原子操作 vs 非原子操作
在網上已經有很多有關介紹原子操作的內容,通常都是注重于原子讀-修改-寫(RMW)操作。然而,這些并不是原子操作的全部,還有同樣重要的原子加 載和原子存儲。在這篇文章中,我將要在處理器級別和C/C++語言級別兩個方面來對比原子加載和原子存儲與它們相應的非原子部分。沿著這條路,我們將弄清 楚C++11中“數據競爭”這個概念。
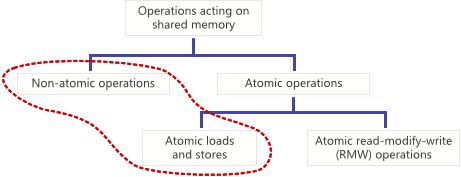
共享內存中的原子操作是指它是否完成了一個線程相關的單步操作。當一個原子存儲作用于一個共享變量時,其他的線程不能監測到這個未完成的修改值。當 一個原子加載作用于一個共享變量時,它讀取到這個完整的值,就像此時出現了一個單獨的時刻,而非原子加載和存儲則不能做到這些保證。
如果沒有這些保證,無鎖編程將不可能實現,因為你不能使不同的線程同時操作一個共享變量。我們可以制定如下規則:
任何時刻兩個線程同時操作一個共享變量,當其中一個為寫操作時,這兩個線程必須使用原子操作。
如果你違反這條規則,并且每個線程都使用非原子操作,你將會看到C++11標準中提到的數據競爭(不要混淆于Java中數據競爭的概念,這個是不同的,或者說是更廣義上的競爭情況)。C++11標準并沒有告訴你為什么數據競爭是糟糕的,但只要你出現這種情況,就會發生“未定義行為”(1.10.21部分)。這種糟糕的數據競爭的原因是非常簡單的:它們導致了讀寫撕裂。
一個內存操作可以是非原子的,因為它使用非原子的多CPU指令,即使當使用單CPU指令時也是非原子的,因為你不能簡單的設想你寫出的可移植代碼。讓我們來看幾個例子。
非原子性是由于多CPU指令
假設你有一個64位初始化為0的全局變量。
- uint64_t sharedValue = 0;
在某些時刻,你給這個變量賦一個64位的值。
- void storeValue()
- {
- sharedValue = 0x100000002;
- }
當你在32位的x86環境下使用GCC來編譯這個函數時,將會生成如下機器碼。
- $ gcc -O2 -S -masm=intel test.c
- $ cat test.s
- ...
- mov DWORD PTR sharedValue, 2
- mov DWORD PTR sharedValue+4, 1
- ret
- ...
這個時候你就會看到,編譯器會使用兩個單獨的機器指令來完成這個64位的賦值。第一條指令設置低32位的0×00000002,第二條指令設置高32位的0×00000001.非常明顯,這個賦值操作是非原子的。如果共享變量同時被不同的線程存取,就會出現很多錯誤:
- 如果一個線程在兩個機器指令的間隙先調用存儲變量,將會在內存中留下像0×0000000000000002這樣的值——這是一個寫撕裂。在這個時候,如果另一個線程讀取共享變量,它將會接收到一個完全偽造的、沒有人想要存儲的值。
- 更糟糕的是,如果一個線程在兩個機器指令的間隙先占用變量,而另一個線程在第一個線程重新獲得這個變量之前修改了sharedValue,那將導致一個永久性的寫撕裂:一個線程得到高32位,另一個線程得到低32位。
- 在多核設備上,并不是只有先行占有其中一個線程來導致一個寫撕裂。當一個線程調用storeValue時,任何線程在另一個核上可能同時讀取一個明顯未修改完的sharedValue。
同時讀取sharedValue會帶給它一系列的問題:
- uint64_t loadValue()
- {
- return sharedValue;
- }
- $ gcc -O2 -S -masm=intel test.c
- $ cat test.s
- ...
- mov eax, DWORD PTR sharedValue
- mov edx, DWORD PTR sharedValue+4
- ret
- ...
這里也一樣,編譯器會使用兩條機器指令來執行這個加載操作:第一條讀取低32位到eax,第二條讀取高32位到edx。在這種情況下,如果對于sharedValue進行同時存儲則會發現,它將導致一個讀撕裂——即使這個同時存儲是原子的。
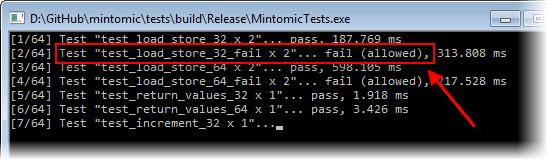
這個問題并不是理論上的,Mintomic的 測試集包含了一個名為test_load_store_64_fail的測試案例,在這個案例中,一個線程使用一個普通的賦值操作,存儲了很多64位的值 到一個單獨的變量,同時另一個線程對這個變量反復地執行一個簡單的加載,來確認每一個結果。在一個多核的x86機器上,這個測試像我們想象的一樣一直失 敗。
#p#
非原子的CPU指令
一個內存操作可以是非原子的,甚至是當由一個單CPU指令來執行的時候。例如,ARMv7指令設置包含了將兩個由32位源寄存器的內容存儲到內存中的一個64位值的strd指令。
- strd r0, r1, [r2]
在一些ARMv7處理器中,這條指令是非原子的。當這個處理器遇到這條指令時,它實際上在底層執行兩個單獨的32位存儲(A3.5.3部分)。再來 一次,另一個線程在一個單獨的核上運行,有可能觀察到一個寫撕裂。有趣的是,寫撕裂更可能出現在一個單核的設備上:例如,一個預定線程的上下文切換的系統 中斷,確實可以執行在兩個內部的32位存儲之間!在這種情況下,當這個線程從這個中斷恢復時,它將再一次重新調用這個strd指令。
再看另一個例子,眾所周知,在x86環境下,如果內存操作數是自然對齊的,那么一個32位的mov指令就是原子的,但如果不是自然對齊,那么將是非 原子的。換句話說,原子性的保證僅僅是當一個32位整數的地址正好是4的倍數的時候。Mintomic提出另一個證實這個保證的測試案 例,test_load_store_32_fail。就像寫的那樣,這個測試在x86總是成功的,但是如果你修改這個測試,強制將sharedInt置 于一個未對齊的地址,它將失敗。在我的Core 2 Quad Q6600上,這個測試失敗了,因為sharedInt在一個寄存器中越界了。
- // Force sharedInt to cross a cache line boundary:
- #pragma pack(2)
- MINT_DECL_ALIGNED(static struct, 64)
- {
- char padding[62];
- mint_atomic32_t sharedInt;
- }
- g_wrapper;
現在已經有很多特定于處理器的細節,讓我們再來看看C/C++語言級別的原子性。
所有的C/C++操作被認定為非原子的
在C和C++中,所有操作被認定是非原子的,甚至是普通的32位整數賦值,除非被別的編譯器或者硬件供應商指定。
- uint32_t foo = 0;
- void storeFoo()
- {
- foo = 0x80286;
- }
這個語言標準并沒有提到任何有關于這種情況下的原子性。也許整型賦值是原子的,也許不是。因為非原子操作沒有做任何保證,在C定義中,普通整型賦值是非原子的。
實際上,我們對我們的目標平臺了解的更多。例如,大家都知道在現在的x86、x64、Itanium、SPARC、ARM和PowerPC處理機 上,只要目標變量是自然對齊的,那么普通32位整型賦值就是原子的,你可以通過查詢你的處理機手冊或者編譯器文檔來證實。在游戲行業,我可以告訴你很多關 于32位整型賦值依賴這個特殊保證的例子。
盡管如此,但在寫真正的可移植的C和C++代碼時,有一個歷史悠久的傳統,就是我們所知道的僅僅是語言標準告訴我們的。可移植的C和C++代碼的設 計是為了可以運行在任何可能的計算設備上,過去的、現在的以及虛擬的。就我自己而言,我想設計一種機器,它的內存僅僅可以通過先到先得來改變:

在這樣的機器上,你絕對不會想要在執行一個并發的讀操作的同時執行一個普通的賦值,你可以結束讀取一個完整的隨機值。
在C++11中,有一個最終的方案來執行實際的可移植原子加載和存儲——C++11原子庫。通過使用C++11原子庫來執行原子加載和存儲,甚至可以運行在虛擬的計算機上,即使這意味著C++11原子庫必須默默地加一個互斥量來確保每一個操作都是原子的。這里還有我上個月發布的Mintomic庫,它并不支持這么多平臺,但是可以運行在很多以前的編譯器上,它是優化過的,并且保證是無鎖的。
寬松的原子操作
讓我們回到前面那個sharedValue例子最開始的地方,我們將用Mintomic重寫它,這樣所有的操作就可以原子地執行在任何Mintomic支持的平臺上了。首先,我們必須聲明sharedValue為Mintomic原子數據類型中的一個。
- #include <mintomic/mintomic.h>
- mint_atomic64_t sharedValue = { 0 };
mint_atomic64_t類型保證了在所有平臺上原子存取的正確內存對齊。這是非常重要的,因為,例如ARM的GCC4.2編譯器附帶的Xcode3.2.5并不保證普通的uint64_t以8字節對齊。
對于storeValue,通過執行一個普通的、非原子的賦值來替代,我們必須調用mint_store_64_relaxed。
- void storeValue()
- {
- mint_store_64_relaxed(&sharedValue, 0x100000002);
- }
相似的,在loadValue中,我們調用mint_load_64_relaxed。
- uint64_t loadValue()
- {
- return mint_load_64_relaxed(&sharedValue);
- }
使用C++11的術語,這些函數現在不存在數據競爭。當并發操作執行時,無論代碼運行在ARMv6/ARMv7 (Thumb或者ARM模式)、x86、x64 或者PowerPC上,絕對不可能出現讀寫撕裂。你是否好奇mint_load_64_relaxed和mint_store_64_relaxed是如 何工作的,這兩個函數在x86上都是擴展到一個內聯的cmpxchg8b指令上,對于其他平臺,請查詢Mintomic的實現。
在C++11中明確的寫出了類似的代碼:
- #include <atomic>
- std::atomic<uint64_t> sharedValue(0);
- void storeValue()
- {
- sharedValue.store(0x100000002, std::memory_order_relaxed);
- }
- uint64_t loadValue()
- {
- return sharedValue.load(std::memory_order_relaxed);
- }
你會注意到,在Mintomic和C++11的例子中都使用了寬松的原子性,由_relaxed后綴的多個標識符來證明。_relaxed后綴暗示了,就像普通的加載和存儲一樣,沒有內存訪問排序的保證。
一個寬松的原子加載(或存儲)和一個非原子加載(或存儲)之間的唯一區別就是,寬松的原子操作保證了原子性,沒有其他區別來保證。
特別的,在程序指令中,一個寬松的原子操作,被它前面或者后面的指令由于處理機本身任何一個因為編譯器重新排序或者內存重新排序所產生的影響,對內存來說依然是合法的。編譯器甚至可以在冗余的寬松原子操作上執行優化,就像非原子操作一樣。就一切情況而言,這些操作仍然是原子的。
當并發操作同時共享內存時,我認為,一直使用Mintomic或者C++11原子庫函數是非常好的練習,甚至當你知道在你的目標平臺上,一個普通的加載或者存儲已經是原子的情況下。一個原子庫函數就像提示這個變量是并發數據存儲的目標。
我希望,現在大家可以更清楚的知道,為什么《世界上最簡單的無鎖哈希表》使用Mintomic庫函數來并發地操作不同線程的共享內存。
原文鏈接:http://preshing.com/20130618/atomic-vs-non-atomic-operations/