2013年迄今為止最嚴重的云計算中斷事故
2013年最嚴重的云計算中斷事故
云計算給企業和普通用戶帶來了很多好處,雖然云計算位于“天空中”,但它們也不能幸免“塵世的錯誤”。云計算用戶都知道,與任何其他類型的技術一樣,基于web的服務也會崩潰。如果這些服務背后的供應商足夠聰明,你應該不會丟失任何數據,但在服務中斷期間,你可能會受到嚴重影響。讓我們來看看,到目前為止,2013年最嚴重的云計算中斷事故。 #p#
Amazon主頁故障
日期:2013年1月31日;時間:49分鐘;亞馬遜云計算服務之前也出現過重大中斷事故,但我們很少看到該公司自己的Amazon.com主頁出故障的情況。在今年早些時候,我們就看到了這個事故:在原本平靜的一月的一天,Amazon.com頁面在長達一小時內顯示的是文本錯誤消息。從這個消息“HTTP/1.1服務不可用”來看,我們無法判斷實際發生了什么事情。有人認為這可能是拒絕服務攻擊,但這些說法似乎有些可疑。雖然Amazon從未對此事故正式發表評論,但隨后的報告表明罪魁禍首很有可能是其內部問題。 #p#
Amazon事故影響
Amazon等在線零售商必須確保在線狀態以確保業務的正常運作。從該公司之前的季度盈利來看,一些行業觀察家估計,一小時的離線時間可能讓該公司錯失了近500萬美元的收入。Amazon并沒有透露他們是如何讓業務恢復正常運轉,只是指出這次故障只影響了其主頁,而沒有影響內頁,對其AWS云托管操作并沒有影響。 #p#
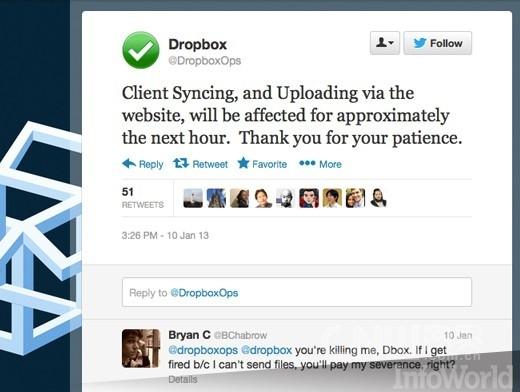
Dropbox服務中斷
日期:2013年1月10日;時間:約16小時;Dropbox服務的主要賣點是你可以將它視為你的本地硬盤驅動器,所以,當該服務一整天不可用時,后果將不堪設想。今年1月10日就發生了這樣的事情:大約在太平洋時間下午3:30,Dropbox承認其服務出現故障,該公司通過Twitter告訴客戶,所有客戶端同步和文件上傳將在“接下來的一小時內”不可用。直到第二天早上7:09,這個問題才得到了解決。 #p#
Dropbox事故影響
面對這個事故,使用Dropbox滿足其文件存儲需求的用戶感到非常失望,Dropbox用戶在Twitter上表達了他們的不滿。一名用戶說:“Dropbox崩潰了,用戶開始意識到,不能100%相信云計算服務。”Dropbox并沒有透露這個事故的具體原因,但是Amazon發出聲明,聲稱這次事故與其亞馬遜云計算服務沒有任何關系。 #p#
Facebook網站中斷
日期:2013年1月28日。時間:兩到三個小時;在1月28日早上,全球各地的Facebook用戶發現他們無法更新其朋友的狀態信息。大量用戶經常訪問Facebook網站,因此,數小時的停機時間不可能不會被發現。本月早些時候,黑客組織Anonymous發布了一段視頻,聲稱其要攻擊Facebook,并在上述同一天讓Facebook中斷。究竟發生了什么? #p#
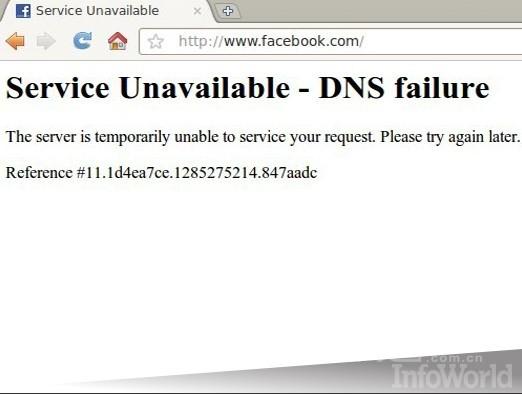
Facebook事故影響
在長達兩到三小時內,人們無法獲取其朋友的狀態更新。Facebook聲稱,這次停機事故源自一個DNS問題,這個問題“阻止在瀏覽器輸入facebook.com的用戶訪問到該網站”,這是很容易解決的問題,并沒有任何跡象表明Anonymous參與了這個活動。這次事故只是影響了Facebook的桌面網站,而該公司的移動網站和應用程序則沒有受到影響。 #p#
Microsoft服務中斷,第一波
日期:2013年2月1-2;時間:約兩個小時;對于微軟來說,二月是艱難的一個月份。在2月1日,該公司的Office 365編輯套件和Outlook.com郵件服務都中斷了,用戶在約兩小時內無法訪問這兩個服務。一天后,微軟的Bing搜索引擎也遭受了近兩小時的停機,我們該怎么辦?當然是改用谷歌。 #p#
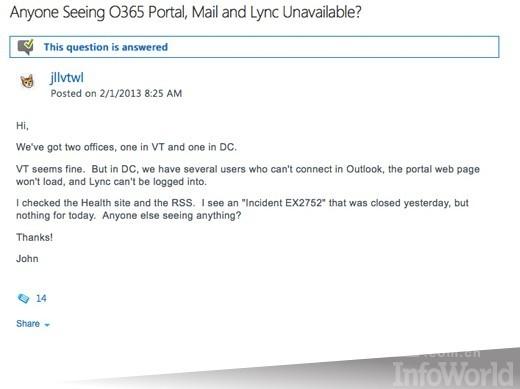
Microsoft事故影響
對于Office 365和Outlook.com故障,用戶論壇和社交媒體網站都充滿了用戶的抱怨。而對于Bing故障問題,依賴于Bing的用戶肯定非常失望。根據微軟表示,這次中斷事故是“日常維護出錯”的原因。更具體地說,這個問題的根本原因是“設定的網絡配置更改”,通過部署“必要的修復措施”就能夠減輕該事故的影響。 #p#
Microsoft服務中斷,第二波
日期:2013年2月22日;時間:超過12小時;與第二次中斷事故相比,第一次簡直是小巫見大巫。在2月22日晚上,該公司的Windows Azure云存儲服務中斷,所有安全訪問時序輸出功能都不可用。其他微軟服務(例如Xbox Live、Xbox Music和Xbox Video)也開始出問題,用戶無法訪問云計算連接的數據或者利用任何捆綁到這些服務的多媒體內容。 #p#
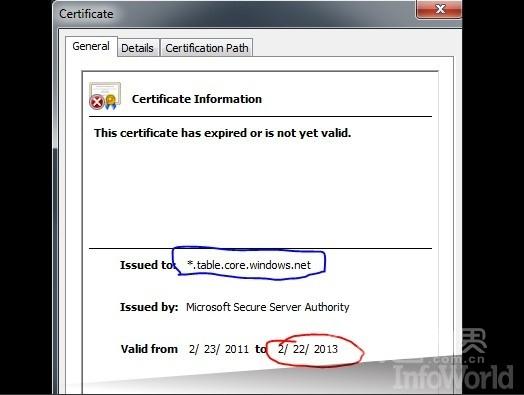
Microsoft事故影響
論壇和社交媒體網站再次充滿了客戶的抱怨。 微軟透露過期的SSL證書是這次故障的根本原因(真的嗎?!)。兩次中斷事故,實在是讓人頭疼。 #p#
Google Drive
日期:2013年3月18-19日,時間:約17小時;在3月18日星期一,很多用戶在試圖訪問其Drive文檔和文件時,出現加載緩慢或者超時的情況,這大約持續了約三小時。一天后,第二次Google Drive中斷讓一些用戶在約兩小時內無法訪問該服務。這兩天后,Drive再次停機12小時,這真的讓用戶非常惱火。 #p#
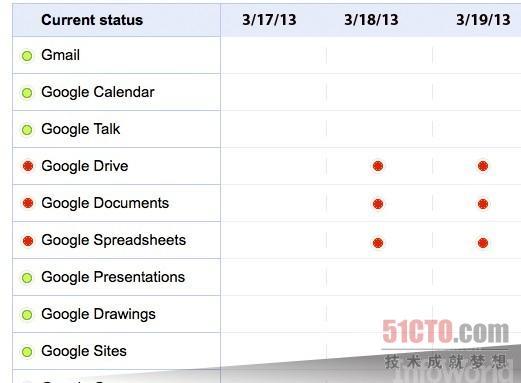
Google Drive事故影響
可以想象,論壇和社交網站又是各種抱怨。谷歌稱最初的問題與該公司的網絡控制軟件中的故障有關。該系統顯然沒有負載均衡,導致該公司的服務器出現不必要的延遲。而這反過來又導致Drive的連接管理系統出現問題。谷歌承諾將修復這個漏洞,調整其負載均衡設置,確保其網絡服務之間“更大的隔離度”。該公司還調整了其Drive軟件來讓該服務在面對延遲和恢復時“更具彈性”。 #p#
CloudFare網站崩潰
日期:2013年3月3日;持續時間:大約一個小時;CloudFare的業務主要圍繞幫助客戶保護和加速網站,但在3月3日早上,該公司自己的網站以及所有的服務都出現故障,導致785000個其他網站崩潰,包括Wikileaks、4chan以及一些政府網站。 #p#
CloudFare事故影響
在大約一小時內,當你試圖訪問任何CloudFare連接的網站時,你都會得到一個“無法路由到主機”的錯誤信息。CloudFare公司聲稱邊緣路由器(連接CloudFare的系統到互聯網)的系統故障是這次事故的主要原因。雖然幾臺路由器的崩潰通常會導致流量轉移,但在這種情況下,一個漏洞能讓每臺路由器脫機。工程師發現了有問題的代碼,清除掉了代碼,然后需要等待14個不同國家的23個數據中心重新啟動所有路由器。 #p#
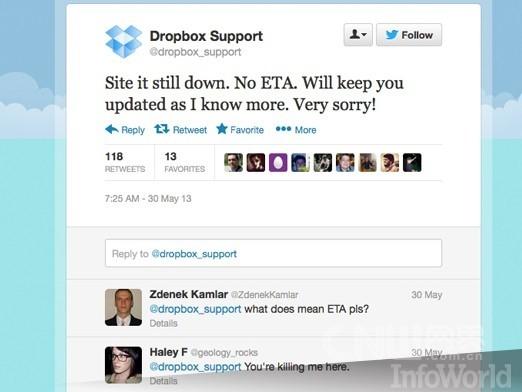
Dropbox再次出現故障
日期:2013年5月30日;時間:約90分鐘;在五個月正常運轉之后,Dropbox在5月底又出現了故障。這次,該服務中斷約90分鐘,讓客戶無法訪問其文件或者上傳任何新的材料。 #p#
Dropbox事故影響
在經歷1月份16小時的宕機事故后,人們似乎有點能夠接受該服務再次宕機的事實。幸運的是,這次事故并沒有持續太長時間。面對2013年第二次故障,Dropbox比上次更加沉著,只是表示其服務已經恢復正常,并對易造成的任何不便,表示道歉。 #p#
Twitter服務中斷
日期:2013年6月3日;時間:約45分鐘6月3日,Twiter用戶無法訪問該服務來發送或讀取內容。在大約25分鐘后,服務有所恢復,但仍然很緩慢。 #p#
Twitter事故影響
在Twitter無法使用的時段時間,Google+可能出現了高峰,所有的人都在詢問其他人Twitter是否可用。Twitter表示在發送Fail Whale到該網站的“日常更改”中出現了一個錯誤。工程師在確定這個問題后,取消了這個錯誤的更改,服務很快就恢復了正常。(鄒錚編譯)感謝觀看!希望中斷事故越來越少。