Netflix開源Hadoop工具:日處理近萬作業、上千TB數據
之前的報道中,從架構的角度剖析了Netflix的大規模Hadoop作業調度工具。其儲存主要基于Amazon S3(Simple Storage Service),利用云的彈性來運行多個Hadoop集群的動態調整,從而應對不同類型的工作負載,這個可橫向擴展的Hadoop平臺即服務就被稱為Genie。而近日,這頭來自Netflix的妖怪終于被放出神燈, 于GitHub上開源 。在這里不得不感嘆一句Amazon確實該給Netflix頒發個最佳生態伙伴獎。
這頭妖怪究竟是什么
Genie提供了Hadoop環境云中的作業和資源調度,從終端用戶的角度,Genie剝離了各種Hadoop資源的物理細節,無需安裝Hadoop客戶端情況下提供了一個監視及提交Hadoop、Hive和Pig作業的途徑——REST-ful Execution Service,負責整個集群以及相關的Hive和Pig配置。
為什么要建立Genie
Netflix建立Genie的主要原因有兩個。首先是需要在云端運行不同規模的Hadoop集群來應對Netflix不同的工作負載。其中有一些是根據需要啟動的,瞬態的;舉個例子,在夜間Netflix需要啟動“bonus”Hadoop集群來增加資源做ETL(抽取、轉換以及加載)處理。還有一些不停運行的集群,比如常規的SLA及ad-hoc集群;但是有時也會停機,因為Netflix使用的是云服務,所以還受到云服務穩定性的影響。用戶通過集群名稱或者是所支持的負載類型來查找這些集群的最新版本,在數據中心這一般不成問題,因為這里的Hadoop集群不會時不時宕機,但是在云端卻是不可避免需要面對的挑戰。
其次,有些終端用戶期望運行自己的Hadoop、Hive或者Pig作業——其中很少數的人甚至期望運行自己的集群,更甚至是安裝客戶端軟件以及下載所有作業需要運行的配置。一般來說不管是數據中心還是云端都存在這種需求:使用一個可以實現很多功能的REST-ful API去運行作業,比如利用它來建立網絡UI、工作流模板以及封裝了日常所需的可視化工具。
Genie與一些工具的區別
首先,Genie不是個工作流調度程序,比如Oozie。Genie的執行單位是單一的Hadoop、Pig或者是Hive作業。Genie不會調度或者是運行工作流,事實上,Netflix使用的是一個企業版調度程序(UC4)來運行ETL。
其次,Genie不是一個任務調度程序,比如Hadoop的一些性能調度其等。Genie從本質上講是個資源“紅娘”,基于作業參數和集群性能為作業分配合適的集群。如果可供作業運行的有多個集群,Genie將隨機的對其進行分配。當然這里可以加入一個定制的負載平衡器,為作業和集群的匹配進行更好的優化;然而,目前并不存在這樣一個負載均衡器。
最后,Genie同樣不是一個終端到終端的資源管理工具,它不會提供或者是啟動一個集群,同樣也不會基于集群的利用率開啟或者關閉集群。然而Genie可以與他們合作達到更好的效果,作為一個集群的資源庫以及一個用于作業管理的API。
Genie的工作方式
下圖詳述了Genie的核心組件,以及它的兩個類型Hadoop用戶——管理員和終端用戶。
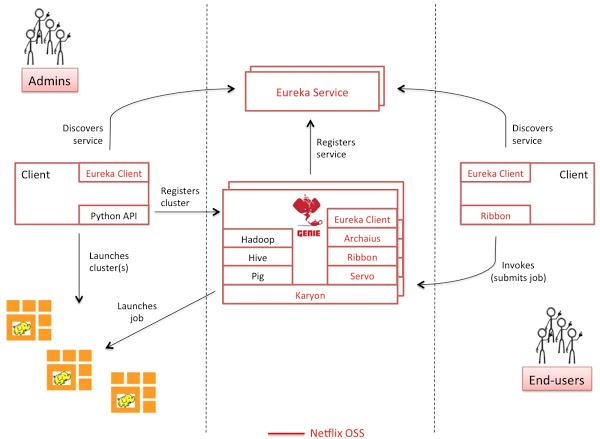
Genie本身構建于以下幾個Netflix OSS組件之上:
Karyon——提供了引導、運行時分析(runtime insight)、診斷以及為不同云準備的Hook。
Eureka——提供了服務的登記及一些搜索功能(比如搜尋活動的Genie實例)
Archaius——提供云端的動態管理特性
Ribbon——提供了Eureka的整合,以及為REST-ful提供客戶端負載均衡和進程間通信
Servo——提供了輸出測量,并通過JMX登記(Java管理擴展),并將他們發送給外部監視系統,比如Amazon的CloudWatch
Genie現已可以從GitHub上下載,并部署到一個類似Tomcat的容器中。但是僅僅這么部署并未起到太大作用,除非你為其注冊一個Hadoop集群。給Genie注冊Hadoop集群可以通過以下幾個步驟:
Hadoop管理員啟動一個Hadoop集群,比如使用EMR客戶端API。
將集群的Hadoop和Hive配置上傳到S3上的某個位置
管理員使用Genie客戶端通過Eureka來尋找一個Genie實例,調用REST-ful注冊集群的配置,這里會使用到的屬性有:唯一id、集群的名稱以及一些其它的屬性;比如它支持“SLA”作業以及“prod”元存儲。如果建立一個新的元存儲配置,同樣需要與Genie注冊一個新的Hive或者Pig配置。
當集群注冊后,Genie已經可以完成終端用戶所有的愿望——提交Hadoop、Hive和Pig作業。終端用戶使用Genie客戶端來發布和監視Hadoop作業。客戶端內部會使用Eureka去尋找一個活動的Genie實例,Ribbon則會去執行客戶端的內部負載均衡,并與服務的RESTfully通信。這里用戶需要指定的作業參數包括:
作業的類型,Hadoop、Hive或者是Pig
作業的命令行參數
S3上一組文件的依賴關系,包括腳本或者是UDF(用戶定義函數)
用戶還必須告知Genie需要選擇的集群類型。這個方面,可以有許多選擇——使用集群名稱或者是集群ID來指定特定的集群,或者使用計劃表(比如SLA)和元存儲配置(比如prod),這樣的話Genie就會根據這些參數為作業選擇一個合適的集群去運行作業。
Genie為每個作業建立了一個新的工作目錄,演算所有依賴性(包括了Hadoop、Hive以及Pig用于選擇集群的配置),然后從那個工作目錄下選擇一個Hadoop客戶端進程。接著會返回一個Genie作業ID,客戶端可以根據這個ID來查詢作業狀態,以及獲得輸出URI,可以用于作業執行期間以及執行后的查詢(詳見下圖)。用戶可以使用它來監視標準輸出以及Hadoop客戶端錯誤,在發生錯誤時同樣可以查看Hive及Pig的客戶端日志。
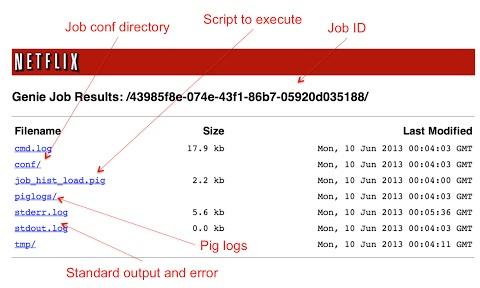
Genie的執行模型非常簡單,Genie為新工作目錄下的每個作業選擇一個新的進程。這種簡單、重要工作模式有益于每個作業之間以及與Genie的隔離,同樣也方便操作標準輸出、錯誤發生以及終端用戶作業日志(這些都可以從輸出URI中查看)。這里Netflix并沒有在Genie內部使用作業隊列,因為如果要實現Genie內部隊列的話,還必須實現共享及性能調度程序,但是這些在Hadoop層已經實現。鑒于底層是使用JVM來處理每個作業,這樣的話基于可用內存,每個Genie實例上并行執行作業的數量都是有限的。
Genie在Netflix的部署
Genie使用ASG(Auto-Scaling Group)進行橫向擴展,這樣通過Asgard進行云管理和部署,Netflix可以運行上千的Hadoop并行作業。在針對容錯設置的多個可用區域使用Asgard計算最小、渴望以及最大實例數量。對于Genie服務器推送,Asgard提供了“sequential ASG”理念,這將允許在新ASG發布后立即給新的Genie實例路由通信,并且通過關閉舊ASG切斷與舊實例的通信。
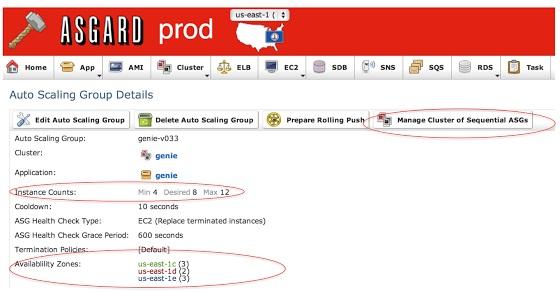
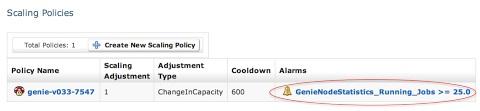
通過使用Asgard,同樣可以為動態負載設置擴展策略。下方的截圖就是一個簡單的策略,一旦所有實例上的平均作業數量大于25就會自動開啟一個Genie實例。
Genie在Netflix的實踐
Netflix已使用Genie日處理近萬的Hadoop作業,處理上千TB的數據。下圖顯示了Netflix幾個月內一些集群的概況:
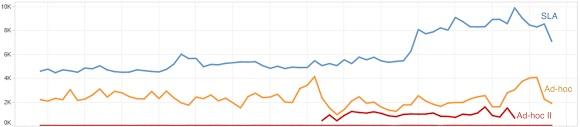
藍線代表了SLA類集群中的一個,橙線則表示一個主要的ad-hoc集群。紅線則代表了另一個ad-hoc集群,它使用了一個實驗版本的共享調度程序,而Genie會隨機給這兩個ad-hoc集群中的一個分配作業。當對新調度器帶能的性能感到滿意時,Netflix果斷在另一個更大的ad-hoc集群上投入使用(同樣用橙線表示),而所有新的ad-hoc Genie作業都被路由到這個新的集群,而兩個老集群也隨著運行作業的完成被關閉。
結束語
雖然Genie有著強大的功能,但Netflix認為Genie還有很多地方可以繼續提高;比如設計一般的數據模型,這些都帶有很強烈的Netflix及云色彩。Netflix希望能得到更多關于產品的反饋,從而進行更好的改善。