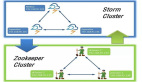
實時處理大數(shù)據(jù)的分布式系統(tǒng)Druid-IO
作者:佚名
Druid 是一個用于大數(shù)據(jù)實時查詢和分析的高容錯、高性能開源分布式系統(tǒng),旨在快速處理大規(guī)模的數(shù)據(jù),并能夠?qū)崿F(xiàn)快速查詢和分析。
Druid 是一個用于大數(shù)據(jù)實時查詢和分析的高容錯、高性能開源分布式系統(tǒng),旨在快速處理大規(guī)模的數(shù)據(jù),并能夠?qū)崿F(xiàn)快速查詢和分析。
Druid 具有以下主要特征:
- 為分析而設(shè)計——Druid 是為 OLAP 工作流的探索性分析而構(gòu)建,它支持各種過濾、聚合和查詢等類;
- 快速的交互式查詢——Druid 的低延遲數(shù)據(jù)攝取架構(gòu)允許事件在它們創(chuàng)建后毫秒內(nèi)可被查詢到;
- 高可用性——Druid 的數(shù)據(jù)在系統(tǒng)更新時依然可用,規(guī)模的擴大和縮小都不會造成數(shù)據(jù)丟失;
- 可擴展——Druid 已實現(xiàn)每天能夠處理數(shù)十億事件和 TB 級數(shù)據(jù)。
當業(yè)務(wù)中出現(xiàn)以下情況時,Druid 是一個很好的技術(shù)方案選擇:
- 需要交互式聚合和快速探究大量數(shù)據(jù)時;
- 需要實時查詢分析時;
- 具有大量數(shù)據(jù)時,如每天數(shù)億事件的新增、每天數(shù) 10T 數(shù)據(jù)的增加;
- 對數(shù)據(jù)尤其是大數(shù)據(jù)進行實時分析時;
- 需要一個高可用、高容錯、高性能數(shù)據(jù)庫時。
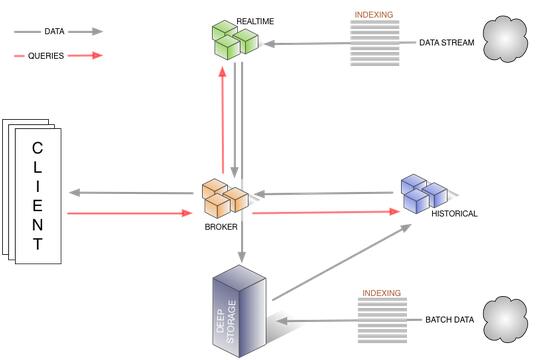
查詢操作中數(shù)據(jù)流和各個節(jié)點的關(guān)系如下圖所示:
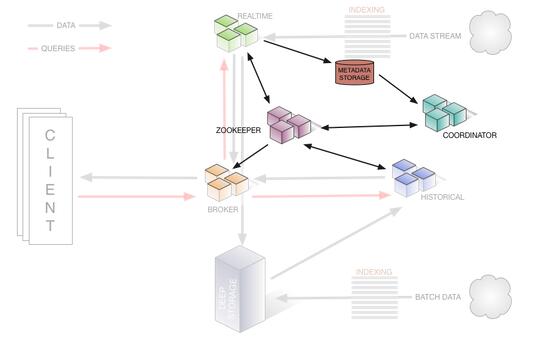
如下圖是 Druid 集群的管理層架構(gòu),該圖展示了相關(guān)節(jié)點和集群管理所依賴的其他組件(如負責服務(wù)發(fā)現(xiàn)的ZooKeeper集群)的關(guān)系:
責任編輯:未麗燕
來源:
開源中國社區(qū)