解析Spark在騰訊、雅虎、優酷的成功應用
為了滿足挖掘分析與交互式實時查詢的計算需求,騰訊大數據使用了Spark平臺來支持挖掘分析類計算、交互式實時查詢計算以及允許誤差范圍的快速查詢計算,目前騰訊大數據擁有超過200臺的Spark集群,并獨立維護Spark和Shark分支。Spark集群已穩定運行2年,我們積累了大量的案例和運營經驗能力,另外多個業務的大數據查詢與分析應用,已在陸續上線并穩定運行。在SQL查詢性能方面普遍比MapReduce高出2倍以上,利用內存計算和內存表的特性,性能至少在10倍以上。在迭代計算與挖掘分析方面,精準推薦將小時和天級別的模型訓練轉變為Spark的分鐘級別的訓練,同時簡潔的編程接口使得算法實現比MR在時間成本和代碼量上高出許多。
Spark VS MapReduce
盡管MapReduce適用大多數批處理工作,并且在大數據時代成為企業大數據處理的***技術,但由于以下幾個限制,它對一些場景并不是***選擇:
缺少對迭代計算以及DAG運算的支持
Shuffle過程多次排序和落地,MR之間的數據需要落Hdfs文件系統
Spark在很多方面都彌補了MapReduce的不足,比MapReduce的通用性更好,迭代運算效率更高,作業延遲更低,它的主要優勢包括:
提供了一套支持DAG圖的分布式并行計算的編程框架,減少多次計算之間中間結果寫到Hdfs的開銷
提供Cache機制來支持需要反復迭代計算或者多次數據共享,減少數據讀取的IO開銷
使用多線程池模型來減少task啟動開稍,shuffle過程中避免不必要的sort操作以及減少磁盤IO操作
廣泛的數據集操作類型
MapReduce由于其設計上的約束只適合處理離線計算,在實時查詢和迭代計算上仍有較大的不足,而隨著業務的發展,業界對實時查詢和迭代分析有更多的需求,單純依靠MapReduce框架已經不能滿足業務的需求了。Spark由于其可伸縮、基于內存計算等特點,且可以直接讀寫Hadoop上任何格式的數據,成為滿足業務需求的***候選者。
應用Spark的成功案例
目前大數據在互聯網公司主要應用在廣告、報表、推薦系統等業務上。在廣告業務方面需要大數據做應用分析、效果分析、定向優化等,在推薦系統方面則需要大數據優化相關排名、個性化推薦以及熱點點擊分析等。
這些應用場景的普遍特點是計算量大、效率要求高。Spark恰恰滿足了這些要求,該項目一經推出便受到開源社區的廣泛關注和好評。并在近兩年內發展成為大數據處理領域最炙手可熱的開源項目。
本章將列舉國內外應用Spark的成功案例。
1. 騰訊
廣點通是最早使用Spark的應用之一。騰訊大數據精準推薦借助Spark快速迭代的優勢,圍繞“數據+算法+系統”這套技術方案,實現了在“數據實時采集、算法實時訓練、系統實時預測”的全流程實時并行高維算法,最終成功應用于廣點通pCTR投放系統上,支持每天上百億的請求量。
基于日志數據的快速查詢系統業務構建于Spark之上的Shark,利用其快速查詢以及內存表等優勢,承擔了日志數據的即席查詢工作。在性能方面,普遍比Hive高2-10倍,如果使用內存表的功能,性能將會比Hive快百倍。
2. Yahoo
Yahoo將Spark用在Audience Expansion中的應用。Audience Expansion是廣告中尋找目標用戶的一種方法:首先廣告者提供一些觀看了廣告并且購買產品的樣本客戶,據此進行學習,尋找更多可能轉化的用戶,對他們定向廣告。Yahoo采用的算法是logistic regression。同時由于有些SQL負載需要更高的服務質量,又加入了專門跑Shark的大內存集群,用于取代商業BI/OLAP工具,承擔報表/儀表盤和交互式/即席查詢,同時與桌面BI工具對接。目前在Yahoo部署的Spark集群有112臺節點,9.2TB內存。
3. 淘寶
阿里搜索和廣告業務,最初使用Mahout或者自己寫的MR來解決復雜的機器學習,導致效率低而且代碼不易維護。淘寶技術團隊使用了Spark來解決多次迭代的機器學習算法、高計算復雜度的算法等。將Spark運用于淘寶的推薦相關算法上,同時還利用Graphx解決了許多生產問題,包括以下計算場景:基于度分布的中樞節點發現、基于***連通圖的社區發現、基于三角形計數的關系衡量、基于隨機游走的用戶屬性傳播等。
4. 優酷土豆
優酷土豆在使用Hadoop集群的突出問題主要包括:***是商業智能BI方面,分析師提交任務之后需要等待很久才得到結果;第二就是大數據量計算,比如進行一些模擬廣告投放之時,計算量非常大的同時對效率要求也比較高,***就是機器學習和圖計算的迭代運算也是需要耗費大量資源且速度很慢。
最終發現這些應用場景并不適合在MapReduce里面去處理。通過對比,發現Spark性能比MapReduce提升很多。首先,交互查詢響應快,性能比Hadoop提高若干倍;模擬廣告投放計算效率高、延遲小(同hadoop比延遲至少降低一個數量級);機器學習、圖計算等迭代計算,大大減少了網絡傳輸、數據落地等,極大的提高的計算性能。目前Spark已經廣泛使用在優酷土豆的視頻推薦(圖計算)、廣告業務等。
Spark與Shark的原理
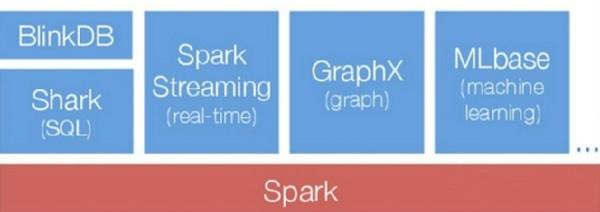
1.Spark生態圈
如下圖所示為Spark的整個生態圈,***層為資源管理器,采用Mesos、Yarn等資源管理集群或者Spark自帶的Standalone模式,底層存儲為文件系統或者其他格式的存儲系統如HBase。Spark作為計算框架,為上層多種應用提供服務。Graphx和MLBase提供數據挖掘服務,如圖計算和挖掘迭代計算等。Shark提供SQL查詢服務,兼容Hive語法,性能比Hive快3-50倍,BlinkDB是一個通過權衡數據精確度來提升查詢晌應時間的交互SQL查詢引擎,二者都可作為交互式查詢使用。Spark Streaming將流式計算分解成一系列短小的批處理計算,并且提供高可靠和吞吐量服務。
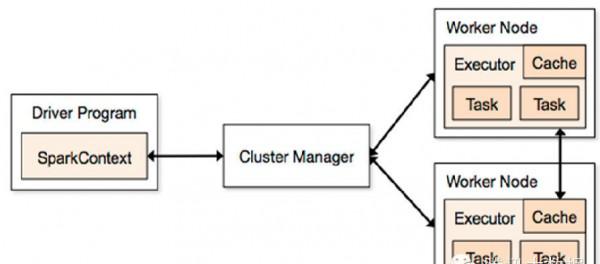
2.Spark基本原理
Spark運行框架如下圖所示,首先有集群資源管理服務(Cluster Manager)和運行作業任務的結點(Worker Node),然后就是每個應用的任務控制結點Driver和每個機器節點上有具體任務的執行進程(Executor)。
與MR計算框架相比,Executor有二個優點:一個是多線程來執行具體的任務,而不是像MR那樣采用進程模型,減少了任務的啟動開稍。二個是Executor上會有一個BlockManager存儲模塊,類似于KV系統(內存和磁盤共同作為存儲設備),當需要迭代多輪時,可以將中間過程的數據先放到這個存儲系統上,下次需要時直接讀該存儲上數據,而不需要讀寫到hdfs等相關的文件系統里,或者在交互式查詢場景下,事先將表Cache到該存儲系統上,提高讀寫IO性能。另外Spark在做Shuffle時,在Groupby,Join等場景下去掉了不必要的Sort操作,相比于MapReduce只有Map和Reduce二種模式,Spark還提供了更加豐富全面的運算操作如filter,groupby,join等。
Spark采用了Scala來編寫,在函數表達上Scala有天然的優勢,因此在表達復雜的機器學習算法能力比其他語言更強且簡單易懂。提供各種操作函數來建立起RDD的DAG計算模型。把每一個操作都看成構建一個RDD來對待,而RDD則表示的是分布在多臺機器上的數據集合,并且可以帶上各種操作函數。如下圖所示:
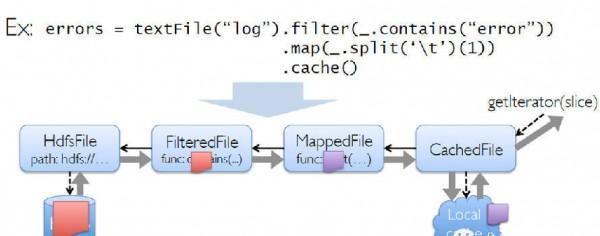
首先從hdfs文件里讀取文本內容構建成一個RDD,然后使用filter()操作來對上次的RDD進行過濾,再使用map()操作取得記錄的***個字段,***將其cache在內存上,后面就可以對之前cache過的數據做其他的操作。整個過程都將形成一個DAG計算圖,每個操作步驟都有容錯機制,同時還可以將需要多次使用的數據cache起來,供后續迭代使用。
3.Shark的工作原理
Shark是基于Spark計算框架之上且兼容Hive語法的SQL執行引擎,由于底層的計算采用了Spark,性能比MapReduce的Hive普遍快2倍以上,如果是純內存計算的SQL,要快5倍以上,當數據全部load在內存的話,將快10倍以上,因此Shark可以作為交互式查詢應用服務來使用。
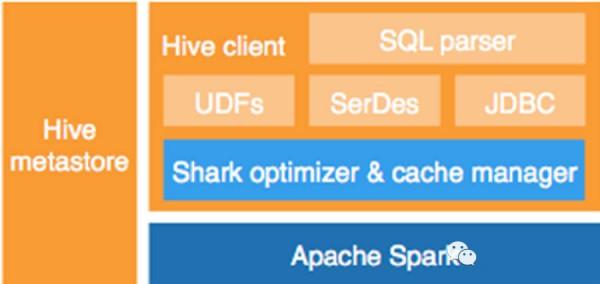
上圖就是整個Shark的框架圖,與其他的SQL引擎相比,除了基于Spark的特性外,Shark是完全兼容Hive的語法,表結構以及UDF函數等,已有的HiveSql可以直接進行遷移至Shark上。
與Hive相比,Shark的特性如下:
1.以在線服務的方式執行任務,避免任務進程的啟動和銷毀開稍,通常MapReduce里的每個任務都是啟動和關閉進程的方式來運行的,而在Shark中,Server運行后,所有的工作節點也隨之啟動,隨后以常駐服務的形式不斷的接受Server發來的任務。
2.Groupby和Join操作不需要Sort工作,當數據量內存能裝下時,一邊接收數據一邊執行計算操作。在Hive中,不管任何操作在Map到Reduce的過程都需要對Key進行Sort操作。
3.對于性能要求更高的表,提供分布式Cache系統將表數據事先Cache至內存中,后續的查詢將直接訪問內存數據,不再需要磁盤開稍。
4.還有很多Spark的特性,如可以采用Torrent來廣播變量和小數據,將執行計劃直接傳送給Task,DAG過程中的中間數據不需要落地到Hdfs文件系統。
騰訊大數據Spark的概況
騰訊大數據綜合了多個業務線的各種需求和特性,目前正在進行以下工作:
1.經過改造和優化的Shark和Spark吸收了TDW平臺的功能,如Hive的特有功能:元數據重構,分區優化等,同時可以通過IDE或者洛子調度來直接執行HiveSql查詢和定時調度Spark的任務;
2.與Gaia和TDW的底層存儲直接兼容,可以直接安全且高效地使用TDW集群上的數據;
3.對Spark底層的使用門檻,資源管理與調度,任務監控以及容災等多個功能進行完善,并支持快速的遷移和擴容。