













流量暴漲擒兇記
某天,月黑風高,寒風凌厲。迷糊中,一陣急促的電話響起,來電告知,數個機房的帶寬暴漲,需要立即處理,否則IDC服務商要拔網線了。一看時間,大概是凌晨2點了,真悲催啊!
先登錄監控系統查看流量。平時流量最大的一個服務器的帶寬跑滿1G了(因為當時急著處理故障,沒留下截圖),而正常情況下,它的帶寬峰值穩定在600M-700M/s的樣子,如下圖所示:
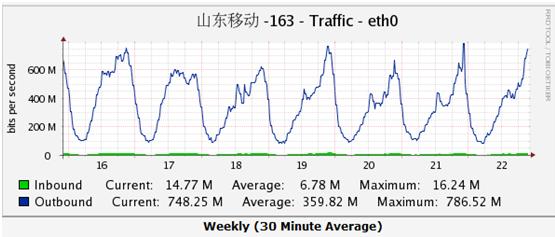
查看其它服務器,帶寬圖基本拉成一條直線,把100M跑滿了(這些機器性能差,帶寬為100M)。

盡管多個機房多個服務器帶寬都超平常很多,基本可以確定是出問題了。但心里還是不放心,擔心是cacti監控不準或者出了故障。因此又單獨登錄數個流量大的服務器,使用iptraf這樣的工具實時查看,結果真的與cacti給出的結果一致。
這是一個下載業務,總帶寬峰值大概在3Gb/s的樣子。其結構分為三層:源站、中轉層、邊緣層。其業務流程如下圖所示:
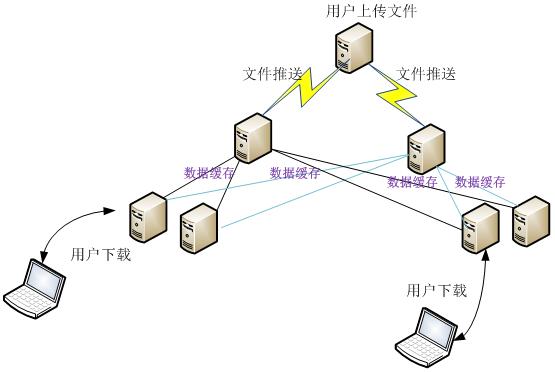
1、用戶通過web接口編輯和上傳文件到源站服務器;
2、源站用rsync同步文件到中轉服務器;
3、邊緣服務器配置成緩存,然后根據需要從中轉服務器抓取所需的對象存儲起來。
為了提高可用性和負載均衡,邊緣服務器從2個中轉服務器抓取文件。
一般來說,引起流量暴漲的原因無外乎有:遭受攻擊、網站市場推廣、系統或程序異常、木馬程序。通過詢問相關市場人員,答復說近期沒有任何市場推廣;再問程序員,有沒有修改程序或新增插件,答復都是否定的。再讓管理人員查看后臺統計數據,但統計數據并沒有跟流量同步暴增。由此判斷,出問題的原因只剩下系統異常和黑客攻擊兩種情況。被植入木馬的幾率很小:程序是通過vpn上傳的,并且只有靜態內容。
情況緊急,不可能每個服務器都登錄一片。因此先從流量最大的查起,再查流量次大的。檢查的項目包括:
(1)系統日志:看是否有內核報錯;
(2)Web日志,統計ip來源是否過于集中;
(3)查看tcp狀態,了解請求情況;
(4)用工具iptraf查看連接數最多的ip。
通過上述措施,得知連接數最多的ip不是來自用戶,而是來自服務器之間的相互請求。通過查出來的ip,登錄改服務器,看是否發生了什么?通過檢查進程、系統日志、網絡狀況都未找到原因。隨手執行了一下crontab –l 看有沒有什么自動任務,結果發現有一個腳本,而且是每10鐘執行一次。我印象中沒寫個這樣一個腳本的。打開一看,內容如下:
#!/bin/bash
Path=`grep proxy_cache_path /usr/local/nginx/conf/vhosts/apk_cache.sery.com.conf |awk '{print $2}'|sed 1d`
for i in `ls $Path`; do
grep -a -r apk $Path/$i/* | strings |grep "KEY:" >/tmp/cache_list$i.txt
grep -v apk$ /tmp/cache_list$i.txt >> /tmp/del$i.txt
\rm -rf `grep -v apk$ /tmp/cache_list$i.txt|awk -F: '{print $1}'`
#echo $Path/$i
sleep 60
done
\rm -rf /tmp/cache_list*
這個腳本要結合具體場景才能弄明白,因為某些原因,這里不再分析它;總之,這個腳本的作用,就是在緩存目錄查詢一些文件是否存在,如果存在,就刪除它。
上述操作的結果,就是緩存文件剛存在,不久就被干掉。當用戶需要下載這個文件時,邊緣服務器卻沒有緩存,因此只好回源(向中轉服務器抓取)。正常情況下,會緩存很長一段時間,但因為這個腳本,過一會又把它干掉了。這就導致不斷的大量的回源,流量就暴漲了。未避免風險,沒直接刪除這個腳本,而在crontab計劃任務里把它注釋掉。逐一在邊緣服務器排查,注釋掉這個任務。
觀察流量圖,帶寬耗費逐步下降,10-20分鐘后,趨于正常了。打一通電話后,繼續睡覺。














