優酷土豆應用Spark完善大數據分析案例
大數據,一個似乎已經被媒體傳播的過于泛濫的詞匯,的的確確又在逐漸影響和改變著我們的生活。也許有人認為大數據在中國仍然只是噱頭,但在當前中國互聯網領域,大數據以及大數據所催生出來的生產力正在潛移默化地推動業務發展,并為廣大中國網民提供更加優秀的服務。優酷土豆作為國內***的視頻網站,和國內其他互聯網巨頭一樣,率先看到大數據對公司業務的價值,早在2009年就開始使用Hadoop集群,隨著這些年業務迅猛發展,優酷土豆又率先嘗試了仍處于大數據前沿領域的Spark/Shark 內存計算框架,很好地解決了機器學習和圖計算多次迭代的瓶頸問題,使得公司大數據分析更加完善。
MapReduce之痛
提到大數據,自然不能不提Hadoop。HDFS已然成為大數據公認的存儲,而MapReduce作為其搭配的數據處理框架在大數據發展的早期表現出了重大的價值。可由于其設計上的約束MapReduce只適合處理離線計算,其在實時性上仍有較大的不足,隨著業務的發展,業界對實時性和準確性有更多的需求,很明顯單純依靠MapReduce框架已經不能滿足業務的需求了。
優酷土豆集團大數據團隊技術總監盧學裕就表示:“現在我們使用Hadoop處理一些問題諸如迭代式計算,每次對磁盤和網絡的開銷相當大。尤其每一次迭代計算都將結果要寫到磁盤再讀回來,另外計算的中間結果還需要三個備份,這其實是浪費。”
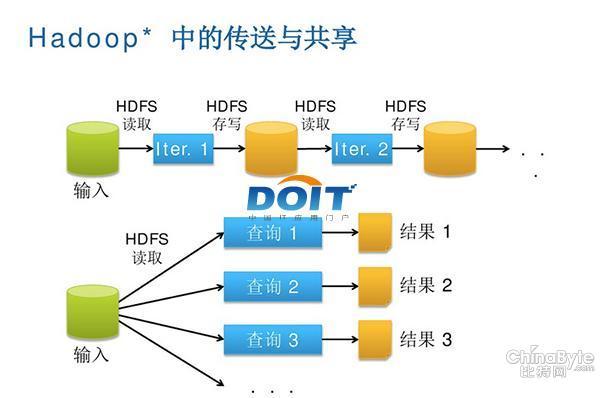
圖一:Hadoop中的數據傳送與共享,串行方式、復制以及磁盤IO等因素使得Hadoop集群在低延遲、實時計算方面表現有待改進。
據悉,優酷土豆的Hadoop大數據平臺是從2009年開始采用,最初只有10多個節點,2012年集群節點達到150個,2013年更是達到300個,每天處理數據量達到200TB。優酷土豆鑒于Hadoop集群已經逐漸勝任不了一些應用,于是決定引入Spark/Shark內存計算框架,以此來滿足圖計算迭代等的需求。
Spark是一個通用的并行計算框架,由伯克利大學的AMP實驗室開發,Spark已經成為繼Hadoop之后又一大熱門開源項目,目前已經有英特爾等企業加入到該開源項目。
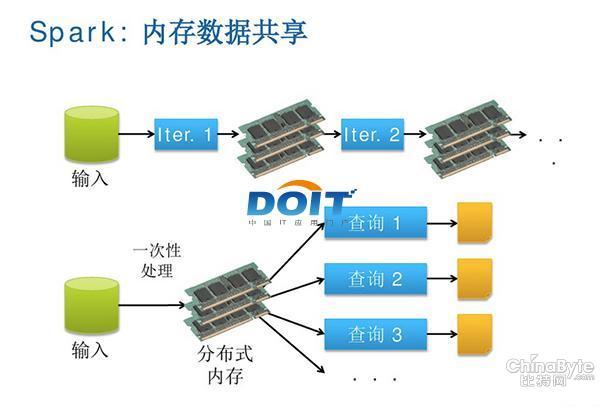
圖二:Spark內存計算框架使得數據共享比網絡和磁盤快10倍到100倍。
“我們大數據平臺對快速需求的響應延時,尤其是在商業智能BI以及產品研究分析等需要多次對大數據做Drill Down與Drill Up時,等待成了效率殺手。” 優酷土豆集團大數據團隊技術總監盧學裕表示。
用Spark/Shark完善大數據分析
目前大數據在互聯網公司主要應用在廣告、報表、推薦系統等業務上。在廣告業務方面需要大數據做應用分析、效果分析、定向優化等,在推薦系統方面則需要大數據優化相關排名、個性化推薦以及熱點點擊分析等。優酷土豆屬于典型的互聯網公司,目前運用大數據分析平臺的主要工作是運營分析、機器學習、廣告定向優化、搜索優化等方面。
優酷土豆集團大數據團隊技術總監盧學裕表示:“優酷土豆的大數據平臺已經用了很多年,突出問題主要包括:***是商業智能BI方面,公司的分析師提交任務之后需要等待很久才得到結果;第二就是大數據量計算,比如進行一些模擬廣告投放之時,計算量非常大的同時對效率要求也比較高,用Hadoop消耗資源非常大而且響應比較慢;***就是機器學習和圖計算的迭代運算也是需要耗費大量資源且速度很慢。”
因此,面對復雜任務、交互式查詢以及流在線處理時,Hadoop與MapReduce并不適用。Spark/Shark這種內存型計算框架則比較適合各種迭代算法和交互式數據分析,可每次將彈性分布式數據集(RDD)操作之后的結果存入內存中,下次操作可直接從內存中讀取,省去了大量的磁盤IO,效率也隨之大幅提升。優酷土豆集團大數據團隊大數據平臺架構師傅杰表示:“一些應用場景并不適合在MapReduce里面去處理。通過對比,我們發現Spark性能比MapReduce提升很多。”
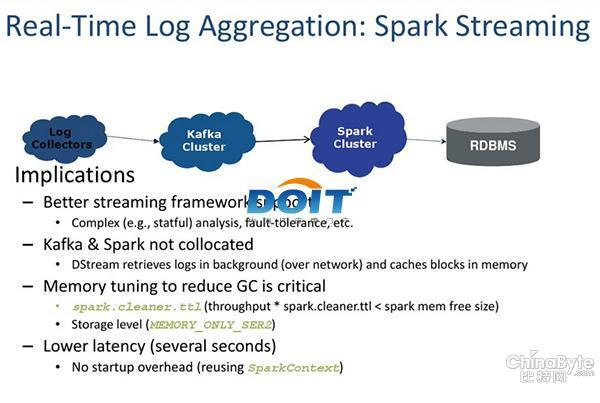
圖三:Spark/Shark內存計算框架實時日志聚合處理。
“比如在圖計算方面,視頻與視頻之間存在的相似關系,這就構成了一個圖譜,通過圖譜來做聚類,再給用戶做視頻推薦。” 優酷土豆集團大數據團隊技術總監盧學裕表示。
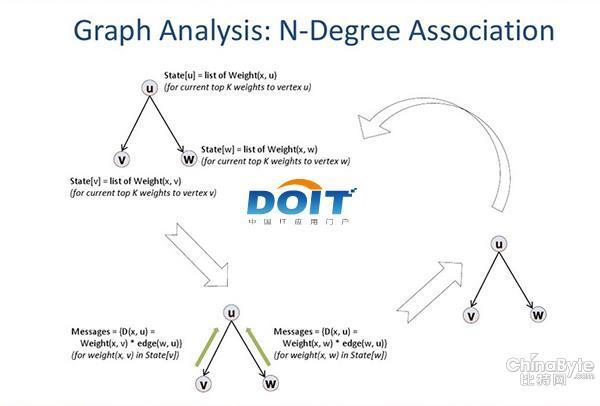
圖四:圖計算分析N度關聯算法示意圖。
優酷土豆集團大數據團隊技術總監盧學裕表示:“我們進行過圖計算方面的測試,在4臺節點的Spark集群上用時只有5.6分鐘,而同規模的數據量,單機實現需要80多分鐘,并且內存吃滿,單機無法實現Scale-Out,不能計算更大規模數據。”
“在今天,數據處理要求非常快。比如優酷土豆的一些客戶、廣告商往往臨時就需要看一下投放效果。所以在前端應用不變的情況下,如果能更快的響應市場的需要就變得很有競爭力。市場是瞬息萬變的,有一些分析結果也需要快速響應成一個產品,Spark集成到數據平臺正能發揮這樣的效果。” 優酷土豆集團大數據團隊大數據平臺架構師傅杰補充道。
據了解,優酷土豆采用Spark/Shark大數據計算框架得到了英特爾公司的幫助,起初優酷土豆并不熟悉Spark以及Scala語言,英特爾幫助優酷土豆設計出具體符合業務需求的解決方案,并協助優酷土豆實現了該方案。此外,英特爾還給優酷土豆的大數據團隊進行了Scala語言、Spark的培訓等。
“優酷土豆作為國內視頻行業***家商用部署Spark/Shark方案的公司,從視頻行業的多樣化分析角度來看是個非常好的方案。未來,英特爾將會繼續與優酷土豆在Spark/Shark進行合作,包括硬件配置的優化以及整體方案的優化等”英特爾(中國)有限公司銷售市場部互聯網及媒體行業企業客戶經理李志輝介紹道。
未來:將Spark/Shark融入到Hadoop 2.0
對于大數據而言,Hadoop已經構建完成了較為完善的生態系統,特別是Hadoop 2.0版本在今年推出之后,改善了諸多缺點。而Spark/Shark計算框架其實與Hadoop并不沖突,Spark現在已經可以直接運行在Yarn的框架之上,成為Hadoop生態系統之中不可或缺的成員。
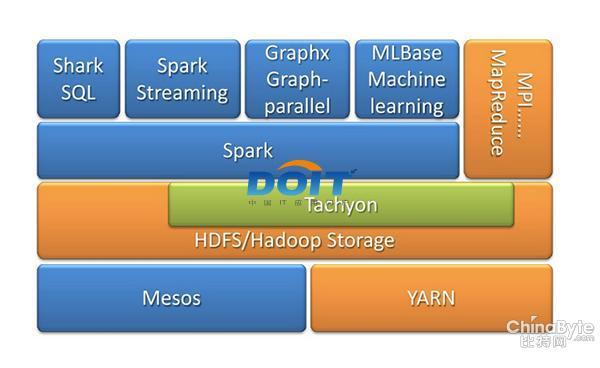
圖五:Spark On Yarn 。
優酷土豆集團大數據團隊大數據平臺架構師傅杰表示:“目前Hadoop 2.0已經發布了release版本,我們已經啟動了對Hadoop 2.0的升級預演。這中間還涉及到我們在1.0版本上修改的一些特性需要遷移和驗證,我們希望做到在不影響業務的情況下實現平滑升級,預計在明年Q1完成升級。Hadoop 2.0將會是非常強大的,不再僅僅是MapReduce,還能融入Spark,能夠讓用戶可以根據數據處理應用需求的不同來選擇合適的計算框架。