分布式文件系統之Ceph硬件
硬件推薦
Ceph 為普通硬件設計,這可使構建、維護 PB 級數據集群的費用相對低廉。規劃集群硬件時,需要均衡幾方面的因素,包括區域失效和潛在的性能問題。硬件規劃要包含把使用 Ceph 集群的 Ceph 守護進程和其他進程恰當分布。通常,我們推薦在一臺機器上只運行一種類型的守護進程。大部分專家推薦把使用數據集群的進程(如 OpenStack 、 CloudStack 等)安裝在別的機器上。但是現在這個超融合架構泛濫的時代,部署在一起的大廠商也是有很多的,比如最早在公有云中使用ceph當做存儲的有云。
CPU
Ceph 元數據服務器對 CPU 敏感,它會動態地重分布它們的負載,所以你的元數據服務器應該有足夠的處理能力(我們生產使用的是2C雙12核心CPU)。 Ceph 的 OSD 運行著 RADOS 服務、用CRUSH計算數據存放位置、復制數據、維護它自己的集群運行圖副本,因此 OSD 需要一定的處理能力(如雙核 CPU )。監視器只簡單地維護著集群運行圖的副本,因此對 CPU 不敏感;但必須考慮機器以后是否還會運行 Ceph 監視器以外的 CPU 密集型任務。例如,如果服務器以后要運行用于計算的虛擬機(如 OpenStack Nova ),你就要確保給 Ceph 進程保留了足夠的處理能力,所以我推薦在其他機器上運行 CPU 密集型任務。
內存
元數據服務器和監視器必須可以盡快地提供它們的數據,所以他們應該有足夠的內存,至少每進程 1GB 。 OSD 的日常運行不需要那么多內存(如每進程 500MB )差不多了;然而在恢復期間它們占用內存比較大(如每進程每 TB 數據需要約 1GB 內存)。通常內存越多越好。(我的生產環境是超融合架構512G內存)
數據存儲
要謹慎地規劃數據存儲配置,因為其間涉及明顯的成本和性能折衷。來自操作系統的并行操作和到單個硬盤的多個守護進程并發讀、寫請求操作會極大地降低性能。文件系統局限性也要考慮: btrfs 尚未穩定到可以用于生產環境的程度,但它可以同時記日志并寫入數據,而 xfs 和 ext4 卻不能。
Important:因為 Ceph 發送 ACK 前必須把所有數據寫入日志(至少對 xfs 和 ext4 來說是),因此均衡日志和 OSD 性能相當重要。
硬盤驅動器
OSD 應該有足夠的空間用于存儲對象數據。考慮到大硬盤的每 GB 成本,我們建議用容量大于 1TB 的硬盤。建議用 GB 數除以硬盤價格來計算每 GB 成本,因為較大的硬盤通常會對每 GB 成本有較大影響,例如,單價為 $75 的 1TB 硬盤其每 GB 價格為 $0.07 ( $75/1024=0.0732 ),又如單價為 $150 的 3TB 硬盤其每 GB 價格為 $0.05 ( $150/3072=0.0488 ),這樣使用 1TB 硬盤會增加 40% 的每 GB 價格,它將表現為較低的經濟性。另外,單個驅動器容量越大,其對應的 OSD 所需內存就越大,特別是在重均衡、回填、恢復期間。根據經驗, 1TB 的存儲空間大約需要 1GB 內存。
(我現在生產環境使用的是1.2T高速盤,也就解釋了為何要組成大的內存。)
不顧分區而在單個硬盤上運行多個OSD,這樣強烈不推薦!
不顧分區而在運行了OSD的硬盤上同時運行監視器或元數據服務器也強烈不推薦!
存儲驅動器受限于尋道時間、訪問時間、讀寫時間、還有總吞吐量,這些物理局限性影響著整體系統性能,尤其在系統恢復期間。因此我們推薦獨立的驅動器用于安裝操作系統和軟件,另外每個 OSD 守護進程占用一個驅動器。大多數 “slow OSD”問題的起因都是在相同的硬盤上運行了操作系統、多個 OSD 、和/或多個日志文件。鑒于解決性能問題的成本差不多會超過另外增加磁盤驅動器,你應該在設計時就避免增加 OSD 存儲驅動器的負擔來提升性能。
Ceph 允許你在每塊硬盤驅動器上運行多個 OSD ,但這會導致資源競爭并降低總體吞吐量; Ceph 也允許把日志和對象數據存儲在相同驅動器上,但這會增加記錄寫日志并回應客戶端的延時,因為 Ceph 必須先寫入日志才會回應確認了寫動作。 btrfs 文件系統能同時寫入日志數據和對象數據, xfs 和 ext4 卻不能。
Ceph 最佳實踐指示,你應該分別在單獨的硬盤運行操作系統、 OSD 數據和 OSD 日志。
固態硬盤
一種提升性能的方法是使用固態硬盤( SSD )來降低隨機訪問時間和讀延時,同時增加吞吐量。 SSD 和硬盤相比每 GB 成本通常要高 10 倍以上,但訪問時間至少比硬盤快 100 倍。
SSD 沒有可移動機械部件,所以不存在和硬盤一樣的局限性。但 SSD 也有局限性,評估SSD 時,順序讀寫性能很重要,在為多個 OSD 存儲日志時,有著 400MB/s 順序讀寫吞吐量的 SSD 其性能遠高于 120MB/s 的。
Important
我們建議發掘 SSD 的用法來提升性能。然而在大量投入 SSD 前,強烈建議核實 SSD 的性能指標,并在測試環境下衡量性能。
正因為 SSD 沒有移動機械部件,所以它很適合 Ceph 里不需要太多存儲空間的地方。相對廉價的 SSD 很誘人,慎用!可接受的 IOPS 指標對選擇用于 Ceph 的 SSD 還不夠,用于日志和 SSD 時還有幾個重要考量:
寫密集語義: 記日志涉及寫密集語義,所以你要確保選用的 SSD 寫入性能和硬盤相當或好于硬盤。廉價 SSD 可能在加速訪問的同時引入寫延時,有時候高性能硬盤的寫入速度可以和便宜 SSD 相媲美。
順序寫入: 在一個 SSD 上為多個 OSD 存儲多個日志時也必須考慮 SSD 的順序寫入極限,因為它們要同時處理多個 OSD 日志的寫入請求。
分區對齊: 采用了 SSD 的一個常見問題是人們喜歡分區,卻常常忽略了分區對齊,這會導致 SSD 的數據傳輸速率慢很多,所以請確保分區對齊了。
SSD 用于對象存儲太昂貴了,但是把 OSD 的日志存到 SSD 、把對象數據存儲到獨立的硬盤可以明顯提升性能。osd journal選項的默認值是 /var/lib/ceph/osd/$cluster-$id/journal,你可以把它掛載到一個 SSD 或 SSD 分區,這樣它就不再是和對象數據一樣存儲在同一個硬盤上的文件了。提升 CephFS 文件系統性能的一種方法是從 CephFS 文件內容里分離出元數據。 Ceph 提供了默認的 metadata。存儲池來存儲 CephFS 元數據,所以你不需要給 CephFS 元數據創建存儲池,但是可以給它創建一個僅指向某主機 SSD 的 CRUSH 運行圖。詳情見給存儲池指定 OSD 。
控制器
硬盤控制器對寫吞吐量也有顯著影響,要謹慎地選擇,以免產生性能瓶頸。
Ceph blog通常是優秀的Ceph性能問題來源,見 Ceph Write Throughput 1 和 Ceph Write Throughput 2 。
其他注意事項
你可以在同一主機上運行多個 OSD ,但要確保 OSD 硬盤總吞吐量不超過為客戶端提供讀寫服務所需的網絡帶寬;還要考慮集群在每臺主機上所存儲的數據占總體的百分比,如果一臺主機所占百分比太大而它掛了,就可能導致諸如超過 full ratio的問題,此問題會使 Ceph 中止運作以防數據丟失。如果每臺主機運行多個 OSD ,也得保證內核是最新的。參閱操作系統推薦里關于 glibc和 syncfs(2) 的部分,確保硬件性能可達期望值。
OSD 數量較多(如 20 個以上)的主機會派生出大量線程,尤其是在恢復和重均衡期間。很多 Linux 內核默認的最大線程數較小(如 32k 個),如果您遇到了這類問題,可以把kernel.pid_max
值調高些。理論最大值是 4194303 。
例如把下列這行加入 /etc/sysctl.conf文件:
- kernel.pid_max = 4194303
網絡
建議每臺機器最少兩個千兆網卡,現在大多數機械硬盤都能達到大概 100MB/s 的吞吐量,網卡應該能處理所有 OSD 硬盤總吞吐量,所以推薦最少兩個千兆網卡,分別用于公網(前端)和集群網絡(后端)。集群網絡(最好別連接到國際互聯網)用于處理由數據復制產生的額外負載,而且可防止拒絕服務攻擊,拒絕服務攻擊會干擾數據歸置組,使之在 OSD 數據復制時不能回到active + clean狀態。請考慮部署萬兆網卡。通過 1Gbps 網絡復制 1TB 數據耗時 3 小時,而 3TB (典型配置)需要 9 小時,相比之下,如果使用 10Gbps 復制時間可分別縮減到 20 分鐘和 1 小時。在一個 PB 級集群中, OSD 磁盤失敗是常態,而非異常;在性價比合理的的前提下,系統管理員想讓 PG 盡快從 degraded(降級)狀態恢復到 active + clean狀態。另外,一些部署工具(如 Dell 的 Crowbar )部署了 5 個不同的網絡,但使用了 VLAN 以提高網絡和硬件可管理性。 VLAN 使用 802.1q 協議,還需要采用支持 VLAN 功能的網卡和交換機,增加的硬件成本可用節省的運營(網絡安裝、維護)成本抵消。使用 VLAN 來處理集群和計算棧(如 OpenStack 、 CloudStack 等等)之間的 VM 流量時,采用 10G 網卡仍然值得。每個網絡的機架路由器到核心路由器應該有更大的帶寬,如 40Gbps 到 100Gbps 。
服務器應配置底板管理控制器( Baseboard Management Controller, BMC ),管理和部署工具也應該大規模使用 BMC ,所以請考慮帶外網絡管理的成本/效益平衡,此程序管理著 SSH 訪問、 VM 映像上傳、操作系統安裝、端口管理、等等,會徒增網絡負載。運營 3 個網絡有點過分,但是每條流量路徑都指示了部署一個大型數據集群前要仔細考慮的潛能力、吞吐量、性能瓶頸。
故障域
故障域指任何導致不能訪問一個或多個 OSD 的故障,可以是主機上停止的進程、硬盤故障、操作系統崩潰、有問題的網卡、損壞的電源、斷網、斷電等等。規劃硬件需求時,要在多個需求間尋求平衡點,像付出很多努力減少故障域帶來的成本削減、隔離每個潛在故障域增加的成本。
最低硬件推薦
Ceph 可以運行在廉價的普通硬件上,小型生產集群和開發集群可以在一般的硬件上。
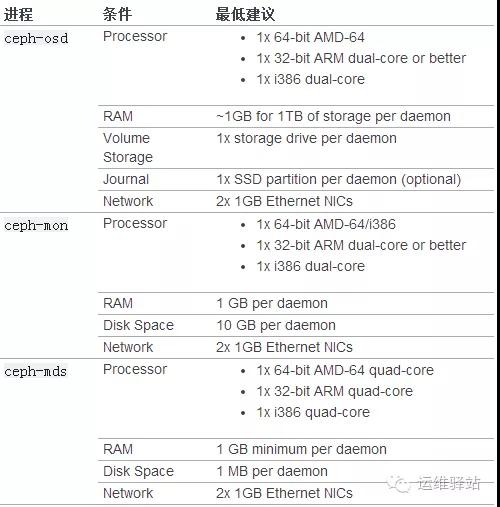
如果在只有一塊硬盤的機器上運行 OSD ,要把數據和操作系統分別放到不同分區;一般來說,我們推薦操作系統和數據分別使用不同的硬盤。
生產集群實例
PB 級生產集群也可以使用普通硬件,但應該配備更多內存、 CPU 和數據存儲空間來解決流量壓力。
我們生產環境硬件配置
- CPU:2*12C
- 內存:512G
- 硬盤:20*1.2T
- 網卡:2*10Gb