實(shí)戰(zhàn)指導(dǎo):Ceph存儲(chǔ)性能優(yōu)化總結(jié)
最近一直在忙著搞Ceph存儲(chǔ)的優(yōu)化和測(cè)試,看了各種資料,但是好像沒(méi)有一篇文章把其中的方法論交代清楚,所以呢想在這里進(jìn)行一下總結(jié),很多內(nèi)容并不是我原創(chuàng),只是做一個(gè)總結(jié)。如果其中有任何的問(wèn)題,歡迎各位噴我,以便我提高。
優(yōu)化方法論
做任何事情還是要有個(gè)方法論的,“授人以魚(yú)不如授人以漁”的道理吧,方法通了,所有的問(wèn)題就有了解決的途徑。通過(guò)對(duì)公開(kāi)資料的分析進(jìn)行總結(jié),對(duì)分布式存儲(chǔ)系統(tǒng)的優(yōu)化離不開(kāi)以下幾點(diǎn):
1. 硬件層面
- 硬件規(guī)劃
- SSD選擇
- BIOS設(shè)置
2. 軟件層面
- Linux OS
- Ceph Configurations
- PG Number調(diào)整
- CRUSH Map
- 其他因素
硬件優(yōu)化
1. 硬件規(guī)劃
- Processor
ceph-osd進(jìn)程在運(yùn)行過(guò)程中會(huì)消耗CPU資源,所以一般會(huì)為每一個(gè)ceph-osd進(jìn)程綁定一個(gè)CPU核上。當(dāng)然如果你使用EC方式,可能需要更多的CPU資源。
ceph-mon進(jìn)程并不十分消耗CPU資源,所以不必為ceph-mon進(jìn)程預(yù)留過(guò)多的CPU資源。
ceph-msd也是非常消耗CPU資源的,所以需要提供更多的CPU資源。
- 內(nèi)存
ceph-mon和ceph-mds需要2G內(nèi)存,每個(gè)ceph-osd進(jìn)程需要1G內(nèi)存,當(dāng)然2G更好。
- 網(wǎng)絡(luò)規(guī)劃
萬(wàn)兆網(wǎng)絡(luò)現(xiàn)在基本上是跑Ceph必備的,網(wǎng)絡(luò)規(guī)劃上,也盡量考慮分離cilent和cluster網(wǎng)絡(luò)。
2. SSD選擇
硬件的選擇也直接決定了Ceph集群的性能,從成本考慮,一般選擇SATA SSD作為Journal,Intel® SSD DC S3500 Series基本是目前看到的方案中的***。400G的規(guī)格4K隨機(jī)寫(xiě)可以達(dá)到11000 IOPS。如果在預(yù)算足夠的情況下,推薦使用PCIE SSD,性能會(huì)得到進(jìn)一步提升,但是由于Journal在向數(shù)據(jù)盤(pán)寫(xiě)入數(shù)據(jù)時(shí)Block后續(xù)請(qǐng)求,所以Journal的加入并未呈現(xiàn)出想象中的性能提升,但是的確會(huì)對(duì)Latency有很大的改善。
如何確定你的SSD是否適合作為SSD Journal,可以參考SÉBASTIEN HAN的Ceph: How to Test if Your SSD Is Suitable as a Journal Device?,這里面他也列出了常見(jiàn)的SSD的測(cè)試結(jié)果,從結(jié)果來(lái)看SATA SSD中,Intel S3500性能表現(xiàn)***。
3. BIOS設(shè)置
- Hyper-Threading(HT)
基本做云平臺(tái)的,VT和HT打開(kāi)都是必須的,超線程技術(shù)(HT)就是利用特殊的硬件指令,把兩個(gè)邏輯內(nèi)核模擬成兩個(gè)物理芯片,讓單個(gè)處理器都能使用線程級(jí)并行計(jì)算,進(jìn)而兼容多線程操作系統(tǒng)和軟件,減少了CPU的閑置時(shí)間,提高的CPU的運(yùn)行效率。
- 關(guān)閉節(jié)能
關(guān)閉節(jié)能后,對(duì)性能還是有所提升的,所以堅(jiān)決調(diào)整成性能型(Performance)。當(dāng)然也可以在操作系統(tǒng)級(jí)別進(jìn)行調(diào)整,詳細(xì)的調(diào)整過(guò)程請(qǐng)參考鏈接,但是不知道是不是由于BIOS已經(jīng)調(diào)整的緣故,所以在CentOS 6.6上并沒(méi)有發(fā)現(xiàn)相關(guān)的設(shè)置。
- for CPUFREQ in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do [ -f $CPUFREQ ] || continue; echo -n performance > $CPUFREQ; done
- NUMA
簡(jiǎn)單來(lái)說(shuō),NUMA思路就是將內(nèi)存和CPU分割為多個(gè)區(qū)域,每個(gè)區(qū)域叫做NODE,然后將NODE高速互聯(lián)。 node內(nèi)cpu與內(nèi)存訪問(wèn)速度快于訪問(wèn)其他node的內(nèi)存,NUMA可能會(huì)在某些情況下影響ceph-osd。解決的方案,一種是通過(guò)BIOS關(guān)閉NUMA,另外一種就是通過(guò)cgroup將ceph-osd進(jìn)程與某一個(gè)CPU Core以及同一NODE下的內(nèi)存進(jìn)行綁定。但是第二種看起來(lái)更麻煩,所以一般部署的時(shí)候可以在系統(tǒng)層面關(guān)閉NUMA。CentOS系統(tǒng)下,通過(guò)修改 /etc/grub.conf文件,添加numa=off來(lái)關(guān)閉NUMA。
- kernel /vmlinuz-2.6.32-504.12.2.el6.x86_64 ro root=UUID=870d47f8-0357-4a32-909f-74173a9f0633 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM biosdevname=0 numa=off
#p#
軟件優(yōu)化
1. Linux OS
- Kernel pid max
- echo 4194303 > /proc/sys/kernel/pid_max
- Jumbo frames, 交換機(jī)端需要支持該功能,系統(tǒng)網(wǎng)卡設(shè)置才有效果
- ifconfig eth0 mtu 9000
***設(shè)置
- echo "MTU=9000" | tee -a /etc/sysconfig/network-script/ifcfg-eth0
- /etc/init.d/networking restart
read_ahead, 通過(guò)數(shù)據(jù)預(yù)讀并且記載到隨機(jī)訪問(wèn)內(nèi)存方式提高磁盤(pán)讀操作,查看默認(rèn)值
- cat /sys/block/sda/queue/read_ahead_kb
根據(jù)一些Ceph的公開(kāi)分享,8192是比較理想的值
- echo "8192" > /sys/block/sda/queue/read_ahead_kb
- swappiness, 主要控制系統(tǒng)對(duì)swap的使用,這個(gè)參數(shù)的調(diào)整***見(jiàn)于UnitedStack公開(kāi)的文檔中,猜測(cè)調(diào)整的原因主要是使用swap會(huì)影響系統(tǒng)的性能。
- echo "vm.swappiness = 0" | tee -a /etc/sysctl.conf
- I/O Scheduler,關(guān)于I/O Scheculder的調(diào)整網(wǎng)上已經(jīng)有很多資料,這里不再贅述,簡(jiǎn)單說(shuō)SSD要用noop,SATA/SAS使用deadline。
- echo "deadline" > /sys/block/sd[x]/queue/scheduler
- echo "noop" > /sys/block/sd[x]/queue/scheduler
- cgroup
這方面的文章好像比較少,昨天在和Ceph社區(qū)交流過(guò)程中,Jan Schermer說(shuō)準(zhǔn)備把生產(chǎn)環(huán)境中的一些腳本貢獻(xiàn)出來(lái),但是暫時(shí)還沒(méi)有,他同時(shí)也列舉了一些使用cgroup進(jìn)行隔離的原因。
- 不在process和thread在不同的core上移動(dòng)(更好的緩存利用)
- 減少NUMA的影響
- 網(wǎng)絡(luò)和存儲(chǔ)控制器影響 - 較小
- 通過(guò)限制cpuset來(lái)限制Linux調(diào)度域(不確定是不是重要但是是***實(shí)踐)
- 如果開(kāi)啟了HT,可能會(huì)造成OSD在thread1上,KVM在thread2上,并且是同一個(gè)core。Core的延遲和性能取決于其他一個(gè)線程做什么。
這一點(diǎn)具體實(shí)現(xiàn)待補(bǔ)充!!!
2. Ceph Configurations
[global]

- 查看系統(tǒng)***文件打開(kāi)數(shù)可以使用命令
- cat /proc/sys/fs/file-max
[osd] - filestore

- 調(diào)整omap的原因主要是EXT4文件系統(tǒng)默認(rèn)僅有4K
- filestore queue相關(guān)的參數(shù)對(duì)于性能影響很小,參數(shù)調(diào)整不會(huì)對(duì)性能優(yōu)化有本質(zhì)上提升
[osd] - journal

- Ceph OSD Daemon stops writes and synchronizes the journal with the filesystem, allowing Ceph OSD Daemons to trim operations from the journal and reuse the space.
- 上面這段話的意思就是,Ceph OSD進(jìn)程在往數(shù)據(jù)盤(pán)上刷數(shù)據(jù)的過(guò)程中,是停止寫(xiě)操作的。
[osd] - osd config tuning
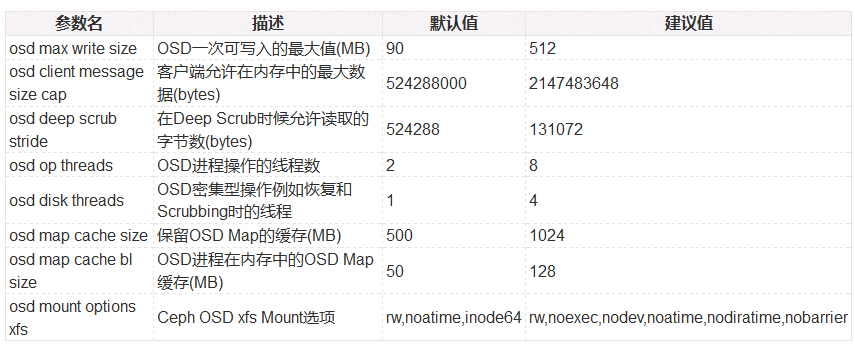
- 增加osd op threads和disk threads會(huì)帶來(lái)額外的CPU開(kāi)銷(xiāo)
[osd] - recovery tuning

[osd] - client tuning

關(guān)閉Debug
#p#
3. PG Number
PG和PGP數(shù)量一定要根據(jù)OSD的數(shù)量進(jìn)行調(diào)整,計(jì)算公式如下,但是***算出的結(jié)果一定要接近或者等于一個(gè)2的指數(shù)。
- Total PGs = (Total_number_of_OSD * 100) / max_replication_count
例如15個(gè)OSD,副本數(shù)為3的情況下,根據(jù)公式計(jì)算的結(jié)果應(yīng)該為500,最接近512,所以需要設(shè)定該pool(volumes)的pg_num和pgp_num都為512.
- ceph osd pool set volumes pg_num 512
- ceph osd pool set volumes pgp_num 512
4. CRUSH Map
CRUSH是一個(gè)非常靈活的方式,CRUSH MAP的調(diào)整取決于部署的具體環(huán)境,這個(gè)可能需要根據(jù)具體情況進(jìn)行分析,這里面就不再贅述了。
5. 其他因素的影響
在今年的(2015年)的Ceph Day上,海云捷迅在調(diào)優(yōu)過(guò)程中分享過(guò)一個(gè)由于在集群中存在一個(gè)性能不好的磁盤(pán),導(dǎo)致整個(gè)集群性能下降的case。通過(guò)osd perf可以提供磁盤(pán)latency的狀況,同時(shí)在運(yùn)維過(guò)程中也可以作為監(jiān)控的一個(gè)重要指標(biāo),很明顯在下面的例子中,OSD 8的磁盤(pán)延時(shí)較長(zhǎng),所以需要考慮將該OSD剔除出集群:
- ceph osd perf
osd fs_commit_latency(ms) fs_apply_latency(ms)
- osd fs_commit_latency(ms) fs_apply_latency(ms)
- 0 14 17
- 1 14 16
- 2 10 11
- 3 4 5
- 4 13 15
- 5 17 20
- 6 15 18
- 7 14 16
- 8 299 329
ceph.conf
- [global]
- fsid = 059f27e8-a23f-4587-9033-3e3679d03b31
- mon_host = 10.10.20.102, 10.10.20.101, 10.10.20.100
- auth cluster required = cephx
- auth service required = cephx
- auth client required = cephx
- osd pool default size = 3
- osd pool default min size = 1
- public network = 10.10.20.0/24
- cluster network = 10.10.20.0/24
- max open files = 131072
- [mon]
- mon data = /var/lib/ceph/mon/ceph-$id
- [osd]
- osd data = /var/lib/ceph/osd/ceph-$id
- osd journal size = 20000
- osd mkfs type = xfs
- osd mkfs options xfs = -f
- filestore xattr use omap = true
- filestore min sync interval = 10
- filestore max sync interval = 15
- filestore queue max ops = 25000
- filestore queue max bytes = 10485760
- filestore queue committing max ops = 5000
- filestore queue committing max bytes = 10485760000
- journal max write bytes = 1073714824
- journal max write entries = 10000
- journal queue max ops = 50000
- journal queue max bytes = 10485760000
- osd max write size = 512
- osd client message size cap = 2147483648
- osd deep scrub stride = 131072
- osd op threads = 8
- osd disk threads = 4
- osd map cache size = 1024
- osd map cache bl size = 128
- osd mount options xfs = "rw,noexec,nodev,noatime,nodiratime,nobarrier"
- osd recovery op priority = 4
- osd recovery max active = 10
- osd max backfills = 4
- [client]
- rbd cache = true
- rbd cache size = 268435456
- rbd cache max dirty = 134217728
- rbd cache max dirty age = 5
總結(jié)
優(yōu)化是一個(gè)長(zhǎng)期迭代的過(guò)程,所有的方法都是別人的,只有在實(shí)踐過(guò)程中才能發(fā)現(xiàn)自己的,本篇文章僅僅是一個(gè)開(kāi)始,歡迎各位積極補(bǔ)充,共同完成一篇具有指導(dǎo)性的文章。
原文鏈接:http://xiaoquqi.github.io/blog/2015/06/28/ceph-performance-optimization-summary/