Storm與Spark:誰才是我們的實時處理利器
譯文實時商務智能這一構想早已算不得什么新生事物(早在2006年維基百科中就出現了關于這一概念的頁面)。然而盡管人們多年來一直在對此類方案進行探討,我卻發現很多企業實際上尚未就此規劃出明確發展思路、甚至沒能真正意識到其中蘊含的巨大效益。
為什么會這樣?一大原因在于目前市場上的實時商務智能與分析工具仍然非常有限。傳統數據倉庫環境針對的主要是批量處理流程,這類方案要么延遲極高、要么成本驚人——當然,也可能二者兼具。
然而已經有多款強大而且易于使用的開源平臺開始興起,欲徹底扭轉目前的不利局面。其中最值得關注的兩大項目分別為Apache Storm與Apache Spark,它們都能為廣大潛在用戶提供良好的實時處理能力。兩套方案都歸屬于Apache軟件基金會,而且除了在功能方面的一部分交集之外、兩款工具還各自擁有著獨特的特性與市場定位。
Storm:實時處理領域的Hadoop
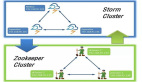
作為一套專門用于事件流處理的分布式計算框架,Storm的誕生可以追溯到當初由BackType公司開發的項目——這家市場營銷情報企業于2011年被Twitter所收購。Twitter旋即將該項目轉為開源并推向GitHub平臺,不過Storm最終還是加入了Apache孵化器計劃并于2014年9月正式成為Apache旗下的***項目之一。
Storm有時候也被人們稱為實時處理領域的Hadoop。Storm項目的說明文檔看起來對這種稱呼也表示認同:“Storm大大簡化了面向龐大規模數據流的處理機制,從而在實時處理領域扮演著Hadoop之于批量處理領域的重要角色。”
為了達成上述目標,Storm在設計思路中充分考慮到大規模可擴展能力、利用一套“故障快速、自動重啟”方案為處理提供容錯性支持、從而有力地保證了每個元組都能切實得到處理。Storm項目默認為消息采取“至少一次”的處理覆蓋保障,但用戶也能夠根據需要實現“僅為一次”的處理方式。
Storm項目主要利用Clojure編寫而成,且既定設計目標在于支持將“流”(例如輸入流)與“栓”(即處理與輸出模塊)結合在一起并構成一套有向無環圖(簡稱DAG)拓撲結構。Storm的拓撲結構運行在集群之上,而Storm調度程序則根據具體拓撲配置將處理任務分發給集群當中的各個工作節點。
大家可以將拓撲結構大致視為MapReduce在Hadoop當中所扮演的角色,只不過Storm的關注重點放在了實時、以流為基礎的處理機制身上,因此其拓撲結構默認永遠運行或者說直到手動中止。一旦拓撲流程啟動,挾帶著數據的流就會不斷涌入系統并將數據交付給栓(而數據仍將在各栓之間循流程繼續傳遞),而這也正是整個計算任務的主要實現方式。隨著處理流程的推進,一個或者多個栓會把數據寫入至數據庫或者文件系統當中,并向另一套外部系統發出消息或者將處理獲得的計算結果提供給用戶。
Storm生態系統的一大優勢在于其擁有豐富的流類型組合,足以從任何類型的來源處獲取數據。雖然大家也可以針對某些具備高度特殊性的應用程序編寫定制化流,但基本上我們總能從龐大的現有源類型中找到適合需要的方案——從Twitter流API到Apache Kafka再到JMS broker,一切盡皆涵蓋于其中。
適配器的存在使其能夠輕松與HDFS文件系統進行集成,這意味著Storm可以在必要時與Hadoop間實現互操作。Storm的另一大優勢在于它對多語言編程方式的支持能力。盡管Storm本身基于Clojure且運行在JVM之上,其流與栓仍然能夠通過幾乎所有語言進行編寫,其中包括那些能夠充分發揮在標準輸入/輸出基礎上使用JSON、并由此實現組件間通信協議優勢的非JVM語言。
總體而言,Storm是一套***可擴展能力、快速驚人且具備容錯能力的開源分布計算系統,其高度專注于流處理領域。Storm在事件處理與增量計算方面表現突出,能夠以實時方式根據不斷變化的參數對數據流進行處理。盡管Storm同時提供原語以實現通用性分布RPC并在理論上能夠被用于任何分布式計算任務的組成部分,但其最為根本的優勢仍然表現在事件流處理方面。
Spark:適用于一切的分布式處理方案
作為另一個專門面向實時分布式計算任務的項目,Spark最初由加州大學伯克利分校的APMLab實驗室所打造,而后又加入到Apache孵化器項目并最終于2014年2月成為其中的***項目之一。與Storm類似,Spark也支持面向流的處理機制,不過這是一套更具泛用性的分布式計算平臺。
有鑒于此,我們不妨將Spark視為Hadoop當中一套足以取代MapReduce的潛在備選方案——二者的區別在于,Spark能夠運行在現有Hadoop集群之上,但需要依賴于YARN對于資源的調度能力。除了Hadoop YARN之外,Spark還能夠以Mesos為基礎實現同樣的資源調度或者利用自身內置調度程度作為獨立集群運行。值得注意的是,如果不將Spark與Hadoop配合使用,那么運行在集群之上時某些網絡/分布式文件系統(包括NFS、AFS等)仍然必要,這樣每個節點才能夠切實訪問底層數據。
Spark項目由Scala編寫而成,而且與Storm一樣都支持多語言編程——不過Spark所提供的特殊API只支持Scala、Java以及Python。Spark并不具備“流”這樣的特殊抽象機制,但卻擁有能夠與存儲在多種不同數據源內的數據實現協作的適配器——具體包括HDFS文件、Cassandra、HBase以及S3。
Spark項目的***亮點在于其支持多處理模式以及支持庫。沒錯,Spark當然支持流模式,但這種支持能力僅源自多個Spark模塊之一,其預設模塊除了流處理之外還支持SQL訪問、圖形操作以及機器學習等。
Spark還提供一套極為便利的交互shell,允許用戶利用Scala或者Python API以實時方式快速建立起原型及探索性數據分析機制。在使用這套交互shell時,大家會很快發現Spark與Storm之間的另一大差異所在:Spark明顯表現出一種偏“功能”的取向,在這里大部分API使用都是由面向原始操作的連續性方法調用來實現的——這與Storm遵循的模式完全不同,后者更傾向于通過創建類與實現接口來完成此類任務。先不論兩種方案孰優孰劣,單單是風格的巨大差異已經足以幫助大家決定哪款系統更適合自己的需求了。
與Storm類似,Spark在設計當中同樣高度重視大規模可擴展能力,而且Spark團隊目前已經擁有一份大型用戶文檔、其中列出的系統方案都運行著包含成千上萬個節點的生產性集群。除此之外,Spark還在最近的2014年Daytona GraySort競賽當中獲得了優勝,成為目前承載100TB級別數據工作負載的***選擇。Spark團隊還保留了多份文檔,其中記錄著Spark ETL如何負責數PB級別生產工作負載的運營。
Spark是一套快速出色、可擴展能力驚人且***靈活性的開源分布式計算平臺,與Hadoop以及Mesos相兼容并且支持多川計算模式,其中包括流、以圖形為核心的操作、SQL訪問外加分布式機器學習等。Spark的實際擴展記錄令人滿意,而且與Storm一樣堪稱構建實時分析與商務智能系統的卓越平臺。
您會如何選擇
那么大家又該如何在Storm與Spark之間做出選擇呢?
如果大家的需求主要集中在流處理與CEP(即復雜事件處理)式處理層面,而且需要從零開始為項目構建一套目標明確的集群設施,那么我個人更傾向于選擇Storm——特別是在現有Storm流機制能夠確切滿足大家集成需求的情況下。這一結論并不屬于硬性要求或者強制規則,但上述因素的存在確實更適合由Storm出面打理。
在另一方面,如果大家打算使用現有Hadoop或者Mesos集群,而且/或者既定流程需要涉及與圖形處理、SQL訪問或者批量處理相關的其它實質性要求,那么Spark則值得加以優先考慮。
另一個需要考量的因素是兩套系統對于多語言的支持能力,舉例來說,如果大家需要使用由R語言或者其它Spark無法原生支持的語言所編寫的代碼,那么Storm無疑在語言支持寬泛性方面占據優勢。同理可知,如果大家必須利用交互式shell通過API調用實現數據探索,那么Spark也能帶來Storm所不具備的優秀能力。
***,大家可能希望在做出決定前再對兩套平臺進行一番詳盡分析。我建議大家先利用這兩套平臺各自建立一個小規模概念驗證項目——而后運行自己的基準工作負載,借此在最終選擇前親身體驗二者的工作負載處理能力是否與預期相一致。
當然,大家也不一定非要從二者之中選擇其一。根據各位工作負載、基礎設施以及具體要求的不同,我們可能會找出一種將Storm與Spark加以結合的理想方案——其它同樣可能發揮作用的工具還包括Kafka、Hadoop以及Flume等等。而這正是開源機制的***亮點所在。
無論大家選擇哪一套方案,這些工具的存在都切實表明實時商務智能市場的游戲規則已經發生了變化。曾經只能為少數精英所掌握的強大選項如今已經進入尋常百姓家——或者說,至少適用于多數中等規模或者大型企業。不要浪費資源,充分享受由此帶來的便利吧。