













帶你簡易入門一致性算法Raft
本文轉載自微信公眾號「架構精進之路」,作者張張 。轉載本文請聯系架構精進之路公眾號。
hello,大家好,我是張張,「架構精進之路」公號作者。
最近跟團隊同學聊到了一致性算法Raft,于是翻了下之前發布整理過的文章,重新溫故學習之。
一、Raft算法概述
當我們只有一個服務節點的情況下,是不存在節點共識的問題的,當存在多個不同服務節點時,才會引入分布式一致性的問題。
Raft是一種實現分布式共識的協議。所謂共識,就是多個節點對某個事情達成一致的看法,即使是在部分節點故障、網絡延時、網絡分割的情況下。
主要應用場景:
- Redis Sentinel的選舉Leader
- Etcd 主要是共享配置和服務發現,實現一致性使用了Raft算法
- 加密貨幣(比特幣、區塊鏈)的共識算法
主要解決什么問題?
分布式存儲系統通常通過維護多個副本來提高系統的可用性,帶來的代價就是分布式存儲系統的核心問題之一:維護多個副本的數據一致性。
二、Raft算法實現流程
為了提高理解性,Raft將一致性算法分為了幾個部分,包括領導選取(leader selection)、日志復制(log replication)、安全(safety),并且使用了更強的一致性來減少了必須需要考慮的狀態。
本文通過一個小故事做示例,來便于大家快速理解。
2.1 Leader選舉
部門需要成立一個新的服務小組,現在有三名同學A,B,C。
為了便于后期統一調配資源及管理需要,現需要從三名同學中選舉出一名小組Leader。
A覺得自己有能力做好Leader職務,就向B、C說“來投票給我,我想當Leader”,這時候A成了候選人,并為自己事先投了一票。
1)假如B、C之前都沒有想過要自己當Leader,那就說“好吧,投給你” → A獲得3張選票,當選Leader
2)假如B之前想過自己當Leader,B投了自己一票 而C投了一票給A → A獲得2張選票(3人中已超過半數),當選Leader
3)假如B、C都已經把票投給了自己 → A、B、C各獲得自己的一票,選舉失敗重新發起
4)假如B之前想過自己當Leader,而且C已經把票投給了B → B獲得2張選票(3人中已超過半數),當選Leader
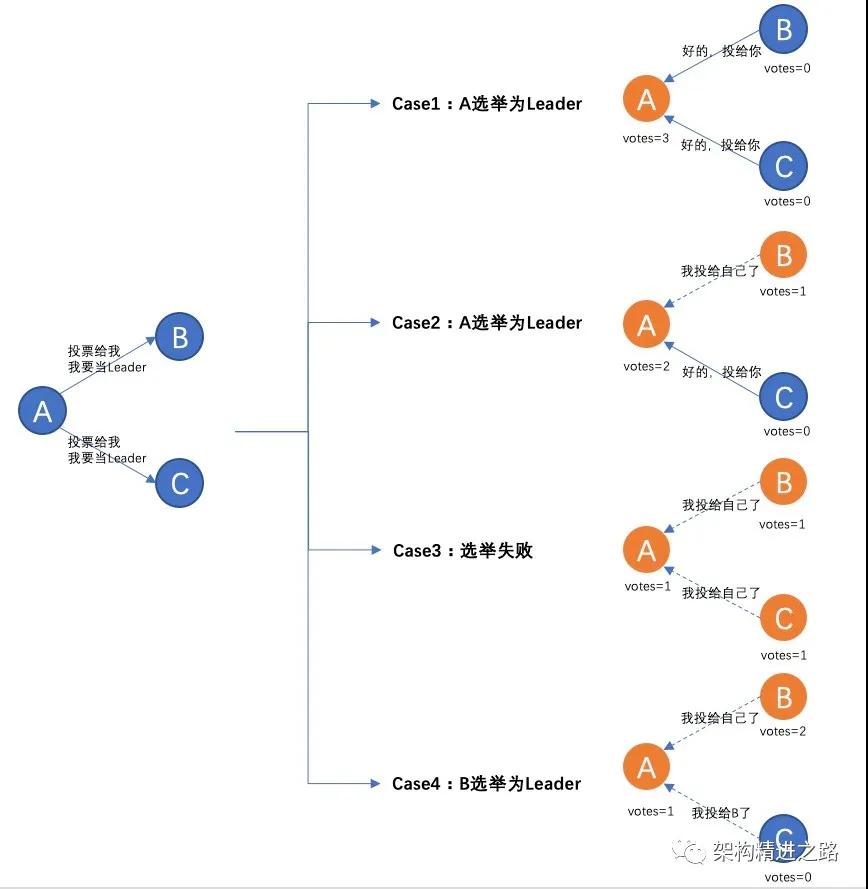
從以上選舉流程可以發現,一個節點任一時刻肯定處于以下三狀態之一:
- Leader(領導者)
- Follower(跟隨者)
- Candidate(候選人)
這三個狀態的轉移過程如下圖所示:
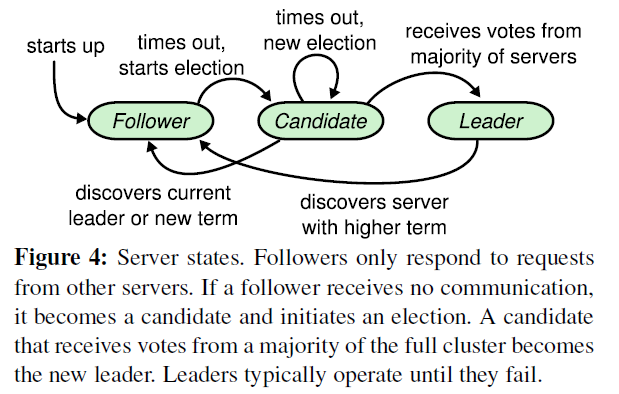
選舉過程
第一步:Follower成為Candidate
如果Follower聽不到Leader的意見,他們就可以成為Candidate
第二步:候選人爭取票
投自己一票,并發送投票請求到其他節點,節點收到請求后進行回應
第三步:等待其他節點回復
如果候選人得到了超半數的節點的投票(包含自己的一票),它就成為Leader
如果候選人被告知Leader已產生,則自行切換為Follower
一段時間內沒有收到超半數投票,保持候選人狀態,重新發起選舉
第四步:候選人 贏得選舉
新Leader會立刻給所有節點發消息,避免其他節點觸發新的選舉。
2.2 日志同步
在經過上述2.1 的Leader選舉之后,已經選定了小組Leader,這里我們假定A已當選Leader。可以承擔一些對接方同學(稱為Client 端)提出的操作任務了。
規定每次需求對接,必須要經過小組Leader才可以。那員工提出操作請求,Leader接收到后記錄下來,同時向組內其他同學進行同步,直到其他同學都確認了此需求后Leader才會確認操作并同步執行結果到員工(Follower節點)。
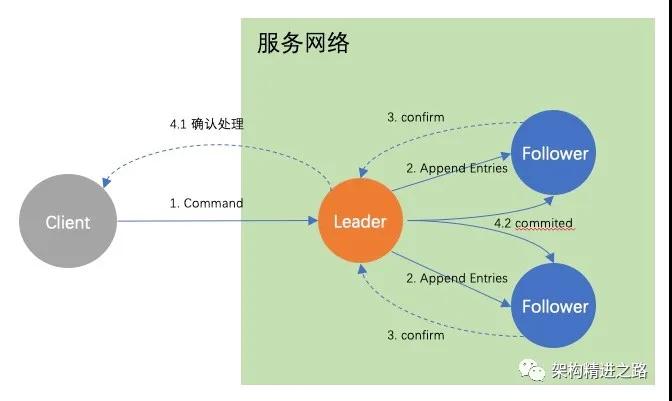
Log Replication(日志復制)
經過Leader選舉流程,產生了新的Leader節點,系統的所有變更都要通過Leader節點來實現。
第一步:Leader追加日志項(append log entry)
系統的每個更改都作為一個entry 添加到節點的日志中
第二步:Leader并行發出Append Entries RPC,并等待響應
Leader會一直等到超半數節點都寫入entry,Leader節點提交,然后Leader通知Follower entry已提交。
第三步:Leader得到大多數回應,向狀態機應用entry
狀態機:可理解為一個確定的應用程序,所謂確定是指只要是相同的輸入,那么任何狀態機都會計算出相同地輸出。
第四步:Leader回復Client,同時通知Follower應用log
目前集群已就系統狀態達成了共識
log-based replicated state machine示意圖:
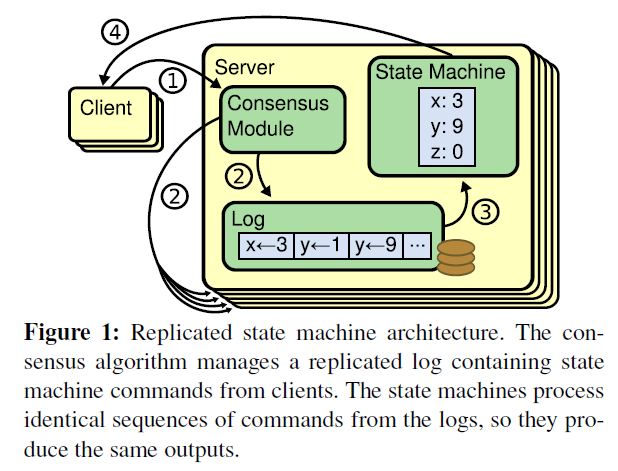
關于應用過程中的幾個問題
Q1
假如Client 請求訪問到了Follower節點怎么辦?
解答:Follower節點會轉發請求到Leader節點。
Q2
當Leader與Follower的日志不一致,需要如何處理?
解答:
1)Leader通過強制Followers復制它的日志來處理日志的不一致,Followers上的不一致的日志會被Leader的日志覆蓋。
2)Leader為了使Followers的日志同自己的一致,Leader需要找到Followers同它的日志一致的地方,然后覆蓋Followers在該位置之后的條目。
3)Leader會從后往前試,每次AppendEntries失敗后嘗試前一個日志條目,直到成功找到每個Follower的日志一致位點,然后向后逐條覆蓋Followers在該位置之后的條目。
2.3 安全性保障
為了保證團隊運行的穩定,有幾個默認的要求:
2.3.1 選舉安全
即任一任期內最多一個leader被選出。假如系統中同時有多于一個leader,被稱之為腦裂(brain split),這會導致數據的覆蓋丟失。
一個團隊某個時期內僅允許存在一個Leader(選舉失敗情況特殊情況除外),否則多個Leader同時處理需求發號施令,容易造成團隊內步調不一致情況。
在raft中,兩點保證了這個屬性:
1)一個節點某一任期內最多只能投一票;
2)只有獲得majority投票的節點才會成為leader。
2.3.2 Log 匹配完整性
同一團隊內兩名同學假如目前手頭負責的事務是一致的,那之前他們的工作記錄應該也是一致的。即:相同的初始狀態+相同的操作=相同的結束狀態
Leader將客戶端請求封裝到一個個的log entry,將這些log entries復制到其他Follower節點,大家按順序應用這些請求,那最終狀態肯定是一致的。
Raft日志同步結論:
1)如果不同日志中的兩個條目有著相同的索引和任期號(term),則它們所存儲的命令是相同的。
2)如果不同日志中的兩個條目有著相同的索引和任期號(term),則它們之前的所有條目都是完全一樣的。
2.3.3 leader數據完整性
團隊內后繼的leader,肯定應該知曉這個團隊之前的工作內容,因為所有Leader任期內的工作記錄是會做交接的。
如果一個log entry 在某個任期被提交,那么這條log一定會出現在所有更高term的leader的日志里面。
Raft日志覆蓋規則:
1)一個日志被復制到majority節點才算committed
2)一個節點得到majority的投票才能成為leader,而節點A給節點B投票的其中一個前提是,B的日志不能比A的日志舊。
三、總結
所有的算法實現原理,其實都是真實社會工作模式的影射,聯系生活中的實際案例來理解復雜的一致性算法,可以讓我們達到事半功倍的效果。
本文旨在讓大家對raft協議有一個簡單了解入門,如有興趣去更深入了解,推薦給大家兩個不錯的鏈接:
1)Raft可視化測試以及各語言版本實現的Raft:https://raft.github.io/
2)Raft算法-動畫演示(很好的入門教程):http://thesecretlivesofdata.com/raft/




















