高性能存儲(chǔ)Ceph:3個(gè)生產(chǎn)案例學(xué)習(xí)Ceph運(yùn)維技巧
本文轉(zhuǎn)載自微信公眾號(hào)「新鈦云服」,作者祝祥 翻譯。轉(zhuǎn)載本文請(qǐng)聯(lián)系新鈦云服公眾號(hào)。
Ceph是一個(gè)統(tǒng)一的分布式存儲(chǔ)系統(tǒng),設(shè)計(jì)初衷是提供較好的性能、可靠性和可擴(kuò)展性。
Ceph項(xiàng)目最早起源于Sage就讀博士期間的工作(最早的成果于2004年發(fā)表),并隨后貢獻(xiàn)給開源社區(qū)。在經(jīng)過了數(shù)年的發(fā)展之后,目前已得到眾多云計(jì)算廠商的支持并被廣泛應(yīng)用。
RedHat及OpenStack都可與Ceph整合以支持虛擬機(jī)鏡像的后端存儲(chǔ)。同時(shí)Ceph也為Kubernetns提供塊,文件,對(duì)象存儲(chǔ)。
當(dāng)在各種生產(chǎn)場(chǎng)景中使用Ceph作為網(wǎng)絡(luò)存儲(chǔ)時(shí),我們可能會(huì)面臨著很多的生產(chǎn)場(chǎng)景。這里有一些案例:
- 在新集群中部分使用舊的服務(wù)器的情況下,將數(shù)據(jù)遷移到新的Ceph新的實(shí)例節(jié)點(diǎn)中;
- 解決Ceph中磁盤空間分配的問題。
為了處理這些問題,我們需要在保持?jǐn)?shù)據(jù)完整的同時(shí)正確刪除OSD。在海量數(shù)據(jù)的情況下,這一點(diǎn)尤其重要。這就是我們將在本文中介紹的內(nèi)容。
下述方法適用于各種版本的Ceph (除非特別說明)。另外,我們將考慮到大量數(shù)據(jù)可以存儲(chǔ)在Ceph中這一場(chǎng)景,因此我們將把某些步驟分解成較小的步驟——以防止數(shù)據(jù)丟失和其他問題。
關(guān)于OSD的幾句話
由于本文所涉及的三種場(chǎng)景中有兩種是與OSD(對(duì)象存儲(chǔ)守護(hù)程序)有關(guān),因此在深入探討之前,我們先簡(jiǎn)單討論一下OSD及其重要性。
首先,應(yīng)該注意,整個(gè)Ceph集群由一組OSD組成。它們?cè)蕉啵珻eph中的可用數(shù)據(jù)量就越大。因此,OSD的主要目的是跨群集節(jié)點(diǎn)存儲(chǔ)對(duì)象數(shù)據(jù),并提供對(duì)其的網(wǎng)絡(luò)訪問(用于讀取,寫入和其他查詢)。
通過在不同OSD之間復(fù)制對(duì)象,可以將復(fù)制參數(shù)設(shè)置為同一級(jí)別。這也是您可能會(huì)遇到問題的地方(我們將在本文后面提供解決方案)。
案例1:優(yōu)雅地從Ceph集群中移除OSD
當(dāng)需要從群集中移除OSD的時(shí)候,這很可能是集群硬件變更的需求(例如,將一臺(tái)服務(wù)器替換為另一臺(tái)服務(wù)器)。這也正是我們當(dāng)前所遇到的場(chǎng)景,同時(shí)也是這一實(shí)際場(chǎng)景觸發(fā)我們寫了這篇文章。
因此,我們的最終目標(biāo)是刪除服務(wù)器上的所有OSD和監(jiān)視器,以便可以將服務(wù)器安全下架。
為了方便起見并避免在執(zhí)行命令時(shí)選擇錯(cuò)誤的OSD,讓我們定義一個(gè)單獨(dú)的變量,其中包含所需OSD的編號(hào)。我們將其稱為${ID}。從現(xiàn)在開始,此變量將替換我們正在使用的OSD的數(shù)量。
首先,讓我們看一下OSD映射關(guān)系:
- root@hv-1 ~ # ceph osd tree
- ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- -1 0.46857 root default
- -3 0.15619 host hv-1
- -5 0.15619 host hv-2
- 1 ssd 0.15619 osd.1 up 1.00000 1.00000
- -7 0.15619 host hv-3
- 2 ssd 0.15619 osd.2 up 1.00000 1.00000
為了使OSD安全脫離群集,我們必須將reweight緩慢降低到零。這樣,我們就可以通過重新均衡的方式,將當(dāng)前需要移除的OSD數(shù)據(jù)遷移到其他OSD中。
為此,請(qǐng)運(yùn)行以下命令:
- ceph osd reweight osd.${ID} 0.98
- ceph osd reweight osd.${ID} 0.88
- ceph osd reweight osd.${ID} 0.78
…依此類推,直到權(quán)重為零。
但是,如果使用norebalance呢?
另外,還有一個(gè)解決方案是使用norebalance+backfill。首先,禁用重新均衡:
- ceph osd set norebalance
現(xiàn)在,您必須將新的OSD添加到CRUSH MAP中,并將舊OSD的權(quán)重設(shè)置為0。對(duì)于要?jiǎng)h除和添加的OSD,將主要親和力設(shè)置為0:
- ceph osd primary-affinity osd.$OLD 0
- ceph osd primary-affinity osd.$NEW 0
然后減小backfill到1并取消norebalance:
- ceph tell osd.* injectargs --osd_max_backfill=1
- ceph osd unset norebalance
之后,Ceph集群將開始數(shù)據(jù)遷移。
注意:這個(gè)解決方案是非常可行的,但是你必須考慮到具體的情況與需求。當(dāng)我們不想在任何OSD Down時(shí)造成過多的網(wǎng)絡(luò)負(fù)載時(shí),我們就可以使用norebalance。
`osd_max_backfill`允許您限制再均衡速度。因此,重新均衡將減慢速度從而降低網(wǎng)絡(luò)負(fù)載。
遵循的步驟
我們必須要逐步重新均衡從而避免數(shù)據(jù)丟失。如果OSD包含大量數(shù)據(jù),則更要如此。如果要確保在運(yùn)行reweight命令后是否一切正常,可以運(yùn)行ceph -s查看集群當(dāng)前的健康狀態(tài)。
此外,您可以在單獨(dú)的終端窗口中運(yùn)行ceph -w以實(shí)時(shí)監(jiān)視數(shù)據(jù)遷移的過程。
清空OSD之后,您可以開始按照標(biāo)準(zhǔn)操作來刪除它。為此,將選定的OSD設(shè)置為以下down狀態(tài):
- ceph osd down osd.${ID}
現(xiàn)在是時(shí)將OSD移出群集了:
- ceph osd out osd.${ID}
停止OSD并卸載其卷:
- systemctl stop ceph-osd@${ID}
- umount /var/lib/ceph/osd/ceph-${ID}
從CRUSH MAP中刪除OSD:
- ceph osd crush remove osd.${ID}
刪除OSD身份驗(yàn)證密鑰:
- ceph auth del osd.${ID}
最后,刪除OSD:
- ceph osd rm osd.${ID}
注意:對(duì)于Luminous(及更高版本)的Ceph版本,可以將上述步驟簡(jiǎn)化為:
- ceph osd out osd.${ID}
- ceph osd purge osd.${ID}
現(xiàn)在,如果您運(yùn)行ceph osd tree命令,您應(yīng)該看到服務(wù)器的OSD已經(jīng)被移除:
- root@hv-1 ~ # ceph osd tree
- ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
- -1 0.46857 root default
- -3 0.15619 host hv-1
- -5 0.15619 host hv-2
- -7 0.15619 host hv-3
- 2 ssd 0.15619 osd.2 up 1.00000 1.00000
請(qǐng)注意,您的Ceph群集狀態(tài)將變?yōu)镠EALTH_WARN,OSD的數(shù)量以及可用磁盤空間的數(shù)量將減少。
下面,我們將提供完全停止服務(wù)器并將其從Ceph中刪除所需的步驟。我們必須提醒您,在停止服務(wù)器之前,必須移除該服務(wù)器上的所有OSD。
從服務(wù)器中移除所有OSD之后,可以通過運(yùn)行以下命令從CRUSH MAP中刪除服務(wù)器hv-2:
- ceph osd crush rm hv-2
通過在另一臺(tái)服務(wù)器(即 hv-1)上運(yùn)行以下命令,從服務(wù)器hv-2上刪除監(jiān)視器:
- ceph-deploy mon destroy hv-2
之后,您可以停止服務(wù)器并繼續(xù)執(zhí)行其他操作(例如重新部署等)。
案例2:在現(xiàn)有的Ceph集群中分配磁盤空間
現(xiàn)在,讓我們從第二個(gè)案例開始,詳細(xì)講講放置組PG(https://docs.ceph.com/docs/mimic/rados/operations/placement-groups/)。PG(Placement Group)是 Ceph 中非常重要的概念,它可以看成是一致性哈希中的虛擬節(jié)點(diǎn),維護(hù)了一部分?jǐn)?shù)據(jù)并且是數(shù)據(jù)遷移和改變的最小單位。
它在 Ceph 中承擔(dān)著非常重要的角色,在一個(gè) Pool 中存在一定數(shù)量的 PG (可動(dòng)態(tài)增減),這些 PG 會(huì)被分布在多個(gè) OSD ,分布規(guī)則可以通過 CRUSH RULE 來定義。
Monitor 維護(hù)了每個(gè)Pool中的所有 PG 信息,比如當(dāng)副本數(shù)是3時(shí),這個(gè) PG 會(huì)分布在3個(gè) OSD 中,其中有一個(gè) OSD 角色會(huì)是 Primary ,另外兩個(gè) OSD 的角色會(huì)是 Replicated。
Primary PG負(fù)責(zé)該 PG 的對(duì)象寫操作,讀操作可以從 Replicated PG獲得。而 OSD 則只是 PG 的載體,每個(gè) OSD 都會(huì)有一部分 PG 角色是 Primary,另一部分是 Replicated,當(dāng) OSD 發(fā)生故障時(shí)(意外 crash 或者存儲(chǔ)設(shè)備損壞),Monitor 會(huì)將PG的角色為 Replicated的 OSD 提升為 Primary PG,而這個(gè)故障 OSD 上所有的 PG 都會(huì)處于 Degraded 狀態(tài)。
然后等待管理員的下一步操作, 如果原來所有Replicated的 OSD 無法啟動(dòng), OSD 會(huì)被踢出集群,這些 PG 會(huì)被 Monitor 根據(jù) OSD 的情況分配到新的 OSD 上。
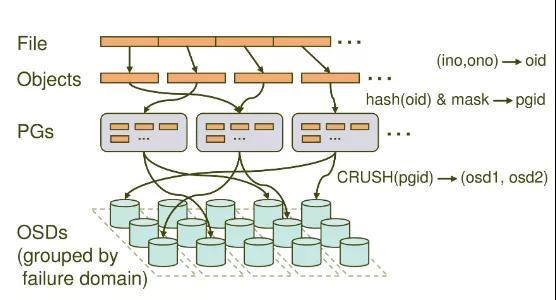
從上面可以看出,Ceph中的放置組主要聚合Ceph對(duì)象并在OSD中執(zhí)行數(shù)據(jù)復(fù)制。Ceph文檔(https://docs.ceph.com/docs/mimic/rados/operations/placement-groups/#choosing-the-number-of-placement-groups)中提供了如何選擇PG數(shù)量的公式。
您還可以在其中找到有關(guān)如何計(jì)算所需PG數(shù)量的案例。
Ceph的存儲(chǔ)池之間的OSD和PG數(shù)量不一致是Ceph運(yùn)行過程中最常見的問題之一。總體而言,正確數(shù)量的PG是Ceph集群健康運(yùn)行的必要條件。下面,我們將看看不正確的PG數(shù)量配置會(huì)發(fā)生什么?
通常,PG的數(shù)量設(shè)置與以下兩個(gè)問題密切相關(guān):
PG數(shù)量太少會(huì)導(dǎo)致均衡大數(shù)據(jù)塊的問題。
另一方面,數(shù)量過多的PG則會(huì)導(dǎo)致性能問題。
實(shí)際上,還有另一個(gè)更危險(xiǎn)的問題:其中一個(gè)OSD中的數(shù)據(jù)溢出。其原因是,Ceph在估算可寫入池中的理論數(shù)據(jù)量時(shí)依賴于OSD中的可用數(shù)據(jù)量。您可以通過命令ceph df 查看每個(gè)存儲(chǔ)池的MAX AVAIL字段,從而獲知每個(gè)存儲(chǔ)池的最大可用量。如果出現(xiàn)一個(gè)OSD容量不足,則在所有OSD之間正確分配數(shù)據(jù)之前,您將無法寫入更多數(shù)據(jù)。
事實(shí)上在配置Ceph集群時(shí)可以解決以上問題。Ceph PGCalc(https://ceph.io/pgcalc/)是推薦使用的工具之一。它可以幫助您配置正確的PG。有一點(diǎn)需要特別注意,修復(fù)PG的常見場(chǎng)景之一是您很可能需要減少PG的數(shù)量。但是,較早的Ceph版本并不支持此功能(從Nautilus版本開始可用)。
好的,讓我們想象一下這種場(chǎng)景:由于某一個(gè)OSD空間不足(如HEALTH_WARN: 1 near full osd),集群處于HEALTH_WARN狀態(tài)。下面介紹了處理這種情況的方法。
首先,您需要在可用的OSD之間重新分配數(shù)據(jù)。當(dāng)從集群中移除OSD時(shí),在案例1中我們做了同樣的事情。唯一的區(qū)別是,現(xiàn)在我們需要稍微減少weight權(quán)重。例如,降至0.95:
- ceph osd reweight osd.${ID} 0.95
這樣,您可以釋放OSD中的磁盤空間并修復(fù)ceph運(yùn)行狀況錯(cuò)誤。但是,正如之前提到的,此問題主要是由于Ceph的初始配置不正確引起的。最佳的做法是重新配置群集,以防止以后再次發(fā)生此類錯(cuò)誤。
在我們的場(chǎng)景中,所有這些都?xì)w結(jié)為以下的兩種原因:
其中一個(gè)池的replication_count過高,
其中一個(gè)池中的PG數(shù)量過多,而另一個(gè)池中的PG數(shù)量不足。
下面,讓我們使用PGCalc計(jì)算器。它非常簡(jiǎn)單,在指定了所有必需的參數(shù)之后,我們得到以下建議:
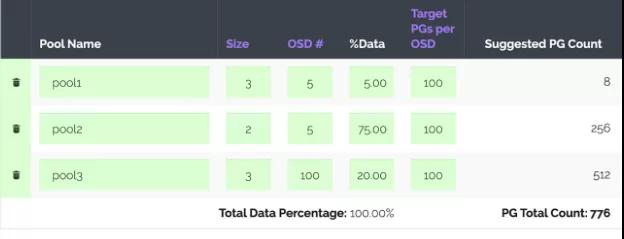
注意:PGCalc能夠生成一組命令,這些命令可以快速創(chuàng)建存儲(chǔ)池,這對(duì)那些從頭開始安裝與配置Ceph集群的人可能會(huì)是一個(gè)非常有用的功能。
最后一欄Suggested PG Count輸出推薦的PG數(shù)量值。在我們的場(chǎng)景中,您還應(yīng)該注意第二列(Size),該列指定每個(gè)池的副本數(shù)(因?yàn)槲覀円呀?jīng)修改了副本數(shù))。
因此,首先,我們需要更改存儲(chǔ)池的副本,我們可以通過減小replication_size參數(shù)來釋放磁盤空間。在命令處理過程中,您將看到可用磁盤空間會(huì)增加:
- ceph osd pool $pool_name set $replication_size
命令運(yùn)行結(jié)束后,我們還必須修改pg_num和pgp_num參數(shù),如下所示:
- ceph osd pool set $pool_name pg_num $pg_number
- ceph osd pool set $pool_name pgp_num $pg_number
注意:我們必須依次更改每個(gè)池中的PG數(shù)量,直到“n-number of pgs degraded”和“Degraded data redundancy”告警消失。
您可以使用ceph health detail和ceph -s命令檢查一切是否順利。
案例3:將VM從LVM遷移到Ceph RBD
Ceph的很多問題都是出現(xiàn)在虛擬化平臺(tái)的使用上。在這樣的存儲(chǔ)使用場(chǎng)景中有充足的空間也是非常必要的。另外一種常見的情況是服務(wù)器使用的是本地存儲(chǔ)的VM。您想擴(kuò)展它的磁盤,但是也沒有足夠的可用空間。
有很多種方法可以解決此類問題。例如,您可以將虛擬機(jī)遷移到另外一臺(tái)物理服務(wù)器(如果有匹配條件的物理服務(wù)器節(jié)點(diǎn)),或在物理服務(wù)器上添加新的物理磁盤。但是,有時(shí)候,這些方法都不可行。在這種情況下,從LVM到Ceph的遷移可能是一個(gè)比較好的解決方案。通過這種方法,不需要將本地存儲(chǔ)從一個(gè)虛擬化節(jié)點(diǎn)遷移到另一個(gè)虛擬化節(jié)點(diǎn),因此我們簡(jiǎn)化了跨節(jié)點(diǎn)遷移。但是,有一個(gè)注意點(diǎn):您必須停止VM,直到遷移完成。
我們的后續(xù)步驟是基于這個(gè)指南(http://blog.easter-eggs.org/index.php/post/2013/09/27/Libvirt-Migrating-from-on-disk-raw-images-to-RBD-storage)。我們已經(jīng)成功測(cè)試了此處提供的解決方案。順便說一句,它還描述了無停機(jī)遷移的方式。但是,由于我們不要求使用此功能,因此我們尚未對(duì)其進(jìn)行驗(yàn)證。
那么實(shí)際步驟是什么?在我們的示例中,我們使用virsh命令。首先,確保目標(biāo)Ceph池已連接到libvirt:
- virsh pool-dumpxml $ceph_pool
存儲(chǔ)池的描述必須包含所有必需的信息和憑據(jù)才能連接到Ceph。
下一步涉及將LVM鏡像轉(zhuǎn)換為Ceph RBD。轉(zhuǎn)換過程的持續(xù)時(shí)間主要取決于鏡像的大小:
- qemu-img convert -p -O rbd /dev/main/$vm_image_name
- rbd:$ceph_pool/$vm_image_name
轉(zhuǎn)換完成后,將仍然保留LVM鏡像。如果將VM遷移到RBD失敗,這將派上用場(chǎng),而您必須回滾所做的更改。為了能夠快速回滾更改,讓我們備份VM的配置文件:
- virsh dumpxml $vm_name > $vm_name.xml
- cp $vm_name.xml $vm_name_backup.xml
編輯原始的vm_name.xml文件。查找磁盤的描述(以<disk type='file' device='disk'>開頭和以</disk>結(jié)尾),并按如下所示進(jìn)行修改:
- <disk type='network' device='disk'>
- <driver name='qemu'/>
- <auth username='libvirt'>
- <secret type='ceph' uuid='sec-ret-uu-id'/>
- </auth>
- <source protocol='rbd' name='$ceph_pool/$vm_image_name>
- <host name='10.0.0.1' port='6789'/>
- <host name='10.0.0.2' port='6789'/>
- </source>
- <target dev='vda' bus='virtio'/>
- <alias name='virtio-disk0'/>
- <address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/>
- </disk>
仔細(xì)查看細(xì)節(jié):
- source協(xié)議字段中包含Ceph的RBD存儲(chǔ)池的路徑。
- secret字段包含ceph密碼的類型以及UUID。您可以使用以下virsh secret-list命令找出UUID 。
- host字段包含Ceph監(jiān)視器的地址。
編輯完配置文件并將LVM成功轉(zhuǎn)換為RBD后,您可以應(yīng)用修改后的xml文件并啟動(dòng)虛擬機(jī):
- virsh define $vm_name.xml
- virsh start $vm_name
現(xiàn)在該檢查虛擬機(jī)是否正常運(yùn)行了。為此,您可以通過SSH或使用virsh直接連接到物理節(jié)點(diǎn)。
如果VM正常運(yùn)行,并且沒有任何其他問題的提示,則可以刪除LVM鏡像,因?yàn)椴辉傩枰?/p>
- lvremove main/$vm_image_name
結(jié)論:在生產(chǎn)環(huán)境中,我們遇到了以上這些問題。我們希望我們的解決方式能夠幫助到您。當(dāng)然,在Ceph的運(yùn)維過程中所遇到的問題不僅僅是這些,還可能會(huì)更多,但只要遵循標(biāo)準(zhǔn)化操作,問題最終都能被圓滿解決。