ETL任務作為微服務來實現并通過消息傳遞層方便其通信的體系結構如下所示:
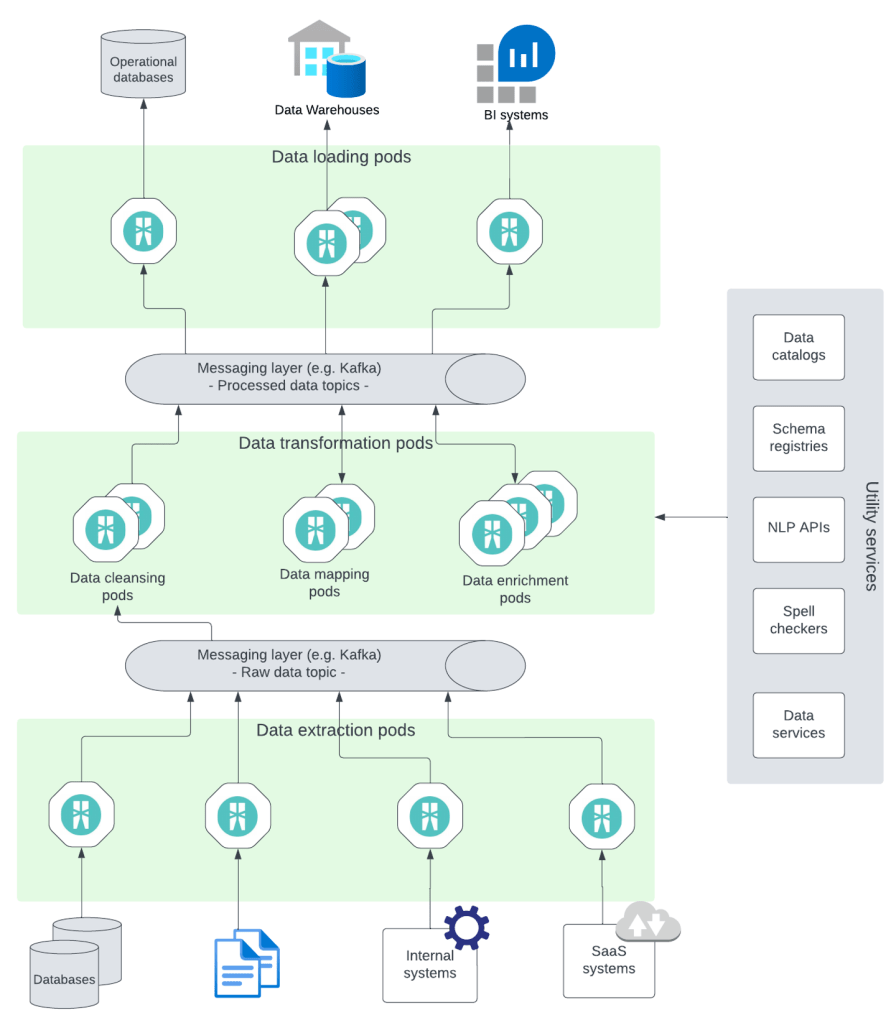
圖2
將每個ETL任務分離為微服務可以視作邏輯體系結構。在實際的實現中,可以根據可擴展性、開發團隊和預期的可擴展性需求等因素,確定是將ETL任務作為單獨的微服務來實現,還是將多個任務組合成單個微服務。
實現ETL任務
下一步是實現單獨的ETL任務。因為這每一個任務都是微服務,任何技術都可以用于實現。ETL任務通常包括三個步驟:
- 與本地數據中心和云端可用的數據存儲和外部端點集成。
- 處理龐大且復雜的數據結構。
- 通過多種格式和協議傳輸數據。
許多支持微服務風格部署的集成技術都可以用于實現ETL任務。適合此用途的一種技術是Ballerina編程語言,它是專門為集成而設計的。Ballerina直接支持服務開發、數據庫連接、通用協議、數據轉換以及多種數據類型(如JSON、XML、CSV和EDI)。此外,它還附帶大量連接件,以便與本地系統和SaaS系統集成。我們在下面將探討一些使用Ballerina開發ETL任務的示例。
數據提取
業務數據有可能放在數據庫、CSV文件、EDI文檔、電子表格或ERP應用軟件等各種企業系統中。因此,數據提取任務需要連接所有這些數據源,并使用它們支持的格式讀取數據。下面是使用Ballerina從數據庫、CSV文件和EDI文檔中提取數據的幾個示例。
- 讀取數據庫
stream orders = dbClient->/orderdata;
check from var orderData in orders
do {
io:println(orderData);
};- 讀取CSV文件
stream productDataStream = check io:fileReadCsvAsStream("product_data.csv");
check productDataStream.forEach(
function(string[] productData) {
io:println(productData);
});- 讀取EDI文檔
string ediText = check io:fileReadString("resources/purchase_order.edi");
PurchaseOrder simpleOrder = check fromEdiString(ediText);
io:println(string `Order Id: ${simpleOrder.header.orderId}`);數據提取階段可能還需要從非結構化數據源中提取數據。這方面的一個典例是從電子郵件、留言和評論中提取結構化信息。下面的例子演示了使用Ballerina和OpenAI從評論中提取好評、差評和改進建議等信息。
chat:CreateChatCompletionRequest request = {
model: "gpt-3.5-turbo",
messages: [
{
role: "user",
content: string `
Extract the following details in JSON from the reviews given.
{
good_points: string,
bad_points: string,
improvement_points: string
}
The fields should contain points extracted from all reviews
Here are the reviews:
${string:'join(",", ...summaryRequest.reviews)}
`
}
]
};
chat:CreateChatCompletionResponse summary = check openAiChat->/chat/completions.post(request);
if summary.choices.length() > 0 {
string content = check summary.choices[0].message?.content.ensureType();
io:println(content);
chat:CreateChatCompletionRequest request = {
model: "gpt-3.5-turbo",
messages: [
{
role: "user",
content: string `
Extract the following details in JSON from the reviews given.
{
good_points: string,
bad_points: string,
improvement_points: string
}
The fields should contain points extracted from all reviews
Here are the reviews:
${string:'join(",", ...summaryRequest.reviews)}
`
}
]
};
chat:CreateChatCompletionResponse summary = check openAiChat->/chat/completions.post(request);
if summary.choices.length() > 0 {
string content = check summary.choices[0].message?.content.ensureType();
io:println(content);
}數據轉換
提取的數據可能來自員工填寫的電子表格、從手寫文檔掃描而來的文本或操作員輸入到系統的數據。因此,這類數據可能含有拼寫錯誤、缺失字段、重復信息或無效數據。因此,轉換階段必須在將這些數據記錄加載到目標系統之前加以清潔。此外,可能需要在轉換階段將來自多個數據源的相關細節組合起來,以便豐富數據。下面的例子展示了使用Ballerina來完成這些任務。
- 刪除重復信息
function removeDuplicates(SalesOrder[] orders) returns SalesOrder[] {
return from var {itemId, customerId, itemName, quantity, date} in orders
group by itemId, customerId, itemName
select {
itemId,
customerId,
itemName,
quantity: [quantity][0],
date: [date][0]
};
}- 識別無效數據項
function isValidEmail(string inputString) returns boolean {
string:RegExp emailPattern = re `[A-Za-z0-9\._%+-]+@[A-Za-z0-9\.-]+\.[A-Za-z]{2,}`;
return emailPattern.isFullMatch(inputString);
}- 數據豐富
CRMResponse response = check crmClient->/crm/api/customers/'json(customerId = customer.id);
if response.status == "OK" {
customer.billingAddress = response.billingAddress;
customer.primaryContact = response.telephone;
}提取的數據常常需要在存儲到目標系統之前轉換成不同的格式。然而,ETL任務通常不得不處理由數百個字段組成的非常龐大的數據結構,這可能使數據映射成為一項乏味枯燥的任務。可以使用Ballerina的可視化數據映射功能簡化這項操作,如下所示:
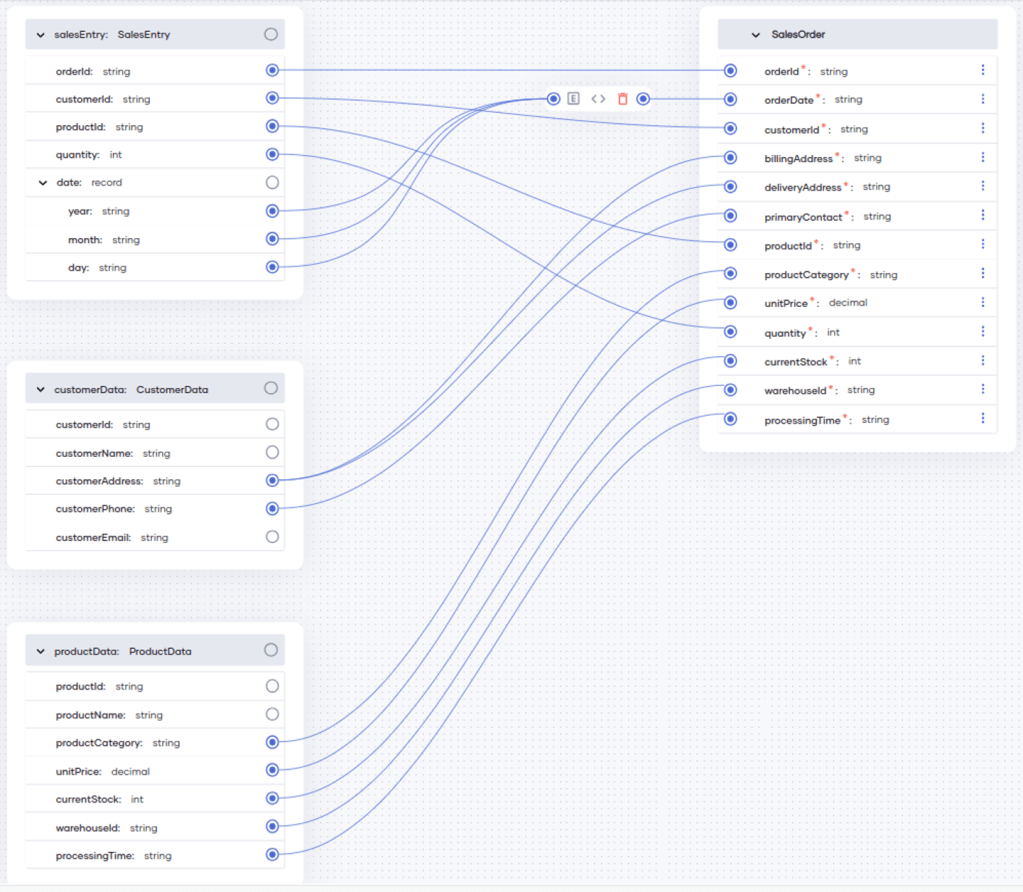
圖3
數據加載
最后,數據加載階段的任務需要連接不同的目標系統,并通過所需的協議發送數據。使用TLS和OAuth2等技術實現安全連接到這些目標系統也很重要。Ballerina有大量的連接件,并內置支持所有常見的安全標準,因而實現此類數據加載任務變得容易。下面的示例展示了如何將數據插入到Google BigQuery中。
SalesData[] salesDataset = check io:fileReadCsv("./resources/sales_data.csv");
bigquery:TabledatainsertallrequestRows[] rows = from var salesData in salesDataset
select {insertId: uuid:createType1AsString(), 'json: salesData};
bigquery:TableDataInsertAllRequest payload = {rows};
_ = check bigQueryClient->insertAllTableData(projectId, datasetId, tableId, payload);有時候,業務用戶可能希望檢查某些數據記錄,比如缺失值或無效值的數據項。就微服務體系結構而言,引入這樣一個額外的任務只需要添加一個微服務來讀取相關主題,并將數據加載到電子表格之類的最終用戶系統中。下面是一個從主題中讀取數據并將其插入到Google Sheets的示例。
sheets:Spreadsheet sheet = check spreadsheetClient->createSpreadsheet(sheetName);
_ = check spreadsheetClient->
appendValue(sheet.spreadsheetId, ["Product", "Sales", "Date"], {sheetName: workSheetName});
foreach var {product, sales, date} in salesSummary {
_ = check spreadsheetClient->
appendValue(sheet.spreadsheetId, [product, sales, date], {sheetName: workSheetName});
}部署和測試ETL流
將單個ETL任務作為微服務來開發便于將整個ETL流部署到Kubernetes集群中。每個ETL任務都可以是Kubernetes部署環境中的一個pod,從而可以根據負載大小來增加或減少單個ETL任務的pod數量。然而,組織通常有多個ETL流,每個流又涉及許多任務。此外,這些ETL流可能歸不同的團隊擁有。因此,擁有適當的CI/CD管道、權限模型、監測功能以及用于開發、測試、性能驗證和生產的多個環境至關重要。
Ballerina可以與所有常見的CI/CD、監測和部署技術一起工作,從而無縫地將基于Ballerina的ETL流與組織的現有基礎設施集成在一起。比如說,Ballerina ETL源代碼可以在GitHub中加以維護,CI/CD操作可以使用Jenkins來實現,ETL流可以部署在Amazon EKS上,執行則可以使用Prometheus和Grafana加以監測。
另一個部署選項是Choreo平臺,該平臺默認情況下提供了所有這些功能。由于Choreo讓用戶無需構建平臺,因此可以通過部署一組選定的ETL流、進行測試并將它們轉移到生產環境中,立即開啟ETL之旅。然后可以對這些ETL流進行改動,或者可以在相應的數據源存儲庫中引入新的ETL流,新的ETL流由Choreo攝取后部署到開發環境中。
結語
本文討論了靈活的、類似微服務的ETL流的體系結構和Ballerina語言實現。考慮到大多數業務部門生成數據,并有著獨特的數據需求,Ballerina語言提供的數據處理能力、連接性和靈活的部署選項可能具有變革性。Ballerina團隊目前正在竭力改進工具支持,力求使構建集成和ETL流變得更簡單。
原文標題:Developing agile ETL flows with Ballerina,作者:Chathura Ekanayake















