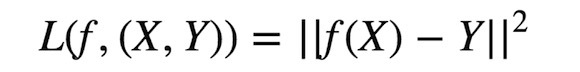Kaggle機器學習之模型融合(stacking)心得
此文道出了本人學習Stacking入門級應用的心路歷程。
在學習過程中感謝@貝爾塔的模型融合方法,以及如何在 Kaggle 首戰中進入前 10%這篇文章(作者是章凌豪)。對于兩位提供的信息,感激不盡。同時還有Kaggle上一些關于ensemble的文章和代碼,比如這篇。
本文適用于被stacking折磨的死去活來的新手,在網上為數不多的stacking內容里,我已經假設你早已經看過了上述所提到的那幾篇有用的文章了。但是,看完之后內心還是臥槽的。我希望下面的內容能成為,你在學習stacking的曲折道路上的一個小火把,給你提供一些微弱的光亮。
本文以Kaggle的Titanic(泰坦尼克預測)入門比賽來講解stacking的應用(兩層!)。
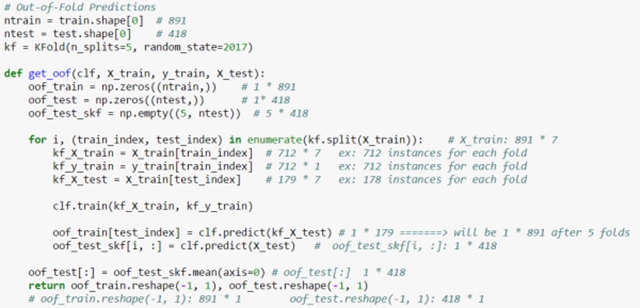
數據的行數:train.csv有890行,也就是890個人,test.csv有418行(418個人)。
而數據的列數就看你保留了多少個feature了,因人而異。我自己的train保留了 7+1(1是預測列)。
在網上為數不多的stacking內容里,相信你早看過了這張圖:
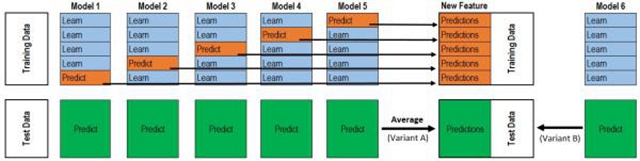
這張圖,如果你能一下子就能看懂,那就OK。
如果一下子看不懂,就麻煩了,在接下來的一段時間內,你就會臥槽臥槽地持續懵逼……
因為這張圖***‘誤導性’。(注意!我沒說這圖是錯的,盡管它就是錯的!!!但是在網上為數不多教學里有張無碼圖就不錯啦,感恩吧,我這個小弱雞)。
我把圖改了一下:
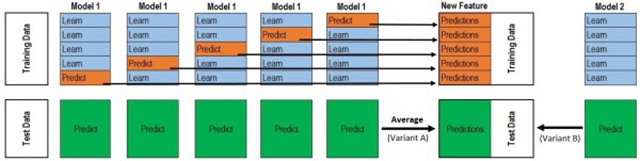
對于每一輪的 5-fold,Model 1都要做滿5次的訓練和預測。
Titanic 栗子:
Train Data有890行。(請對應圖中的上層部分)
每1次的fold,都會生成 713行 小train, 178行 小test。我們用Model 1來訓練 713行的小train,然后預測 178行 小test。預測的結果是長度為 178 的預測值。
這樣的動作走5次! 長度為178 的預測值 X 5 = 890 預測值,剛好和Train data長度吻合。這個890預測值是Model 1產生的,我們先存著,因為,一會讓它將是第二層模型的訓練來源。
重點:這一步產生的預測值我們可以轉成 890 X 1 (890 行,1列),記作 P1 (大寫P)
接著說 Test Data 有 418 行。(請對應圖中的下層部分,對對對,綠綠的那些框框)
每1次的fold,713行 小train訓練出來的Model 1要去預測我們全部的Test Data(全部!因為Test Data沒有加入5-fold,所以每次都是全部!)。此時,Model 1的預測結果是長度為418的預測值。
這樣的動作走5次!我們可以得到一個 5 X 418 的預測值矩陣。然后我們根據行來就平均值,***得到一個 1 X 418 的平均預測值。
重點:這一步產生的預測值我們可以轉成 418 X 1 (418行,1列),記作 p1 (小寫p)
走到這里,你的***層的Model 1完成了它的使命。
***層還會有其他Model的,比如Model 2,同樣的走一遍, 我們有可以得到 890 X 1 (P2) 和 418 X 1 (p2) 列預測值。
這樣吧,假設你***層有3個模型,這樣你就會得到:
來自5-fold的預測值矩陣 890 X 3,(P1,P2, P3) 和 來自Test Data預測值矩陣 418 X 3, (p1, p2, p3)。
—————————————–
到第二層了………………
來自5-fold的預測值矩陣 890 X 3 作為你的Train Data,訓練第二層的模型
來自Test Data預測值矩陣 418 X 3 就是你的Test Data,用訓練好的模型來預測他們吧。
—————————————
*** ,放出一張Python的Code,在網上為數不多的stacking內容里, 這個幾行的code你也早就看過了吧,我之前一直卡在這里,現在加上一點點注解,希望對你有幫助: