詳細(xì)解析 hadoop 分布式部署

1.硬件環(huán)境
共有 3 臺(tái)機(jī)器,均使用的 linux 系統(tǒng),Java 使用的是 jdk1.6.0。 配置如下:
hadoop1.example.com:192.168.2.1(NameNode)
hadoop2.example.com:192.168.2.2(DataNode)
hadoop3.example.com:192.168.2.3 (DataNode)
hadoop4.example.com:192.168.2.4
主機(jī)與IP之間有正確解析
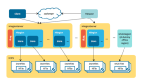
對(duì)于 Hadoop 來(lái)說(shuō),在 HDFS 看來(lái),節(jié)點(diǎn)分為 Namenode 和 Datanode,其中Namenode 只有一個(gè), Datanode 可以是很多;在 MapReduce 看來(lái),節(jié)點(diǎn)又分為Jobtracker 和 Tasktracker,其中 Jobtracker 只有一個(gè),Tasktracker 可以是很多。我是將 namenode 和 jobtracker 部署在 hadoop1 上, hadoop2, hadoop3 作為 datanode和 tasktracker 。當(dāng)然你也可以將 namenode ,datanode ,jobtracker,tasktracker 全部部署在一臺(tái)機(jī)器上(這樣就是偽分布式)。
2.目錄結(jié)構(gòu)
由于 Hadoop 要求所有機(jī)器上 hadoop 的部署目錄結(jié)構(gòu)要相同,并且都有一個(gè)相同的用戶名的帳戶。
我 的 三 臺(tái) 機(jī) 器 上 是 這 樣 的 : 都 有 一 個(gè) hadoop 的 帳 戶 , 主 目 錄是/home/hadoop。
添加用戶hadoop
- #userad -u 800 hadoop
下載hadop-1.2.1.tar.gz
解壓 #tar zxf hadop-1.2.1.tar.gz
- #ln -s hadoop-1.2.1 hadoop
- #mv hadoop-1.2.1 /home/hadoop/
- #cd /home/hadoop
- #chown -R hadoop.hadoop hadoop-1.2.1/
- #passwd hadoop 給用戶hadoop創(chuàng)建密碼
下載jdk-6u32-linux-x64.bin
- sh jdk-6u32-linux-x64.bin
- cd ~
- mv jdk1.6.0_32 hadoop-1.2.1/
- cd hadoop-1.2.1/
創(chuàng)建軟鏈接,以便與日后的更新、升級(jí)
ln -s jdk jdk1.6.0_32
3.SSH設(shè)置
在 Hadoop 啟動(dòng)以后,Namenode 是通過(guò) SSH(Secure Shell)來(lái)啟動(dòng)和停止各個(gè)節(jié)點(diǎn)上的各種守護(hù)進(jìn)程的,這就需要在節(jié)點(diǎn)之間執(zhí)行指令的時(shí)候是不需要輸入密碼的方式,故我們需要配置 SSH 使用無(wú)密碼公鑰認(rèn)證的方式。
首先要保證每臺(tái)機(jī)器上都裝了 SSH 服務(wù)器,且都正常啟動(dòng)。實(shí)際中我們用的都是 OpenSSH,這是 SSH 協(xié)議的一個(gè)免費(fèi)開(kāi)源實(shí)現(xiàn)。
以本文中的 3 臺(tái)機(jī)器為例,現(xiàn)在 hadoop1 是主節(jié)點(diǎn),它需要主動(dòng)發(fā)起 SSH連接到 hadoop2 ,對(duì)于 SSH 服務(wù)來(lái)說(shuō), hadoop1 就是 SSH 客戶端,而hadoop2,hadoop3 則是 SSH 服務(wù)端,因此在 hadoop2,hadoop3 上需要確定 sshd 服務(wù)已經(jīng)啟動(dòng)。簡(jiǎn)單的說(shuō),在 hadoop1 上需要生成一個(gè)密鑰對(duì),即一個(gè)私鑰,一個(gè)公鑰。將公鑰拷貝到 hadoop2 上,這樣,比如當(dāng) hadoop1 向 hadoop2 發(fā)起 ssh 連接的時(shí)候,hadoop2 上就會(huì)生成一個(gè)隨機(jī)數(shù)并用 hadoop1 的公鑰對(duì)這個(gè)隨機(jī)數(shù)進(jìn)行加密并發(fā)送給 hadoop1,hadoop1 收到這個(gè)加密的數(shù)以后用私鑰進(jìn)行解密,并將解密后的數(shù)發(fā)送回hadoop2,hadoop2 確認(rèn)解密的數(shù)無(wú)誤后就允許 hadoop1 進(jìn)行連接了。這就完成了一次公鑰認(rèn)證過(guò)程。
對(duì)于本文中的 3 臺(tái)機(jī)器,首先在 hadoop1 上生成密鑰對(duì):
- #su - hadoop
- $ssh-keygen
這個(gè)命令將為 hadoop1 上的用戶 hadoop 生成其密鑰對(duì)。生成的密鑰對(duì)id_rsa,id_rsa.pub,在/home/hadoop/.ssh 目錄下。
- $ssh-copy-id localhost
- $ssh-copy-id 192.168.2.2
- $ssh-copy-id 192.168.2.3
發(fā)布密鑰到你本地和hadoop2、hadoop3
試著登錄本地和hadoop2、hadoop3看是否有密碼驗(yàn)證,無(wú)密碼即驗(yàn)證成功
下載jdk-6u32-linux-x64.bin
- sh jdk-6u32-linux-x64.bin
- cd ~
- mv jdk1.6.0_32 hadoop-1.2.1/
- cd hadoop-1.2.1/
創(chuàng)建軟鏈接
ln -s jdk jdk1.6.0_32
4.環(huán)境變量
在 ~/hadoop-1.2.1/conf/ 目 錄 下 的 hadoop-env.sh 中 設(shè) 置Hadoop 需 要 的 環(huán) 境 變 量 , 其 中 JAVA_HOME 是 必 須 設(shè) 定 的 變 量 。HADOOP_HOME 變量可以設(shè)定也可以不設(shè)定,如果不設(shè)定, HADOOP_HOME默認(rèn)的是 bin 目錄的父目錄,即本文中的/home/hadoop/hadoop。
vim~/hadoop-1.2.1/conf/hadoop-env.sh
export JAVA_HOME=/home/hadoop/hadoop/jdk
先進(jìn)行簡(jiǎn)單測(cè)試:
- $cd /home/hadoop/hadoop/
- $mkdir input
- $cp conf/* input/
- $bin/hadoop jar hadoop-examples-1.2.1.jar
- $bin/hadoop jar hadoop-examples-1.2.1.jar grep input output 'dfs[a-z.]+'
- $cd output
- $cat *
統(tǒng)計(jì)文件中的單詞:
- $bin/hadoop jar hadoop-examples-1.2.1.jar
- $bin/hadoop jar hadoop-examples-1.2.1.jar wordcount input test
- $cd test/
- $cat *
#p#
5.hadoop配置文件
$cd /home/hadoop/hadoop/conf
conf/core-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop1.example.com:9000</value>
</property></configuration>
conf/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property></configuration>
conf/mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop1.example.com:9001</value>
</property></configuration>
偽分布式測(cè)試:
$mkdir ~/bin
$ln -s /home/hadoop/hadoop/jdk/bin/jps ~/bin/
$cd /home/hadoop/hadoop/
$bin/hadoop namenode -format 先進(jìn)行初始化
$bin/start-all.sh
web測(cè)試192.168.2.1:50070
192.168.2.1:50030
$rm -fr input/ output/ test/
$bin/hadoop fs -mkdir input
$bin/hadoop fs -put conf input
$bin/hadoop fs -lsr
192.168.2.1:50075下查看/usr/hadoop/input是否有變化
6.部署Hadoop
前面講的這么多 Hadoop 的環(huán)境變量和配置文件都是在 hadoop1 這臺(tái)機(jī)器上的,現(xiàn)在需要將 hadoop 部署到其他的機(jī)器上,保證目錄結(jié)構(gòu)一致。
$scp -r /home/hadoop/hadoop hadoop2.example.com:/home/hadoop/
$scp -r /home/hadoop/hadoop hadoop3.example.com:/home/hadoop/
$scp -r .ssh/ hadoop2:
$scp -r .ssh/ hadoop3:
注意還要修改以下文件:
$cd /home/hadoop/hadoop/conf
conf/masters
hadoop1.example.com
conf/slaves
hadoop2.example.com
hadoop3.example.com
$ln -s hadoop-1.2.1/ hadoop
$mkdir ~/bin
$ln -s ~/hadoop/jdk/bin/jps ~/bin
至此,可以說(shuō),Hadoop 已經(jīng)在各個(gè)機(jī)器上部署完畢了,下面就讓我們開(kāi)始啟動(dòng) Hadoop 吧。
7. 啟動(dòng) Hadoop
啟動(dòng)之前,我們先要格式化 namenode,先進(jìn)入~/hadoop/目錄,執(zhí)行下面的命令:
- $bin/hadoop namenode –format
不出意外,應(yīng)該會(huì)提示格式化成功。如果不成功,就去 hadoop/logs/目錄下去查看日志文件。
下面就該正式啟動(dòng) hadoop 啦,在 bin/下面有很多啟動(dòng)腳本,可以根據(jù)自己的需要來(lái)啟動(dòng)。
* start-all.sh 啟動(dòng)所有的 Hadoop 守護(hù)。包括 namenode, datanode, jobtracker,tasktrack
* stop-all.sh 停止所有的 Hadoop
* start-mapred.sh 啟動(dòng) Map/Reduce 守護(hù)。包括 Jobtracker 和 Tasktrack
* stop-mapred.sh 停止 Map/Reduce 守護(hù)
* start-dfs.sh 啟動(dòng) Hadoop DFS 守護(hù).Namenode 和 Datanode
* stop-dfs.sh 停止 DFS 守護(hù)
在這里,簡(jiǎn)單啟動(dòng)所有守護(hù):
- [hadoop@hadoop1:hadoop]$bin/start-all.sh
- $jps
查看JobTracker,Jps,SecondaryNameNode,NameNode是否啟動(dòng)成功。
同樣,如果要停止 hadoop,則
- [hadoop@hadoop1:hadoop]$bin/stop-all.sh
#p#
8. HDFS 操作
運(yùn)行 bin/目錄的 hadoop 命令,可以查看 Haoop 所有支持的操作及其用法,這里以幾個(gè)簡(jiǎn)單的操作為例。
建立目錄:
- [hadoop@hadoop1 hadoop]$bin/hadoop dfs -mkdir testdir
在 HDFS 中建立一個(gè)名為 testdir 的目錄,復(fù)制文件:
- [hadoop@hadoop1 hadoop]$bin/hadoop dfs -put /home/large.zip testfile.zip
把 本 地 文 件 large.zip 拷 貝 到 HDFS 的 根 目 錄 /user/hadoop/ 下 , 文 件 名 為testfile.zip,查看現(xiàn)有文件:
- [hadoop@hadoop1 hadoop]$bin/hadoop dfs -ls
9.hadoop 在線更新節(jié)點(diǎn):
新增節(jié)點(diǎn):
1). 在新增節(jié)點(diǎn)上安裝 jdk,并創(chuàng)建相同的 hadoop 用戶,uid 等保持一致
2). 在 conf/slaves 文件中添加新增節(jié)點(diǎn)的 ip
3). 同步 master 上 hadoop 所有數(shù)據(jù)到新增節(jié)點(diǎn)上,路徑保持一致
4). 在新增節(jié)點(diǎn)上啟動(dòng)服務(wù):
- $ bin/hadoop-daemon.sh start datanode
- $ bin/hadoop-daemon.sh start tasktracker
5). 均衡數(shù)據(jù):
$ bin/start-balancer.sh
(1)如果不執(zhí)行均衡,那么 cluster 會(huì)把新的數(shù)據(jù)都存放在新的 datanode 上,這樣會(huì)降低 mapred的工作效率
(2)設(shè)置平衡閾值,默認(rèn)是 10%,值越低各節(jié)點(diǎn)越平衡,但消耗時(shí)間也更長(zhǎng)
- $ bin/start-balancer.sh -threshold 5
在線刪除datanode節(jié)點(diǎn):
1). 在 master 上修改 conf/mapred-site.xml
- <property>
- <name>dfs.hosts.exclude</name>
- <value>/home/hadoop/hadoop-1.2.1/conf/datanode-excludes</value>
- </property>
2). 創(chuàng)建 datanode-excludes 文件,并添加需要?jiǎng)h除的主機(jī),一行一個(gè)
192.168.2.4
3). 在 master 上在線刷新節(jié)點(diǎn)
- $ bin/hadoop dfsadmin -refreshNodes
此操作會(huì)在后臺(tái)遷移數(shù)據(jù),等此節(jié)點(diǎn)的狀態(tài)顯示為 Decommissioned,就可以安全關(guān)閉了。
4). 你可以通過(guò)以下命令查看 datanode 狀態(tài)
- $ bin/hadoop dfsadmin -report
在做數(shù)據(jù)遷移時(shí),此節(jié)點(diǎn)不要參與 tasktracker,否則會(huì)出現(xiàn)異常。
在線刪除tasktracker 節(jié)點(diǎn):
1). 在 master 上修改 conf/mapred-site.xml
- <property>
- <name>mapred.hosts.exclude</name>
- <value>/home/hadoop/hadoop-1.2.1/conf/tasktracker-excludes</value>
- </property>
2. 創(chuàng)建 tasktracker-excludes 文件,并添加需要?jiǎng)h除的主機(jī)名,一行一個(gè)
hadoop4.example.com
3. 在 master 上在線刷新節(jié)點(diǎn)
- $ bin/hadoop mradmin -refreshNodes
4. 登錄 jobtracker 的網(wǎng)絡(luò)接口,進(jìn)行查看。