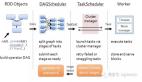
Spark的YARN模式部署
1:Spark的編譯
Spark可以通過SBT(Scala Build Tool)或者Maven來編譯,官方提供的二進制安裝文件是用Maven編譯,如果是要在YARN集群上運行的話,還需要再用SBT編譯一下,生成YARN client端使用的jar包;最好是直接對源碼使用SBT進行編譯而生成YARN client端使用的jar包。筆者在測試過程中,對Maven編譯過的Spark進行SBT二次編譯后,在運行部分例子的時候有錯誤發生。
A:Maven編譯
筆者使用的環境曾經編譯過Hadoop2.2.0(參見hadoop2.2.0源碼編譯(CentOS6.4)),所以不敢確定Maven編譯過程中,Spark是不是需要編譯Hadoop2.2.0中使用的部分底層軟件(看官方資料是需要Protobuf2.5)。除了網絡下載不給力而不斷的中止、然后重新編譯而花費近1天的時間外,編譯過程還是挺順利的。
maven編譯時,首先要進行設置Maven使用的內存項配置:
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
然后用Maven編譯:
mvn -Pnew-yarn -Dhadoop.version=2.2.0 -Dyarn.version=2.2.0 -DskipTestspackage
參考文檔:Building Spark with Maven
B:SBT編譯
Spark源碼和二進制安裝包都綁定了SBT。值得注意的是,如果要使用Scala進行Spark應用開發,必須使用和Spark版本相對應版本的Scala,如:Spark0.8.1對應的Scala2.9.3。對于不匹配的Scala應用開發可能會不能正常工作。
SBT編譯命令:
SPARK_HADOOP_VERSION=2.2.0 SPARK_YARN=true ./sbt/sbt assembly
二種編譯都是在Spark根目錄下運行。在SBT編譯過程中如果網絡不給力,手工中斷編譯(ctrl+z)后要用kill-9 將相應的進程殺死后,然后再重新編譯,不然會被之前的sbt進程鎖住而不能重新編譯。
2:Spark運行
Spark可以單獨運行,也可以在已有的集群上運行,如Amazon EC2、Apache Mesos、Hadoop YARN。下面用Spark自帶的例程進行測試,運行的時候都是在Spark的根目錄下進行。如果需要知道運行更詳細的信息,可以使用log4j,只要在根目錄下運行:
cp conf/log4j.properties.template conf/log4j.properties
A:本地運行
./run-example org.apache.spark.examples.SparkPi local
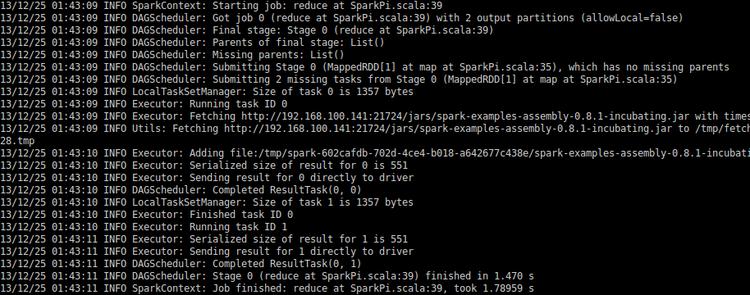
也可以多線程方式運行,下面的命令就是開4個線程。
./run-example org.apache.spark.examples.SparkPi local[4]
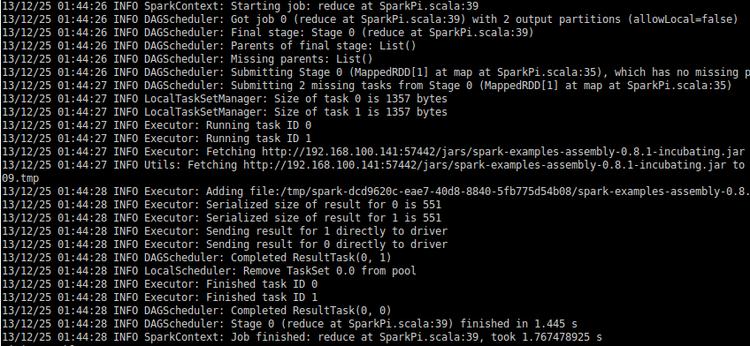
B:YARN集群
啟動Hadoop2.2.0集群
確保環境變量HADOOP_CONF_DIR或YARN_CONF_DIR已經設置
在YARN集群中運行Spark應用程序的命令:
- SPARK_JAR=<SPARK_ASSEMBLY_JAR_FILE> ./spark-classorg.apache.spark.deploy.yarn.Client \
- --jar <YOUR_APP_JAR_FILE> \
- --class <APP_MAIN_CLASS> \
- --args <APP_MAIN_ARGUMENTS> \
- --num-workers <NUMBER_OF_WORKER_MACHINES> \
- --master-class <ApplicationMaster_CLASS>
- --master-memory <MEMORY_FOR_MASTER> \
- --worker-memory <MEMORY_PER_WORKER> \
- --worker-cores <CORES_PER_WORKER> \
- --name <application_name> \
- --queue <queue_name> \
- --addJars <any_local_files_used_in_SparkContext.addJar> \
- --files <files_for_distributed_cache> \
- --archives <archives_for_distributed_cache>
例1計算PI,可以看出程序運行時是先將運行文件上傳到Hadoop集群的,所以客戶端最好是和Hadoop集群在一個局域網里。
- SPARK_JAR=./assembly/target/scala-2.9.3/spark-assembly-0.8.1-incubating-hadoop2.2.0.jar \
- ./spark-class org.apache.spark.deploy.yarn.Client \
- --jar examples/target/scala-2.9.3/spark-examples-assembly-0.8.1-incubating.jar \
- --class org.apache.spark.examples.SparkPi \
- --args yarn-standalone \
- --num-workers 3 \
- --master-memory 2g \
- --worker-memory 2g \
- --worker-cores 1
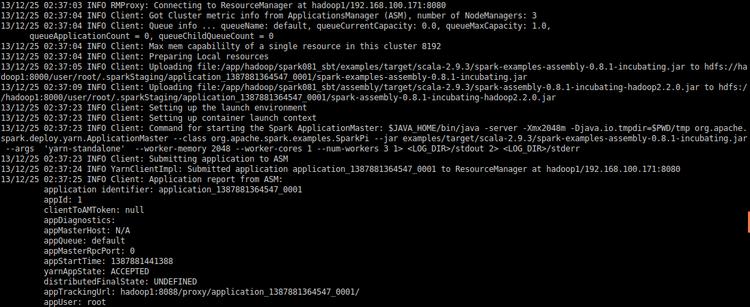
例2計算TC
- SPARK_JAR=./assembly/target/scala-2.9.3/spark-assembly-0.8.1-incubating-hadoop2.2.0.jar \
- ./spark-class org.apache.spark.deploy.yarn.Client \
- --jar examples/target/scala-2.9.3/spark-examples-assembly-0.8.1-incubating.jar \
- --class org.apache.spark.examples.SparkTC \
- --args yarn-standalone \
- --num-workers 3 \
- --master-memory 2g \
- --worker-memory 2g \
- --worker-cores 1
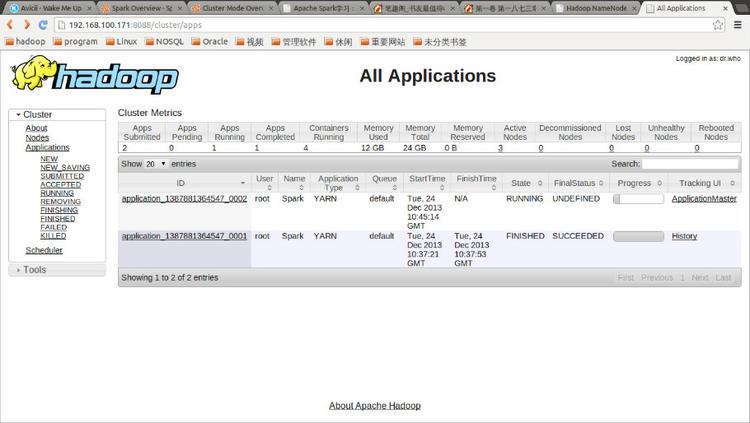
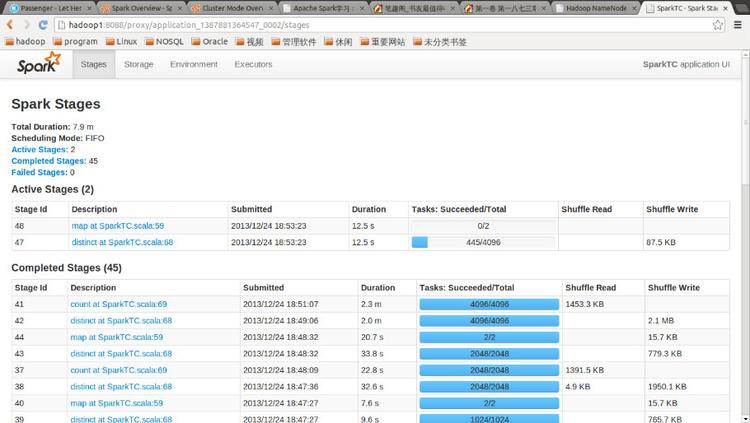
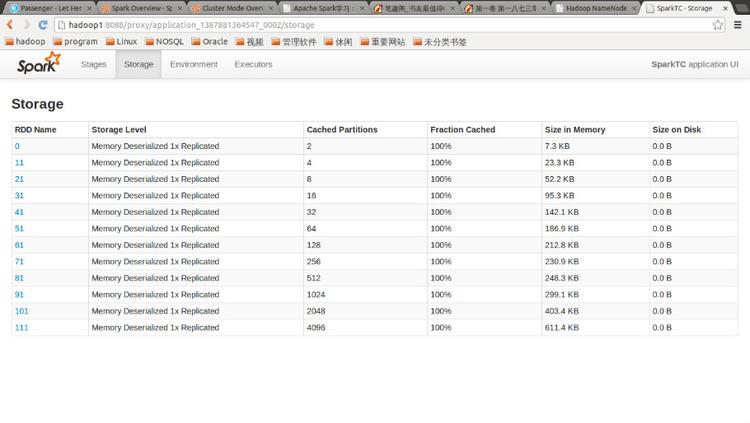
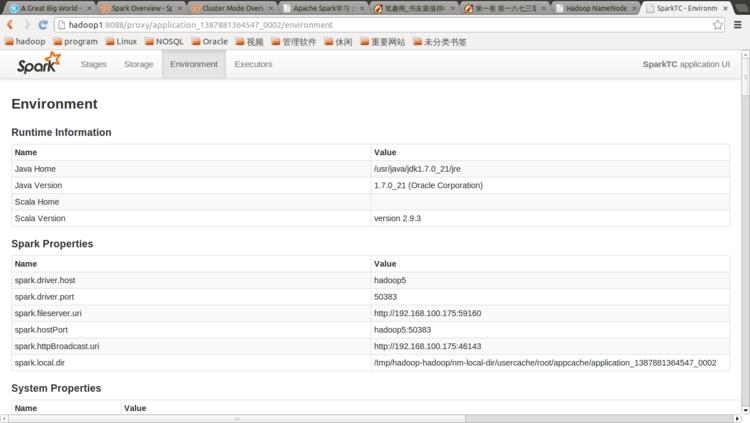
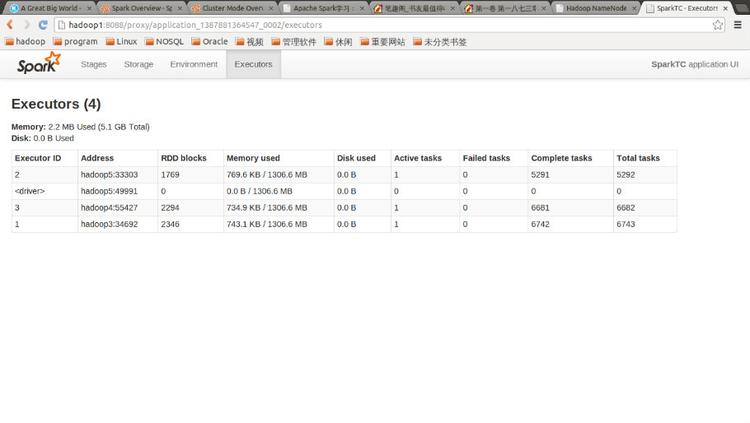
點擊Tracking UI中的相應鏈接可以查看Spark的運行信息: