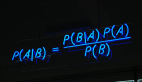輕松入門機器學習排序LTR之:線性模型
LTR 的入門模型就是線性模型,本文以線性模型為例,針對搜索排序的場景,通俗地介紹了機器學習的基本思想和實現步驟。作為 LTR 系列的第三篇,相信通過本文你已經可以輕松地入門 LTR。
很多搜索達人都有這樣一種沖動,想要“通過機器學習獲得最優權重”然后用于搜索查詢中。對于搜索這件事兒來說有點像打地鼠游戲,正如通常人們所說的“如果我能選擇優化‘標題匹配’的權重還是‘內容匹配’的權重,那我肯定會做得更好”!
這種學習何種權重應用于查詢的本能,就是最簡化機器學習排序(learning to rank,LTR)模型的根本原理:線性模型。沒錯,就是傳說中的線性回歸!線性回歸非常簡單易用,甚至感覺一點兒都不像是機器學習;更像是高中生的統計學一樣,理解該模型及其原理也非常地容易。
本系列文章中,我想先介紹成功實施 LTR 背后的關鍵算法,從線性回歸開始,逐步到梯度 boosting(不同種類的 boosting 算法一起)、RankSVM 和隨機森林等算法。
LTR 首先是一個回歸問題
對于本系列的文章,正如你在前一篇及文檔中了解到的,我想把 LTR 映射為一個更加通用的問題:回歸。回歸問題需要訓練一個模型,從而把一組數值特征映射到一個預測數值。
舉個例子:你需要什么樣的數據才能預測一家公司的利潤?可能會有,手邊的歷史公共財務數據,包括雇員數量、股票價格、收益及現金流等。假設已知某些公司的數據,你的模型經過訓練后用于預測這些變量(或其子集)的函數即利潤。對于一家新公司,你可以使用這個函數來預測該公司的利潤。
LTR 同樣是一個回歸問題。你手頭上有一系列評價數據,來衡量一個文檔與某個查詢的相關度等級。我們的相關度等級取值從 A 到 F,更常見的情況是取值從 0(完全不相關)到 4(非常相關)。如果我們先考慮一個關鍵詞搜索的查詢,如下示例:
- grade,movie,keywordquery
- 4,Rocky,rocky
- 0,Turner and Hootch,rocky
- 3,Rocky II,rocky
- 1,Rambo,rocky
- ...
當構建一個模型來預測作為一個時間信號排序函數的等級時,LTR 就成為一個回歸問題。 相關度搜索中的召回,即我們所說的信號,表示查詢和文檔間關系的任意度量;更通用的名稱叫做特征,但我個人更建議叫長期信號。原因之一是,信號是典型的獨立于查詢的——即該結果是通過度量某個關鍵詞(或查詢的某個部分)與文檔的相關程度;某些是度量它們的關系。因此我們可以引入其他信號,包括查詢特有的或者文檔特有的,比如一篇文章的發表日期,或者一些從查詢抽取出的實體(如“公司名稱”)。
來看看上面的電影示例。你可能懷疑有 2 個依賴查詢的信號能幫助預測相關度:
一個搜索關鍵詞在標題屬性中出現過多少次一個搜索關鍵詞在摘要屬性中出現過多少次擴展上面的評價,可能會得到如下 CSV 文件所示的回歸訓練集,把具體的信號值映射為等級:
- grade,numTitleMatches,numOverviewMatches
- 4,1,1
- 0,0,0
- 3,0,3
- 1,0,1
你可以像線性回歸一樣應用回歸流程,從而通過其他列來預測第一列。也可以在已有的搜索引擎像 Solr 或 Elasticsearch 之上來構建這樣一個系統。
我回避了一個復雜問題,那就是:如何獲得這些評價?如何知道一個文檔對一個查詢來說是好還是壞?理解用戶分析?專家人工分析?這通常是最難解決的——而且是跟特定領域非常相關的!提出假設數據來建立模型雖然挺好的,但純屬做無用功!
線性回歸 LTR
如果你學過一些統計學,可能已經很熟悉線性回歸了。線性回歸把回歸問題定義為一個簡單的線性函數。比如,在 LTR 中我們把上文的第一信號(一個搜索關鍵詞在標題屬性中出現過多少次)叫做 t,第二信號(一個搜索關鍵詞在摘要屬性中出現過多少次)叫做 o,我們的模型能生成一個函數 s,像下面這樣對相關度來打分:
- s(t, o) = c0 + c1 * t + c2 * o
我們能評估出最佳擬合系數 c0,c1,c2 等,并使用最小二乘擬合的方法來預測我們的訓練數據。這里就不贅述了,重點是我們能找到 c0,c1,c2 等來最小化實際等級 g 與預測值 s(t,o) 之間的誤差。如果溫習下線性代數,會發現這就像簡單的矩陣數學。
使用線性回歸你會更滿意,包括決策確實是又一個排序信號,我們定義為 t*o。或者另一個信號 t2,實踐中一般定義為 t^2 或者 log(t),或者其他你認為有利于相關度預測的最佳公式。接下來只需要把這些值作為額外的列,用于線性回歸學習系數。
任何模型的設計、測試和評估是一個更深的藝術,如果希望了解更多,強烈推薦統計學習概論。
使用 sklearn 實現線性回歸 LTR
為了更直觀地體驗,使用 Python 的 sklearn 類庫來實現回歸是一個便捷的方式。如果想使用上文數據通過線性回歸嘗試下簡單的 LTR 訓練集,可以把我們嘗試的相關度等級預測值記為 S,我們看到的信號將預測該得分并記為 X。
我們將使用一些電影相關度數據嘗試點有趣的事情。這里有一個搜索關鍵詞“Rocky”的相關度等級數據集。召回我們上面的評判表,轉換為一個訓練集。一起來體驗下真實的訓練集(注釋會幫助我們了解具體過程)。我們將檢查的三個排序信號,包括標題的 TF
IDF 得分、簡介的 TF
IDF 得分以及電影觀眾的評分。
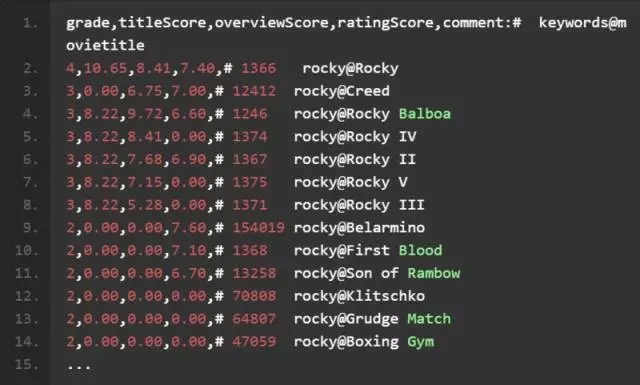
所以接下來直接來到代碼的部分!下面的代碼從一個 CSV 文件讀取數據到一個 numpy 數組;該數組是二維的,第一維作為行,第二維作為列。在下面的注釋中可以看到很新潮的數組切片是如何進行的:
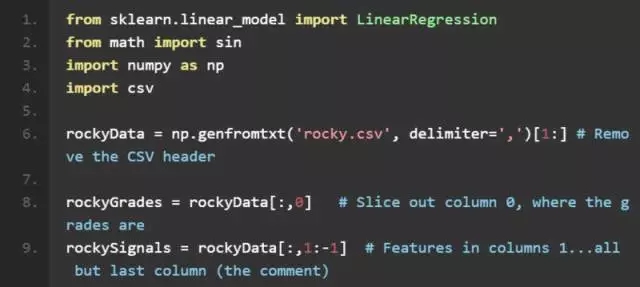
不錯!我們已準備好進行一個簡單線性回歸了。這里我們使用一個經典的判斷方法:方程比未知數多!因此我們需要使用常最小二乘法來估算特征 rockySignals 和等級 rockyGrades 間的關系。很簡單,這就是 numpy 線性回歸所做的:
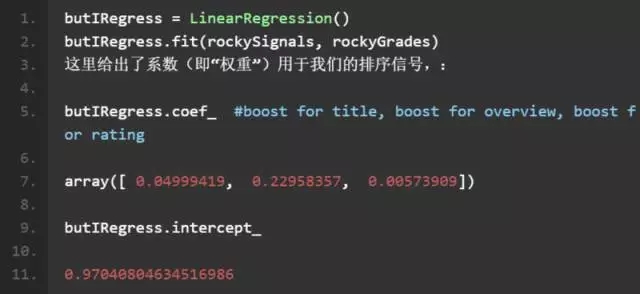
漂亮!相關度解決了!(真的嗎?)我們可以使用這些來建立一個排序函數。我們已經學習到了分別使用什么樣的權重到標題和簡介屬性。
截至目前,我忽略了一部分事項,即我們需要考量如何評價模型和數據的匹配度。在本文的結尾,我們只是想看看一般情況下這些模型是如何工作。但不只是假設該模型非常適合訓練集數據是個不錯的想法,總是需要回退一些數據來測試的。接下來的博文會分別介紹這些話題。
使用模型對查詢打分
我們通過這些系數可以建立自己的排序函數。做這些只是為了描述目的,sk-learn 的線性回歸帶有預測方法,能評估作為輸入的模型,但是構建我們自己的更有意思:

使用該函數我們可以獲得檢索“Rambo”時,這兩部候選電影的相關度得分:

現在對 Rambo 和 First Blood 打分,看看下哪一個跟查詢“Rambo”更相關!

結果得分分別是 Rambo 3.670 以及 First Blood 3.671。
非常接近!First Blood 稍微高于 Rambo 一點兒獲勝。原因是這樣——Rambo 是一個精確匹配,而 First Blood 是 Rambo 電影前傳!因此我們不應該真的讓模型如此可信,并沒有那么多的例子達到那個水平。更有趣的是簡介得分的系數比標題得分的系數大。所以至少在這個例子中我們的模型顯示,簡介中提到的關鍵字越多,最終的相關度往往越高。至此我們已經學習到一個不錯的處理策略,用來解決用戶眼里的相關度!
把這個模型加進來會更有意思,這很好理解,并且產生了很合理的結果;但是特征的直接線性組合通常會因為相關度應用而達不到預期。由于缺乏這樣的理由,正如 Flax 的同行所言,直接加權 boosting 也達不到預期。
為什么?細節決定成敗!
從前述例子中可以發現,一些非常相關的電影確實有很高的 TF*IDF 相關度得分,但是模型卻傾向于概要字段與相關度更加密切。實際上何時標題匹配以及何時概要匹配還依賴于其他因素。
在很多問題中,相關度等級與標題和摘要屬性的得分并不是一個簡單的線性關系,而是與上下文有關。如果就想直接搜索一個標題,那么標題肯定會更加匹配;但是對于并不太確定想要搜索標題,還是類別,或者電影的演員,甚至其他屬性的情形,就不太好辦了。
換句話說,相關度問題看起來并非是一個純粹的最優化問題:
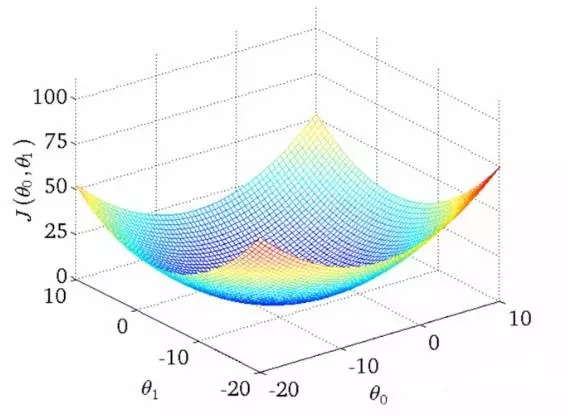
實踐中的相關度要更加復雜。并沒有一個神奇的最優解,寧可說很多局部最優依賴于很多其他因子的! 為什么呢?換句話說,相關度看起來如圖所示:
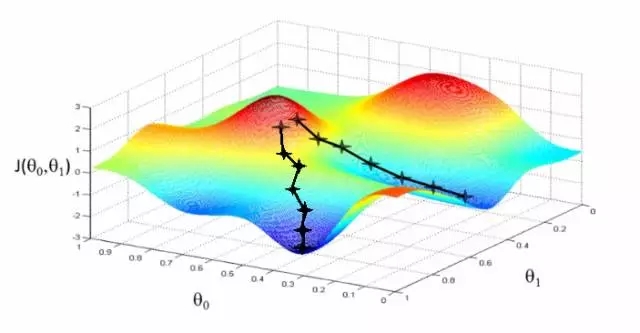
可以想象這些圖(吳恩達機器學習課程中的干貨)用于展示“相關度錯誤” —— 離我們正在學習的分數還有多遠。兩個θ變量的映射表示標題和摘要的相關度得分。第一張圖中有一個單一的最優值,該處的“相關度錯誤”最小 —— 一個理想的權重設置應用這兩個查詢。第二個更加實際一些:波浪起伏、上下文相關的局部最小。有時與一個非常高的標題權重值有關,或者是一個非常低的標題權重!
與上下文和細微差別密切相關!
本文到此為止。后續文章將會更多關注如何精確量化模型的適用程度。使用什么樣的度量方式來評價一個模型的好壞? 這將是很重要的一步,旨在檢驗其他方法在捕捉細微差別方面能否做得更好。