機器學習中的數(shù)學(3):模型組合之Boosting
前言:
本來上一章的結(jié)尾提到,準備寫寫線性分類的問題,文章都已經(jīng)寫得差不多了,但是突然聽說最近Team準備做一套分布式的分類器,可能會使用Random Forest來做,下了幾篇論文看了看,簡單的random forest還比較容易弄懂,復(fù)雜一點的還會與boosting等算法結(jié)合(參見iccv09),對于boosting也不甚了解,所以臨時抱佛腳的看了看。說起boosting,強哥之前實現(xiàn)過一套Gradient Boosting Decision Tree(GBDT)算法,正好參考一下。
最近看的一些論文中發(fā)現(xiàn)了模型組合的好處,比如GBDT或者rf,都是將簡單的模型組合起來,效果比單個更復(fù)雜的模型好。組合的方式很多,隨機化(比如random forest),Boosting(比如GBDT)都是其中典型的方法,今天主要談?wù)凣radient Boosting方法(這個與傳統(tǒng)的Boosting還有一些不同)的一些數(shù)學基礎(chǔ),有了這個數(shù)學基礎(chǔ),上面的應(yīng)用可以看Freidman的Gradient Boosting Machine。
本文要求讀者學過基本的大學數(shù)學,另外對分類、回歸等基本的機器學習概念了解。
本文主要參考資料是prml與Gradient Boosting Machine。
Boosting方法:
Boosting這其實思想相當?shù)暮唵危蟾攀牵瑢σ环輸?shù)據(jù),建立M個模型(比如分類),一般這種模型比較簡單,稱為弱分類器(weak learner)每次分類都將上一次分錯的數(shù)據(jù)權(quán)重提高一點再進行分類,這樣最終得到的分類器在測試數(shù)據(jù)與訓練數(shù)據(jù)上都可以得到比較好的成績。

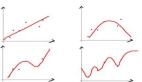
上圖(圖片來自prml p660)就是一個Boosting的過程,綠色的線表示目前取得的模型(模型是由前m次得到的模型合并得到的),虛線表示當前這次模型。每次分類的時候,會更關(guān)注分錯的數(shù)據(jù),上圖中,紅色和藍色的點就是數(shù)據(jù),點越大表示權(quán)重越高,看看右下角的圖片,當m=150的時候,獲取的模型已經(jīng)幾乎能夠?qū)⒓t色和藍色的點區(qū)分開了。
Boosting可以用下面的公式來表示:
訓練集中一共有n個點,我們可以為里面的每一個點賦上一個權(quán)重Wi(0 <= i < n),表示這個點的重要程度,通過依次訓練模型的過程,我們對點的權(quán)重進行修正,如果分類正確了,權(quán)重降低,如果分類錯了,則權(quán)重提高,初始的時候,權(quán)重都是一樣的。上圖中綠色的線就是表示依次訓練模型,可以想象得到,程序越往后執(zhí)行,訓練出的模型就越會在意那些容易分錯(權(quán)重高)的點。當全部的程序執(zhí)行完后,會得到M個模型,分別對應(yīng)上圖的y1(x)…yM(x),通過加權(quán)的方式組合成一個最終的模型YM(x)。
我覺得Boosting更像是一個人學習的過程,開始學一樣東西的時候,會去做一些習題,但是常常連一些簡單的題目都會弄錯,但是越到后面,簡單的題目已經(jīng)難不倒他了,就會去做更復(fù)雜的題目,等到他做了很多的題目后,不管是難題還是簡單的題都可以解決掉了。
Gradient Boosting方法:
其實Boosting更像是一種思想,Gradient Boosting是一種Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型損失函數(shù)的梯度下降方向。這句話有一點拗口,損失函數(shù)(loss function)描述的是模型的不靠譜程度,損失函數(shù)越大,則說明模型越容易出錯(其實這里有一個方差、偏差均衡的問題,但是這里就假設(shè)損失函數(shù)越大,模型越容易出錯)。如果我們的模型能夠讓損失函數(shù)持續(xù)的下降,則說明我們的模型在不停的改進,而***的方式就是讓損失函數(shù)在其梯度(Gradient)的方向上下降。
下面的內(nèi)容就是用數(shù)學的方式來描述Gradient Boosting,數(shù)學上不算太復(fù)雜,只要潛下心來看就能看懂:)
可加的參數(shù)的梯度表示:
假設(shè)我們的模型能夠用下面的函數(shù)來表示,P表示參數(shù),可能有多個參數(shù)組成,P = {p0,p1,p2….},F(xiàn)(x;P)表示以P為參數(shù)的x的函數(shù),也就是我們的預(yù)測函數(shù)。我們的模型是由多個模型加起來的,β表示每個模型的權(quán)重,α表示模型里面的參數(shù)。為了優(yōu)化F,我們就可以優(yōu)化{β,α}也就是P。
![]()
我們還是用P來表示模型的參數(shù),可以得到,Φ(P)表示P的likelihood函數(shù),也就是模型F(x;P)的loss函數(shù),Φ(P)=…后面的一塊看起來很復(fù)雜,只要理解成是一個損失函數(shù)就行了,不要被嚇跑了。
 既然模型(F(x;P))是可加的,對于參數(shù)P,我們也可以得到下面的式子:
既然模型(F(x;P))是可加的,對于參數(shù)P,我們也可以得到下面的式子: 這樣優(yōu)化P的過程,就可以是一個梯度下降的過程了,假設(shè)當前已經(jīng)得到了m-1個模型,想要得到第m個模型的時候,我們首先對前m-1個模型求梯度。得到最快下降的方向,gm就是最快下降的方向。
這樣優(yōu)化P的過程,就可以是一個梯度下降的過程了,假設(shè)當前已經(jīng)得到了m-1個模型,想要得到第m個模型的時候,我們首先對前m-1個模型求梯度。得到最快下降的方向,gm就是最快下降的方向。
 這里有一個很重要的假設(shè),對于求出的前m-1個模型,我們認為是已知的了,不要去改變它,而我們的目標是放在之后的模型建立上。就像做事情的時候,之前做錯的事就沒有后悔藥吃了,只有努力在之后的事情上別犯錯:
這里有一個很重要的假設(shè),對于求出的前m-1個模型,我們認為是已知的了,不要去改變它,而我們的目標是放在之后的模型建立上。就像做事情的時候,之前做錯的事就沒有后悔藥吃了,只有努力在之后的事情上別犯錯:
![]() 我們得到的新的模型就是,它就在P似然函數(shù)的梯度方向。ρ是在梯度方向上下降的距離。
我們得到的新的模型就是,它就在P似然函數(shù)的梯度方向。ρ是在梯度方向上下降的距離。
![]() 我們最終可以通過優(yōu)化下面的式子來得到***的ρ:
我們最終可以通過優(yōu)化下面的式子來得到***的ρ:
![]()
可加的函數(shù)的梯度表示:
上面通過參數(shù)P的可加性,得到了參數(shù)P的似然函數(shù)的梯度下降的方法。我們可以將參數(shù)P的可加性推廣到函數(shù)空間,我們可以得到下面的函數(shù),此處的fi(x)類似于上面的h(x;α),因為作者的文獻中這樣使用,我這里就用作者的表達方法:
 同樣,我們可以得到函數(shù)F(x)的梯度下降方向g(x)
同樣,我們可以得到函數(shù)F(x)的梯度下降方向g(x)
 最終可以得到第m個模型fm(x)的表達式:
最終可以得到第m個模型fm(x)的表達式:
![]()
通用的Gradient Descent Boosting的框架:
下面我將推導(dǎo)一下Gradient Descent方法的通用形式,之前討論過的:
 對于模型的參數(shù){β,α},我們可以用下面的式子來進行表示,這個式子的意思是,對于N個樣本點(xi,yi)計算其在模型F(x;α,β)下的損失函數(shù),***的{α,β}就是能夠使得這個損失函數(shù)最小的{α,β}。
對于模型的參數(shù){β,α},我們可以用下面的式子來進行表示,這個式子的意思是,對于N個樣本點(xi,yi)計算其在模型F(x;α,β)下的損失函數(shù),***的{α,β}就是能夠使得這個損失函數(shù)最小的{α,β}。![]() 表示兩個m維的參數(shù):
表示兩個m維的參數(shù):
![]() 寫成梯度下降的方式就是下面的形式,也就是我們將要得到的模型fm(x)的參數(shù){αm,βm}能夠使得fm的方向是之前得到的模型Fm-1(x)的損失函數(shù)下降最快的方向:
寫成梯度下降的方式就是下面的形式,也就是我們將要得到的模型fm(x)的參數(shù){αm,βm}能夠使得fm的方向是之前得到的模型Fm-1(x)的損失函數(shù)下降最快的方向:
![]()
對于每一個數(shù)據(jù)點xi都可以得到一個gm(xi),最終我們可以得到一個完整梯度下降方向
![]()
 為了使得fm(x)能夠在gm(x)的方向上,我們可以優(yōu)化下面的式子得到,可以使用最小二乘法:
為了使得fm(x)能夠在gm(x)的方向上,我們可以優(yōu)化下面的式子得到,可以使用最小二乘法:
![]() 得到了α的基礎(chǔ)上,然后可以得到βm。
得到了α的基礎(chǔ)上,然后可以得到βm。 ![]() 最終合并到模型中:
最終合并到模型中:
![]()
算法的流程圖如下
 之后,作者還說了這個算法在其他的地方的推廣,其中,Multi-class logistic regression and classification就是GBDT的一種實現(xiàn),可以看看,流程圖跟上面的算法類似的。這里不打算繼續(xù)寫下去,再寫下去就成論文翻譯了,請參考文章:Greedy function Approximation – A Gradient Boosting Machine,作者Freidman。
之后,作者還說了這個算法在其他的地方的推廣,其中,Multi-class logistic regression and classification就是GBDT的一種實現(xiàn),可以看看,流程圖跟上面的算法類似的。這里不打算繼續(xù)寫下去,再寫下去就成論文翻譯了,請參考文章:Greedy function Approximation – A Gradient Boosting Machine,作者Freidman。
總結(jié):
本文主要談了談Boosting與Gradient Boosting的方法,Boosting主要是一種思想,表示“知錯就改”。而Gradient Boosting是在這個思想下的一種函數(shù)(也可以說是模型)的優(yōu)化的方法,首先將函數(shù)分解為可加的形式(其實所有的函數(shù)都是可加的,只是是否好放在這個框架中,以及最終的效果如何)。然后進行m次迭代,通過使得損失函數(shù)在梯度方向上減少,最終得到一個優(yōu)秀的模型。值得一提的是,每次模型在梯度方向上的減少的部分,可以認為是一個“小”的或者“弱”的模型,最終我們會通過加權(quán)(也就是每次在梯度方向上下降的距離)的方式將這些“弱”的模型合并起來,形成一個更好的模型。
原文鏈接:http://www.cnblogs.com/LeftNotEasy/archive/2011/01/02/machine-learning-boosting-and-gradient-boosting.html