













Ceph :一個 PB 規模的 Linux 分布式文件系統

Linux 持續進軍可伸縮計算領域,尤其是可擴展存儲領域。 Linux 文件系統最近新增了一個引人注目的選擇 —— Ceph,一個維持 POSIX 兼容的同時還集成了復制、容錯的分布式文件系統。探討 Ceph 的架構,可以知道它是如何提供容錯性,及如何簡化大量數據的管理的。
作為存儲行業的架構師,我對文件系統情有獨鐘。這些系統是存儲系統的用戶接口,盡管它們都傾向于提供相似的特性集,它們還是會提供引人注目的不同點。Ceph 也如此,它提供了一些你會在文件系統中找到的最有趣的特性。
Ceph 始于加州大學圣克魯茲分校的 Sage Weil 的博士學位課題。但從 2010 年 3 月下旬起,你可以 Linux 主流內核中找到 Ceph (從 2.6.34 內核起)。
盡管 Ceph 可能還未對生產環境做好準備,但它依然有助于評估目的。本文探討了 Ceph 文件系統,及其成為可擴展分布式存儲的誘人選擇的獨到之處。
Ceph 目標
開發文件系統是一種復雜的投入,但是如果能準確的解決問題的話,則擁有著不可估量的價值。Ceph 的目標可以簡單的定義為:
- 容易擴展到 PB 量級
不同負荷下的高性能 (每秒輸入輸出操作數 [IPOS]、帶寬)
- 可靠性高
不幸的,這些目標彼此間矛盾(例如,可擴展性會減少或阻礙性能,或影響可靠性)。Ceph 開發了一些有趣的概念(例如動態元數據分區、數據分布、復制),本文會簡單探討。Ceph 的設計也集成了容錯特性來防止單點故障,并假定,大規模(PB 級的存貯)的存儲故障是一種常態,而非異常。最后,它的設計沒有假定特定的工作負荷,而是包含了可變的分布式工作負荷的適應能力,從而提供最佳的性能。它以 POSIX 兼容為目標完成這些工作,允許它透明的部署于那些依賴于 POSIX 語義的現存應用(通過 Ceph 增強功能)。最后,Ceph 是開源分布式存儲和 Linux 主流內核的一部分(2.6.34)。
Ceph 架構
現在,讓我們先在上層探討 Ceph 架構及其核心元素。之后深入到其它層次,來辨析 Ceph 的一些主要方面,從而進行更詳細的分析。
Ceph 生態系統可以大致劃分為四部分(見圖1):客戶端(數據使用者)、元數據服務器(緩沖及同步分布的元數據)、對象存儲集群(以對象方式存儲數據與元數據,實現其它主要職責),及集群監控(實現監控功能)。
圖 1. Ceph 生態系統的概念架構
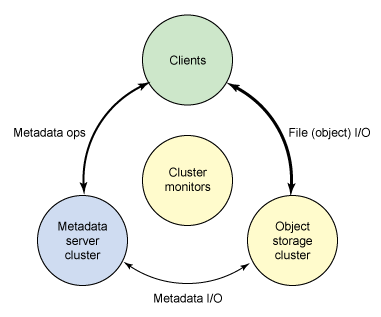
如圖一所示,客戶端通過元數據服務器來執行元數據操作(以識別數據位置)。元數據服務器管理數據的位置及新數據的存儲位置。注意,元數據存儲在存儲集群中(如 "Metadata I/O" 所示)。真正的文件 I/O 發生在客戶端和對象存儲集群之間。以這種方式,較高級的 POSIX 功能(如 open、close、rename)由元數據服務器管理,與此同時,POSIX 功能(如 read、write)直接由對象存儲集群管理。
圖2 提供了架構的另一視角圖。一組服務器通過客戶端接口訪問 Ceph 生態系統,接口理解元數據服務器和對象級存儲的關系。這種分布式存儲系統可被看作為幾層,包括存儲設備的格式(擴展的和基于 B-樹 的對象文件系統[ebofs],或者其它備選),為管理數據復制、故障檢測、恢復、后續數據遷移(稱之為可靠的自發分布式對象存儲,RADOS)等所設計的至關重要的管理層。最后,監控用于鑒定組件故障,包括后續通知。
圖2. Ceph 生態系統的簡化分層視圖

Ceph 組件
了解了 Ceph 的概念構圖之后,你可以繼續深入了解 Ceph 生態系統內實現的主要組件。Ceph 和傳統文件系統一個關鍵的不同是,智能并非集中于文件系統本身,而是分布在生態系統各處。
圖 3 展示了一個簡單的 Ceph 生態系統。Ceph 客戶端是 Ceph 文件系統的使用者。Ceph 元數據后臺服務程序提供了元數據服務,而 Ceph 對象存儲后臺服務程序提供了實際的存儲(數據及元數據)。最后, Ceph 監控提供了集群的管理。注意可以存在多個 Ceph 客戶端,多個對象存儲端點,許多元數據服務器(取決于文件系統的能力),和至少一對冗余監控。這樣的話,這個文件系統是怎樣實現分布的呢?
圖 3. 簡單的 Ceph 生態系統

Ceph 客戶端
因為 Linux 為文件系統提供了一個通用接口(通過虛擬文件系統交換器 [VFS]),Ceph 的用戶視角是透明的。考慮到多個服務器組成存儲系統的可能性(詳見關于創建 Ceph 集群的 資源 一節),管理員視角當然會不同。從使用者的視角看,他們可以使用海量存儲系統,并不知曉下層的元數據服務器、監控、聚合成大規模存儲池的各個對象存儲設備。使用者僅僅看到一個掛載點,從那里執行標準的文件 I/O 操作。
Ceph 文件系統 — 或者至少是客戶端接口 — 在 Linux 內核中實現。注意絕大多數文件系統,所有的控制和智能都實現在內核的文件系統源代碼本身中。但對 Ceph 而言,文件系統的智能分布在各節點上,它簡化了客戶端接口,但也同時提供給 Ceph 應對大規模(甚至動態的)數據的能力。
并非是依賴于分配鏈(用來映射磁盤塊到指定文件的元數據),Ceph 使用了一個有趣的選擇。一個文件從 Linux 的角度看,被賦予了一個來自元數據服務器的 inode 號(INO),它是文件的唯一識別符。之后這個文件被刻進到多個對象中(基于文件大小)。使用 INO 和 對象號 (ONO),每個對象被賦予了一個對象 ID(OID)。通過使用 OID 上的一個簡單哈希,每個對象被分配到 一個放置組中。這個放置組(通過 PGID 來識別)是對象的概念上的容器。最后,放置組到對象存儲設備的映射是一種使用了稱為可擴展哈希受控復制(CRUSH)算法的偽隨機映射。以這種方式,放置組(及副本)映射到存儲設備不依賴于任何元數據,而是依賴于偽隨機映射函數。這種行為是理想的,因為它最小化了存儲的負荷,以及簡化了數據的分布和查詢。
最后一個分配組件是集群映射。集群映射是代表著存儲集群的設備的有效表示。通過 PGID 和 集群映射,你可以定位任何對象。
Ceph 元數據服務器
元數據服務器的任務 (命令) 是管理文件系統的命名空間。盡管不管是數據還是元數據都存儲在對象存儲集群中,它們都被分別管理,以支持可擴展性。事實上,元數據在元數據服務器的集群間進一步的分割,這些元數據服務器能夠自適應的復制和散布命名空間,從而避免熱點。如圖 4所示,元數據服務器管理部分命名空間,并能部分重疊(出于冗余及性能的考慮)。從元數據服務器到命名空間的映射,在 Ceph 中通過動態子樹分區的方式來執行,它允許 Ceph 在保留本地性能的同時可以適應變化的工作負荷(在元數據服務器間遷移命名空間)。
圖 4. Ceph 元數據服務器命名空間的分區

但因為每個元數據服務器就客戶端的個數而言只簡單的管理命名空間,它主要的應用程序是智能元數據緩沖(因為實際的元數據最終存儲在對象存儲集群中)。寫入的元數據被緩沖在短期的日志中,它最終會被推送到物理存儲里。這種行為允許元數據服務器可以立即對客戶端提供最新的元數據服務(這在元數據操作中很常見)。日志對故障恢復也很有用:如果元數據服務器失效,它的日志能被重播,以確保元數據安全的保存到磁盤上。
元數據服務器管理 inode 空間,進行文件名到元數據的轉換。元數據服務器轉換文件名到 inode 節點,文件大小,以及分割 Ceph 客戶端用于文件 I/O 的數據(布局)。
Ceph 監控
Ceph 包括了實現集群映射管理功能的監控,但一些容錯管理的要素實現于對象存儲本身。當對象存儲設備失效,或者新的設備被添加,監控檢測并維持一個有效的集群映射。這個功能以分布式的方式執行,在這里,更新映射會與當前的流量狀況進行溝通。Ceph 使用了 Paxos,它是分布式一致性的一系列算法。
Ceph 對象存儲
與傳統對象存儲相似,Ceph 存儲節點不僅包含了存儲,也包含了智能。傳統的驅動器是的簡單目標端,僅僅響應發起端的命令。而對象存儲設備是智能設備,既可以作為目標端,也可以作為發起端,從而支持通訊以及其它對象存儲設備的協同。
其它有趣的特性
似乎是文件系統的動態自適應的天性不足,Ceph 也實現了一些對使用者可見的有趣特性。例如,用戶可以在 Ceph 的任何子目錄下(包括其全部內容),創建快照。也可以在任何子目錄級進行文件和容量記賬,它可以報告存儲大小和任何指定子目錄的文件數(及其所有的嵌套內容)。
Ceph 現狀與未來
盡管 Ceph 現在集成到 Linux 主流內核中,它被準確的描述為實驗性的。這種狀態的文件系統有助于評估,但還沒有為生產環境做好準備。但考慮到 Ceph 被 Linux 內核所采用,以及發起人持續開發的動力,它應該在不久后就可以用于解決你的大規模存儲的需要。
其它分布式文件系統
Ceph 在分布式文件系統領域并不是獨一無二的,但它在管理大規模存儲的生態系統的方式上是獨特的。其它的分布式文件系統,如包括 Google 文件系統(GFS),通用并行文件系統(GPFS),和 Lustre,僅舉幾例。隨著海量級別存儲的獨特挑戰的引入,Ceph 背后的理念看起來像是為分布式文件系統提供了一種有趣的未來。
展望
Ceph 不僅僅是文件系統,更是一個帶有企業級特性的對象存儲的生態系統。在 資源 一節中,你會發現關于如何建立一個簡單的 Ceph 集群(包括元數據服務器、對象服務器、監控)的信息。Ceph 在分布式存儲方面填補了空白,看到這個開源軟件在未來如何演進也將是很有趣的。














