Hulu,因為尚未進入中國,知道它的人遠不如知道YouTube和優(yōu)酷、土豆。而在美國,Hulu已經(jīng)將Google Video擠出局成為全美排名第10的視頻網(wǎng)站。今天,來自Hulu,負責大數(shù)據(jù)團隊基礎(chǔ)架構(gòu)開發(fā)的梁宇明老師,將為我們分享Hulu的Spark On YARN之路。
梁宇明, 2010年從清華大學(xué)自動化系畢業(yè)加入Hulu。在Hulu做過多個團隊的開發(fā),最早是在搜索團隊,后來負責在Mobile和Media Room Device設(shè)備上的開發(fā)。之后負責了在Hulu的大數(shù)據(jù)構(gòu)建工作。
梁宇明在51CTO舉辦WOT峰會,分享《Spark On YARN in Hulu》Hulu大數(shù)據(jù)平臺是research團隊構(gòu)建算法,深度理解用戶需求的重要基礎(chǔ)。本講主要介紹Hulu大數(shù)據(jù)平臺架構(gòu),Spark On YARN在Hulu的應(yīng)用,以及Hulu在Docker + YARN上的探索。
演講PPT官方下載地址:http://down.51cto.com/data/1634397
[[118648]]
Hulu高級研發(fā)主管 梁宇明
記者:我們也知道Hulu是個視頻網(wǎng)站,它其實更多的是面向美國的用戶,它在中國的研發(fā)團隊,在Hulu整個集團當中擔任什么樣的角色?
梁宇明:Hulu北京的研發(fā)團隊是Hulu***的研發(fā)團隊,Hulu一共有三個研發(fā)團隊,分別位于洛杉磯、西雅圖還有北京,其中北京是***的研發(fā)團隊,北京研發(fā)團隊以做一些research相關(guān)的工作為主,同時也做一些,為research提供一些基礎(chǔ)視頻架構(gòu),同時也會有一些其他的開發(fā)。
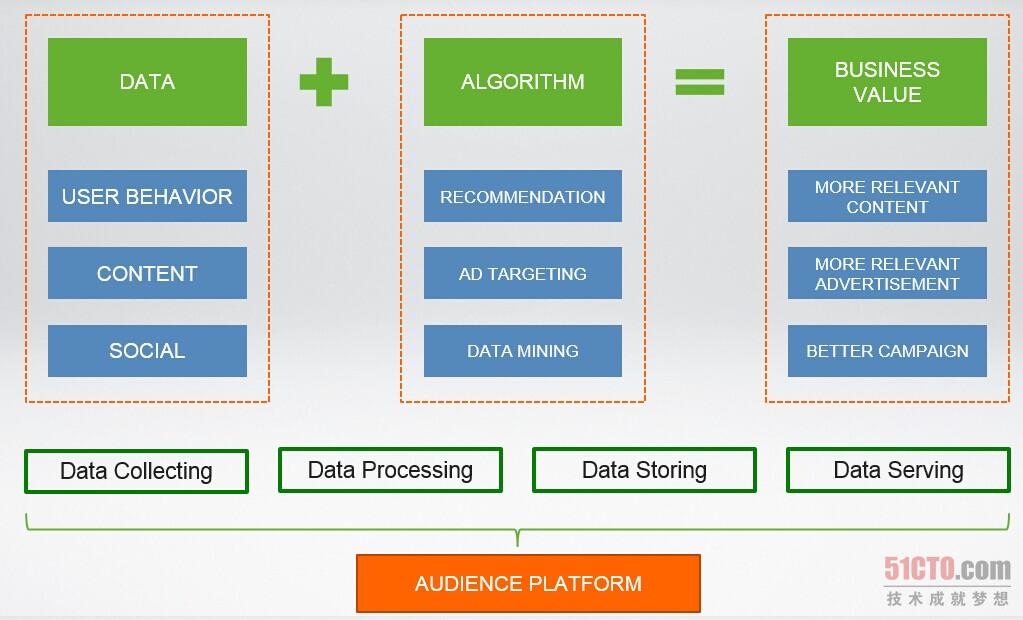
Hulu技術(shù)框架
記者:提到大數(shù)據(jù),大數(shù)據(jù)現(xiàn)在很火,我們想知道在Hulu網(wǎng)站架構(gòu)體系下,大數(shù)據(jù)整個技術(shù)應(yīng)用大概分為幾部分?
梁宇明:我覺得可以從歷史上去看待這個問題,就是Hulu的歷史上,大數(shù)據(jù)的發(fā)展應(yīng)該分為兩個階段,***階段主要是用做收集一些數(shù)據(jù)進行reporting,這個相對來說流程比較清晰一些,ingested一些數(shù)據(jù),把這些數(shù)據(jù)在HDFS中生成出來導(dǎo)入到Hive中。然后在中間過程中我們會有自己的叫做Hulu in Spark,這是一條線。在這條線完成一定時間之后的話,我們注意到說為了更好地服務(wù)research方面的需要,特別是research希望通過一些機器學(xué)習(xí)的方法從數(shù)據(jù)中挖掘一些價值,那么已有的這些處理方法就不可行了。在這個基礎(chǔ)之上,我們發(fā)展出了大數(shù)據(jù)的第二條業(yè)務(wù)線,也就是我現(xiàn)在負責的團隊,它主要做的一件事情是說考慮到research體系的一個整個的生命周期,比如說以機器學(xué)習(xí)的方法解決一些用戶關(guān)心的問題大概分為幾大步驟,***個步驟是說獲取用戶的行為,在用戶的行為生成一些特性,延伸出一些模型,***被用作在線的一些服務(wù)中。我的團隊在第二階段做的主要的事情是說把離線的這部分和在線的這部分做起來,主要通過實現(xiàn)了一個Lamda的方式去做出來的。在這個基礎(chǔ)之上,我們有一些問題沒有解決就是research怎么樣獲取團隊和生成這個模型的過程,這個過程我們主要是通過基于Spark On YARN這樣的體系,然后一起以及上面構(gòu)筑的library來實現(xiàn)的。
記者:你剛才也提到Spark,我們也知道在Hulu團隊當中是用的Docker + YARN的方式來做Spark方面的事情。
梁宇明:我可能想稍微修正一下,就是在Hulu內(nèi)部Spark On YARN和Docker On YARN是分開的兩部分,然后我們在Spark方面的主要的應(yīng)用有兩方面,***方面是Spark Streaming,這個主要是用作我們實時展現(xiàn)的一些基礎(chǔ)的部件,另外一部分主要是給research團隊去寫一些他們的算法,實現(xiàn)一些并行化算法更方便的,用來替代一些原本Mapreduce的程序,這是Spark On YARN這部分。Docker On YARN這部分是用來解決一個完全不同的問題的,我們之所以用Docker on YARN是因為在Hulu有一些research寫出來的程序,它們的環(huán)境依賴極其復(fù)雜,很難通過一個Mapreduce這樣的程序或者Spark程序表現(xiàn)出來。比如說就像有一些計算機視覺的色彩,依賴了很多外部類,有很多的C++或者是C的代碼,這樣的話,環(huán)境特別復(fù)雜,又很難用Mapreduce方式展現(xiàn)出來。我們可以做的一件事情就是說我們把這個程序以及它的環(huán)境整個通過Docker打包成一個Docker Image,這樣子的話就相當于一個小型的攝影機,所有的東西都在里面了。有了這個東西就我們相當于生成了一個超級可執(zhí)行體,把這個執(zhí)行體放在任何地方都可以執(zhí)行的,至少我們就考慮到怎么樣把它并行化,在并行化的過程當中就怎么樣把Docker Image分化到不同的機器中去,特別是分化到一些含有公共資源的機器中去。然后怎么去解決這個問題呢?我們考慮到我們內(nèi)部的話,已經(jīng)把Mapreduce生成了很大的集群,然后我們希望說把Docker同樣放在這樣一個集群中去運行,這樣的話我們可以做到自由的利用,這是我們做Docker On YARN的原因。
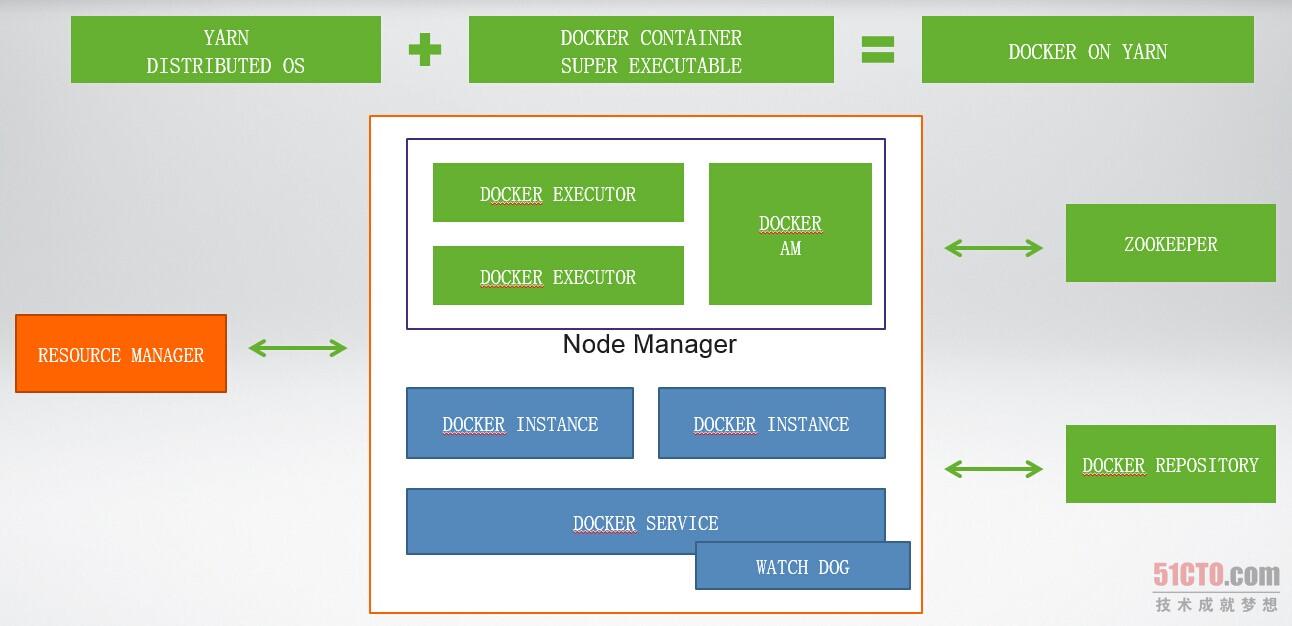
Hulu的Doceker on Yarn
記者:你剛才也提到資源的優(yōu)化,如果說是采用這種架構(gòu),有多大的改進?
梁宇明:具體的數(shù)字我很難描述,但是我可以具體說一件這樣的事情。比如說以前的話,做一些計算機視覺的東西和編程化處理的話就要提前部署十臺機器,這十臺機器大環(huán)境都已經(jīng)部署好了,然后這十臺機器主要用作臉部視覺處理這一件事情,除了這件事情以外它平常都是空閑的,如果把它放在我們的集群中呢,就屬于如果你在不做這件事情的時候,你的計算機就會被其他的程序利用,這個就會好很多,這個可以避免說比申請一堆閑置的機器在那里,沒有特別好的資源利用率。我在51CTO的WOT峰會上,主要是分享在Spark On YARN的部署以及開發(fā)的過程當中遇到的一些問題,因為我們在最早的時候,把Spark On YARN的時候,就是因為我們用的Hadoop發(fā)行版本跟Spark其實不兼容的,然后我們做了一系列的處理。之后在Spark中,因為Spark現(xiàn)在的發(fā)展還有不如Mapreduce的地方,在整個的應(yīng)用過程當中還會碰到一些各種各樣的問題,然后我就會去分享一下,在這個過程當中我們遇到什么樣的問題,以及怎么樣解決它,希望對大家有所幫助。
記者:那***有一個問題,Spark也是大家很看好的新興技術(shù),你對于它未來,比如說今年或者明年Spark大概的展望或者希望。
梁宇明:我個人是非常看好Spark這項技術(shù)的,我覺得它在未來的體系當中將扮演更重要的角色,然后再逐步的替換掉一些Mapreduce以前所做的工作,我覺得這是一個大勢所趨。
【責任編輯:
彭凡 TEL:(010)68476606】
























