基于Storm構建分布式實時處理應用初探
最近利用閑暇時間,又重新研讀了一下Storm。認真對比了一下Hadoop,前者更擅長的是,實時流式數據處理,后者更擅長的是基于HDFS,通過MapReduce方式的離線數據分析計算。對于Hadoop,本身不擅長實時的數據分析處理。兩者的共同點都是分布式架構,而且都類似有主/從關系的概念。
本文我不會具體闡述Storm集群和Zookeeper集群如何部署的問題,這里想通過一個實際的案例切入,分析一下如何利用Storm完成實時分析處理數據。
Storm本身是Apache托管的開源的分布式實時計算系統,它的前身是Twitter Storm。在Storm問世以前,處理海量的實時數據信息,大部分是類似于使用消息隊列,加上工作進程/線程的方式。這使得構建這類的應用程序,變得異常的復雜。很多的業務邏輯中,你不得不考慮消息的發送和接收,線程之間的并發控制等等問題。而其中的業務邏輯可能只是占據整個應用的一小部分,而且很難做到業務邏輯的解耦。但是Storm的出現改變了這種局面,它首先抽象出數據流Stream的抽象概念,一個Stream指的是tuples組成的無邊界的序列。后面又繼續提出Spouts、Bolts的概念。Spouts在Storm里面是數據源,專門負責生成流。而Bolts則是以流作為輸入,并重新生成流作為輸出,并且Bolts還會繼續指定它輸入的流應該如何劃分。***Storm是通過拓撲(Topology)這種抽象概念,組織起若干個Spouts、Bolts構成的分布式數據處理網絡。Storm設計的時候,就有意的把Spouts、Bolts組成的拓撲(Topology)網絡通過Thrift服務方式進行封裝,這個做法,使得Storm的Spouts、Bolts組件可以通過目前主流的任意語言實現,使得整個框架的兼容性和擴展性更加優秀。
在Storm里面拓撲(Topology)的概念,非常類似Hadoop里面MapReduce的Job的概念。不同的是Storm的拓撲(Topology)只要你啟動了,它就會一直運行下去,除非你kill掉;而MapReduce的Job最終它是會結束的。基于這樣的模式,使得Storm非常適合處理實時性的數據分析、持續計算、DRPC(分布式RPC)等。
下面就結合實際的案例,設計分析一下,如何利用Storm改善應用的處理性能。
某通信公司的垃圾短信監控平臺,實時地上傳每個省的疑似垃圾短信用戶的垃圾短信內容文件,每個省則根據文件中垃圾短信的內容,解析過濾出,包含指定敏感關鍵字的垃圾短信進行入庫。被入庫的垃圾短信用戶被列為敏感用戶,是重點監控對象,畢竟亂發這些垃圾短信是非常不對的。垃圾短信監控平臺生成的文件速度非常驚人,原來的傳統做法是,根據每個省的每一個地市,對應一個獨立應用,串行化地解析、過濾敏感關鍵字,來進行入庫處理。但是,從現狀來看,程序處理的性能并不高效,常常造成文件積壓,沒有及時處理入庫。
現在,我們就通過Storm來重新梳理、組織一下上述的應用場景。
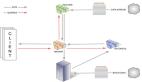
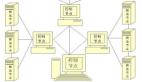
首先,我先說明一下,該案例中Storm集群和Zookeeper集群的部署情況,如下圖所示:

Nimbus對應的主機是192.168.95.134是Storm主節點,其余兩臺從節點Supervisor對應的主機分別是192.168.95.135(主機名:slave1)、192.168.95.136(主機名:slave2)。同樣的,Zookeeper集群也是部署在上述節點上。
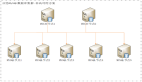
Storm集群和Zookeeper集群會互相通信,因為Storm就是基于Zookeeper的。然后先啟動每個節點的Zookeeper服務,其次分別啟動Storm的Nimbus、Supervisor服務。具體可以到Storm安裝的bin目錄下面啟動服務,啟動命令分別為storm nimbus > /dev/null 2 > &1 &和storm supervisor > /dev/null 2 > &1 &。然后用jps觀察啟動的效果。沒有問題的話,在Nimbus服務對應的主機上啟動Storm UI監控對應的服務,在Storm安裝目錄的bin目錄輸入命令:storm ui >/dev/null 2>&1 &。然后打開瀏覽器輸入:http://{Nimbus服務對應的主機ip}:8080,這里就是輸入:http://192.168.95.134:8080/。觀察Storm集群的部署情況,如下圖所示:

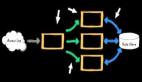
可以發現,我們的Storm的版本是0.9.5,它的從節點(Supervisor)有2個,分別是slave1、slave2。一共的woker的數量是8個(Total slots)。Storm集群我們已經部署完畢,也啟動成功了。現在就利用Storm的方式,重新改寫一下這種敏感信息實時監控過濾的應用。先看下Storm方式的拓撲結構圖:

其中的SensitiveFileReader-591、SensitiveFileReader-592(用戶短信采集器,分地市)代表的是Storm中的Spouts組件,表示一個數據的源頭,這里是表示從服務器的指定目錄下,讀取疑似垃圾短信用戶的垃圾短信內容文件。當然Spouts的組件你可以根據實際的需求,擴展出許多Spouts。
然后讀取出文件中每一行的內容之后,就是分析文件的內容組件了,這里是指:SensitiveFileAnalyzer(監控短信內容拆解分析),它負責分析出文件的格式內容。
為了簡單演示起見,我這里定義文件的格式為如下內容(隨便寫一個例子):home_city=591&user_id=5911000&msisdn=10000&sms_content=abc-slave1。每個列之間用&進行連接。其中home_city=591表示疑似垃圾短信的用戶歸屬地市編碼,591表示福州、592表示廈門;user_id=5911000表示疑似垃圾短信的用戶標識;msisdn=10000表示疑似垃圾短信的用戶手機號碼;sms_content=abc-slave1代表的就是垃圾短信的內容了。SensitiveFileAnalyzer代表的就是Storm中的Bolt組件,用來處理Spouts“流”出的數據。
***,就是我們根據解析好的數據,匹配業務規定的敏感關鍵字,進行過濾入庫了。這里我們是把過濾好的數據存入MySQL數據庫中。負責這項任務的組件是:SensitiveBatchBolt(敏感信息采集處理),當然它也是Storm中的Bolt組件。好了,以上就是完整的Storm拓撲(Topology)結構了。
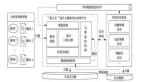
現在,我們對于整個敏感信息采集過濾監控的拓撲結構,有了一個整體的了解之后,我們再來看下如何具體編碼實現!先來看下整個工程的代碼層次結構,它如下圖所示:

首先來看下,我們定義的敏感用戶的數據結構RubbishUsers,假設我們要過濾的敏感用戶的短信內容中,要包含“racketeer”、“Bad”等敏感關鍵字。具體代碼如下:

現在,我們看下敏感信息數據源組件SensitiveFileReader的具體實現,它負責從服務器的指定目錄下面,讀取疑似垃圾短信用戶的垃圾短信內容文件,然后把每一行的數據,發送給下一個處理的Bolt(SensitiveFileAnalyzer),每個文件全部發送結束之后,在當前目錄中,把原文件重命名成后綴bak的文件(當然,你可以重新建立一個備份目錄,專門用來存儲這種處理結束的文件),SensitiveFileReader的具體實現如下:

監控短信內容拆解分析器SensitiveFileAnalyzer,這個Bolt組件,接收到數據源SensitiveFileReader的數據之后,就按照上面定義的格式,對文件中每一行的內容進行解析,然后把解析完畢的內容,繼續發送給下一個Bolt組件:SensitiveBatchBolt(敏感信息采集處理)。現在,我們來看下SensitiveFileAnalyzer這個Bolt組件的實現:

***一個Bolt組件SensitiveBatchBolt(敏感信息采集處理)根據上游Bolt組件SensitiveFileAnalyzer發送過來的數據,然后跟業務規定的敏感關鍵字進行匹配,如果匹配成功,說明這個用戶,就是我們要重點監控的用戶,我們把它通過hibernate采集到MySQL數據庫,統一管理。***要說明的是,SensitiveBatchBolt組件還實現了一個監控的功能,就是定期打印出,我們已經采集到的敏感信息用戶數據。現在給出SensitiveBatchBolt的實現:

由于是通過hibernate入庫到MySQL,所以給出hibernate配置,首先是:hibernate.cfg.xml

對應的ORM映射配置文件rubbish-users.hbm.xml內容如下:

***,還是通過Spring把hibernate集成起來,數據庫連接池用的是:DBCP。對應的Spring配置文件jdbc-hibernate-bean.xml的內容如下:

到此為止,我們已經完成了敏感信息實時監控的所有的Storm組件的開發。現在,我們來完成Storm的拓撲(Topology),由于拓撲(Topology)又分為本地拓撲和分布式拓撲,因此封裝了一個工具類StormRunner(拓撲執行器),對應的代碼如下:

好了,現在我們把上面所有的Spouts/Bolts拼接成“拓撲”(Topology)結構,我們這里用的是分布式拓撲,來進行部署運行。具體的SensitiveTopology(敏感用戶監控Storm拓撲)代碼如下:

到此為止,所有的Storm組件已經開發完畢!現在,我們把上述工程打成jar包,放到Storm集群中運行,具體可以到Nimbus對應的Storm安裝目錄下面的bin目錄,輸入:storm jar + {jar路徑}。
比如我這里是輸入:storm jar /home/tj/install/SensitiveTopology.jar newlandframework.storm.topology.SensitiveTopology,然后,把疑似垃圾短信用戶的垃圾短信內容文件放到指定的服務器下面的目錄(/home/tj/data/591、/home/tj/data/592),***打開剛才的Storm UI,觀察任務的啟動執行情況,這里如下圖所示:

可以看到我們剛才提交的拓撲:SensitiveTopology已經成功提交到Storm集群里面了。這個時候,你可以鼠標點擊SensitiveTopology,然后會打開如下的一個Spouts/Bolts的監控界面,如下圖所示:

我們可以很清楚地看到:Spouts組件(用戶短信采集器):SensitiveFileReader591、SensitiveFileReader592的線程數executors、任務提交emitted情況。以及Bolts組件:監控短信內容拆解分析器(SensitiveFileAnalyzer)、敏感信息采集處理(SensitiveBatchBolt)的運行情況,這樣監控起來就非常方便。
此外,我們還可以到對應的Supervisor服務器對應的Storm安裝目錄下面的logs目錄,查看一下worker的工作日志,我們來看下敏感信息監控過濾的處理情況,截圖如下:

通過SensitiveBatchBolt模塊的監控線程,可以看到,我們目前已經采集到了9個敏感信息用戶了,再來看下,這些包含敏感關鍵字的用戶有沒有入庫MySQL成功?

發現入庫的結果也是9個,和日志打印的數量上是一致的。而且垃圾短信內容sms_content果然都包含了“racketeer”、“Bad”這些敏感關鍵字!完全符合我們的預期。而且,以后文件處理量上來了,我們可以通過調整設置Spouts/Bolts的并行度,和Worker的數量進行化解。當然,你還可以通過水平擴展集群的數量來解決這個問題。
Storm在Apache開源項目的網址是:http://storm.apache.org/,有興趣的朋友可以經常關注一下。官網上面有很權威的技術規范說明,以及如何把Storm和消息隊列、HDFS、HBase有效的集成起來。目前在國內,就我個人看法,對Storm分析應用,做得***的應該算是阿里巴巴,它在原來Storm的基礎上加以改良,開源出JStorm,有興趣的朋友,可以多關注一下。
借助Storm,我們可以很輕松地開發分布式實時處理應用,而上述場景的設計,只是Storm應用的一個案例。相比傳統的單機服務器應用而言,集群化地并行協同計算處理,是云計算、大數據時代的一個趨勢,也是我今后努力學習的方向。故在此寫下自己的學習經驗體會,有不對的地方,還請各位群友批評指正。