Ceph萬字總結|如何改善存儲性能以及提升存儲穩定性
本文轉載自微信公眾號「新鈦云服」,作者祝祥 。轉載本文請聯系新鈦云服公眾號。
「Ceph – 簡介」
Ceph是一個即讓人印象深刻又讓人畏懼的開源存儲產品。通過本文,用戶能確定Ceph是否滿足自身的應用需求。在本文中,我們將深入研究Ceph的起源,研究其功能和基礎技術,并討論一些通用的部署方案和優化與性能增強方案。同時本文也提供了一些故障場景以及對應的解決思路。
背景
Ceph是一個開源的分布式存儲解決方案,具有極大的靈活性和適應性。Ceph項目最早起源于Sage就讀博士期間的論文(最早的成果于2004年發表),并隨后貢獻給開源社區。在經過了數年的發展之后,目前已得到眾多云計算廠商的支持并被廣泛應用。RedHat及OpenStack都可與Ceph整合以支持虛擬機鏡像的后端存儲。
Ceph在2014年被RedHat收購后,一直由RedHat負責維護。Ceph的命名和UCSC(Ceph 的誕生地)的吉祥物有關,這個吉祥物是 “Sammy”,一個香蕉色的蛞蝓,就是頭足類中無殼的軟體動物。這些有多觸角的頭足類動物,是對一個分布式文件系統高度并行的形象比喻。自從2012年7月3日發布第一個版本的Argonaut以來,隨著新技術的整合,Ceph經歷了幾次開發迭代。借助適用于Openstack和Proxmox的虛擬化平臺,Ceph可支持直接將iSCSI存儲呈現給虛擬化平臺。同時Ceph也擁有功能強大的API。在世界上的各大公司都能發現Ceph的身影——提供塊存儲,文件存儲,對象存儲。
由于Ceph是目前唯一提供以下所有功能的存儲解決方案,因此Ceph越來越受歡迎,并吸引了許多大型企業的極大興趣:
- 「軟件定義」:軟件定義存儲 (SDS) 是一種能將存儲軟件與硬件分隔開的存儲架構。不同于傳統的網絡附加存儲 (NAS) 或存儲區域網絡 (SAN) 系統,SDS 一般都在行業標準系統或 x86 系統上運行,從而消除了軟件對于專有硬件的依賴性。借助Ceph,還可以為諸如糾錯碼,副本,精簡配置,快照和備份之類的功能提供策略管理。
- 「企業級」 :Ceph旨在滿足大型組織在可用性,兼容性,可靠性,可伸縮性,性能和安全性等方面的需求。它同時支持按比例伸縮,從而使其具有很高的靈活性,并且其可擴展性潛力幾乎無限。
- 「統一存儲」:Ceph提供了塊+對象+文件存儲,從而提供了更大的靈活性(大多數其他存儲產品都是僅塊,僅文件,僅對象或文件+塊;ceph提供的三種混合存儲是非常罕見)。
- 「開源」:開源實現技術的敏捷性,通常提供多種解決問題的方法。開源通常也更具成本效益,并且可以更輕松地使組織開始規模更小,規模更大。開源解決方案背后的許多意識形態孕育了一個相互協作且參與度高的專業社區,這些社區反應靈敏且相互支持。更不用說開源是未來的方向。Web,移動和云解決方案越來越多地建立在開源基礎架構上。
「為什么選擇Ceph?」
「Ceph 分布式核心組件」
集群文件系統最初始于1990年代末和2000年代初。Lustre是最早利用可伸縮文件系統實現產品化的產品之一。多年來,出現了其他一些Lustre衍生產品,包括GlusterFS,GPFS,XtreemFS和OrangeFS等。這些文件系統都集中于為文件系統實現符合POSIX的掛載,并且缺乏通用的集成API。
Ceph的架構并不需要考慮到需要與POSIX兼容的文件系統——這完全得益于云的時代。利用RADOS,Ceph可以擴展不受元數據約束限制的塊設備。這極大地提高了存儲性能,但是卻使那些尋求基于Ceph的大型文件系統掛載方法的人們望而卻步。直到Ceph Jewel(10.2.0)版本發布為止,CephFS已經是穩定且可靠的文件系統——允許部署POSIX掛載的文件系統。
Ceph支持塊,對象和文件存儲,并且具有橫向擴展能力,這意味著多個Ceph存儲節點(服務器)共同提供了一個可快速處理上PB數據(1PB = 1,000 TB = 1,000,000 GB)的存儲系統。利用作為基礎的硬件組件,它還可以同時提高性能和容量。
Ceph具有許多基本的企業存儲功能,包括副本,糾錯碼,快照,自動精簡配置,分層(在閃存和普通硬盤之間緩存數據的能力——即緩存)以及自我修復功能。為了做到這一點,Ceph利用了下面將要探討的幾個組件。
從Ceph Nautilus(v14.2.0)開始,現在有五個主要的守護程序或服務,它們集成在一起以提供Ceph服務的正常運行。這些是:
- 「ceph-mon」:Monitor確實提供了其名稱所暗示的功能——監視群集的運行狀況。該監視器還告訴OSD在replication期間將數據放置在何處,并保留主CRUSH Map。
- 「ceph-osd」:OSD是Ceph的基礎數據存儲單元,它利用XFS文件系統和物理磁盤來存儲從客戶端提供給它的塊數據。
- 「ceph-mds」:MDS守護程序提供了將Ceph塊數據轉換為存儲文件的POSIX兼容掛載點的功能,就像您使用傳統文件系統一樣。
- 「ceph-mgr」:MGR守護程序顯示有關群集狀態的監視和管理信息。
- 「ceph-rgw」:RGW守護程序是一個HTTP API守護程序,對象存儲網關實際上是調用librados的API來實現數據的存儲和讀取。而該網關同時提供了兼容AWS S3和OpenStack Swift的對象存儲訪問接口(API)。
從術語的角度來看,Ceph需要了解一些重要的知識。
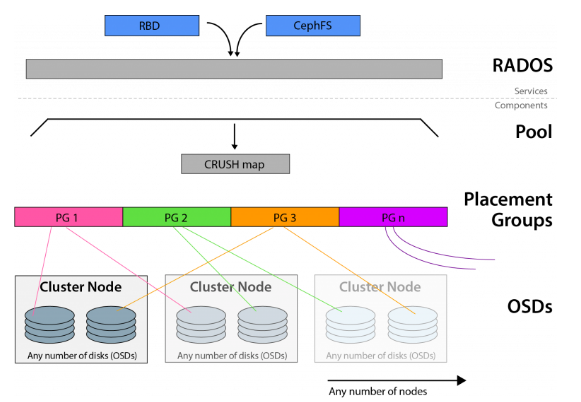
Ceph基于CRUSH算法構建, 并支持多種訪問方法(文件,塊,對象)。CRUSH算法確定對象在OSD上的位置,并且可以將這些相同的塊拉出以進行訪問請求。
Ceph利用了可靠,自治,分布式的對象存儲(或RADOS),該對象存儲由自我修復,自我管理的存儲節點組成。前面討論的OSD守護程序是RADOS群集的一部分。
放置組(PG)的全稱是placement group,是用于放置object的一個載體,所以群集中PG的數量決定了它的大小。pg的創建是在創建ceph存儲池的時候指定的,同時跟指定的副本數也有關系,比如是3副本的則會有3個相同的pg存在于3個不同的osd上,pg其實在osd的存在形式就是一個目錄。PG可以由管理員設置,新版本中也可以根據集群使用情況自動縮放。
RBD即RADOS Block Device的簡稱,RBD塊存儲是最穩定且最常用的存儲類型。RBD塊設備類似磁盤可以被掛載。RBD塊設備具有快照、多副本、克隆和一致性等特性,數據以條帶化的方式存儲在Ceph集群的多個OSD中。可以在Ceph中用于創建用于虛擬化的鏡像塊設備,例如KVM和Xen。通過利用與RADOS兼容的API librados,VM的訪問不是通過iSCSI或NFS,而是通過存儲API來實現的。
使用場景
正如我們已經描述的那樣,Ceph是一個非常靈活和一致的存儲解決方案。對Ceph存儲對象的訪問可以通過多種方式來完成,因此Ceph具有其他類似產品所缺乏的大量生產用例。
可以將Ceph部署為S3/Swift對象存儲的替代品。通過它的RADOS網關,可以使用http GET請求以及大量可用的Amazon S3 API工具箱訪問存儲在Ceph中的對象。
也可以通過librados API或iSCSI/NFS在包括VMWare和其他專有虛擬化平臺在內的虛擬化環境中直接使用Ceph。
可以部署CephFS為需要訪問大型文件系統的操作系統提供POSIX兼容的掛載點。
根據以上的這些場景,我們可以利用單個存儲平臺來滿足各種計算和存儲需求。
「潛在的部署方案」
常用的Ceph部署工具主要有:ceph-deploy,ceph-ansible,基于kubernetns的Rook以及新版本基于容器的kubeadm等。當然工具不僅僅是這些。每一種部署方案都有大量的生產實踐。以下簡單介紹以下這幾種常用的部署方式:
「Ceph-deply」:該工具可用于簡單、快速地部署 Ceph 集群,而無需涉及繁雜的手動配置。它在管理節點上通過 ssh 獲取其它 Ceph 節點的訪問權、通過 sudo 獲取其上的管理權限、通過底層 Python 腳本自動化各節點上的 Ceph 安裝進程。它簡單到可以運行在工作站上,不需要服務器、數據庫或任何其它的自動化工具。使用ceph-deploy安裝和拆除集群非常簡單。然而它不是通用部署工具,是專為想快速安裝、運行 Ceph 的人們設計的專用工具,這樣的集群只包含必要的的初始配置選項,就沒必要安裝像 Chef 、 Puppet 或 Juju 這樣的部署工具。
「Ceph-ansible」:用于部署Ceph分布式系統的ansible playbook,ceph-ansible是安裝和管理完整ceph集群的最靈活的方法,當前大量的生產環境都會使用該安裝方式。
「Rook」:Rook 是一個編排器,能夠支持包括 Ceph 在內的多種存儲方案。Rook 簡化了 Ceph 在 Kubernetes 集群中的部署過程。Rook 是一個可以提供 Ceph 集群管理能力的 Operator。Rook 使用 CRD 一個控制器來對 Ceph 之類的資源進行部署和管理。
「Cephadm」:較新的集群自動化部署工具,支持通過圖形界面或者命令行界面添加節點,目前不建議用于生產環境。cephadm的目標是提供一個功能齊全、健壯且維護良好的安裝和管理層,可供不在Kubernetes中運行Ceph的任何環境使用。Cephadm通過SSH從manager守護進程連接到主機來部署和管理Ceph集群,以添加、刪除或更新Ceph守護進程容器。它不依賴于外部配置或編排工具,如Ansible、Rook或Salt。
「結論」
Ceph的性能與功能不斷得到提升,存儲特性也不斷豐富,甚至可以與傳統專業存儲媲美,完備的存儲服務和低廉的投資成本,使得越來越多的企業和單位選用Ceph提供存儲服務。大量的生產最佳實踐也使得Ceph成為標準SDS的最優解決方案之一。
Cephadm管理Ceph集群的整個生命周期,是官方以后力推的部署以及管理Ceph的解決方案。它首先在單個節點(一個監視器和一個管理器)上引導一個很小的Ceph集群,然后使用編排接口擴展集群以包括所有主機并提供所有Ceph守護進程和服務。這可以通過Ceph命令行界面(CLI)或儀表板(GUI)來執行。
Cephadm是Octopus發行版中的一個新功能,在生產中的使用有限。社區希望用戶嘗試cephadm,特別是對于新的集群,但請注意,有些功能仍然很粗糙。當前社區持續在改進以及相應BUG修復中。
5種最常見的CEPH失敗方案
Ceph是一種廣泛使用的存儲解決方案,可在整個分布式集群中實現對象級,塊級和文件級存儲。Ceph是創建不圍繞單個故障點進行擴展的高效存儲系統的理想選擇。但是,如果管理不當,Ceph可能很容易成為失敗場景的雷區,這可能是一件難以完全避免的事情。本處,我們將探討最常見的五種Ceph失敗方案。
「Monitor數目不正確」
在最新版本的Ceph中,至少需要三臺運行Ceph Mon守護程序的服務器。這些可以是物理服務器(理想情況下)或者也可以是虛擬機。但是,如果您超出了Mon服務器的最小數量,則在Ceph構建中始終保持運行奇數個守護程序非常重要。這個奇數很重要,因為它允許系統正確地建立一個主機來控制CRUSH Map。在確定主服務器時,每臺服務器都會“投票”認為最適合維護crush map的服務器。維護奇數個Ceph守護程序可確保永遠不會出現投票平局的現象,并且始終會建立一個主服務器。如果沒有維護奇數個守護程序,則可能會導致不穩定,并最終導致Ceph崩潰。
「OSD數目不正確」
根據在Ceph集群中所設置的副本數,您將需要足夠數量的硬盤(OSD——對象存儲設備)。當您計劃購買或升級當前Ceph中的OSD前,最重要的是要根據當前狀況進行數據量預測,以匹配未來生產的數據量。通常,最好至少提前6到12個月進行估算,并將此存儲量乘以所需的對象冗余量(即32TB數據* 3(副本數)= 96TB所需的存儲空間)。通過適當的預測,您可以避免OSD過載,并保持CEPH環境正常運行。
「RADOS網關冗余不足」
RADOS (「Reliable, Autonomic Distributed Object Store」) 是Ceph的核心之一,作為Ceph分布式文件系統的一個子項目,特別為Ceph的需求設計,能夠在動態變化和異質結構的存儲設備集群之上提供一種穩定、可擴展、高性能的單一邏輯對象(Object)存儲接口和能夠實現節點的自適應和自管理的存儲系統。RADOS構成了Ceph集群的核心,并且與Ceph CRUSH Map結合使用時,可以使您在服務器的集群中保持數據一致且可安全的進行數據同步與復制。可以以多種不同方式訪問Ceph數據。其中之一是通過稱為RADOS網關的HTTP API前端進行的。RADOS網關公開了一個存儲API,供外部人員調用。
如果通過RADOS網關訪問您的Ceph集群,那么促進API訪問的前端服務器必須冗余且能夠負載均衡,這一點非常重要。在理想的配置中,多個RADOS服務器將可用于接受請求,并且所有請求都應由一個冗余的負載均衡器進行管理。如果未進行正確配置,則非冗余RADOS網關服務器的故障將導致您完全失去對CEPH群集的API訪問權限。您可以使用混合的解決方案,該混合解決方案會利用本地RADOS網關,當發生故障時則會回退到基于云的冗余網關上。這可以最大程度地減少額外的不必要轉換,同時保持對存儲解決方案的冗余和可靠訪問。
「硬件配置不足」
為CEPH集群維護硬件時,最重要的是要確保硬件配置滿足實際需求,具體需要考慮的如下:
- 「電源」:確保主機的電源模塊至少是雙路冗余。還要確保每臺CEPH服務器都有一個備用電源,該備用電源的功率足以完全滿足服務器的需求。沒有適當的冗余,您將面臨不可挽回的數據丟失的風險。
- 「CPU」:最佳實踐要求在所有CEPH服務器上使用相同型號相同配置的CPU。這有助于在整個ceph集群中保持一致性以及穩定性。
- 「內存」:與CPU相似,您使用的內存應在CEPH服務器之間平均分配。理想情況下,存儲服務器的品牌和規格應該相同。此外,在發生硬件故障時,還應具有大量可用的冗余內存(備件)。
- 「硬盤」:建議將SAS磁盤用于OSD。如果有可能的話,使用故障率低于SAS盤的NVMe磁盤則會更為理想。
- 「其他」:如果有可能的話,可以提供一些冷備機器。當存儲節點存現故障的時候,極端情況下可以直接進行備機更換(保留物理磁盤)。
「CEPH專業知識」
通常,CEPH失敗的原因是由于缺乏CEPH相關的專業知識。例如,所有CEPH群集中OSD節點都將利用硬盤直通模式來確保性能和可靠性。但是,如果改用RAID的話,則不僅是不推薦的,而且還會因為磁盤陣列故障而導致出現單點故障,最終可能引起大量數據丟失。這種錯誤很簡單,但從長遠來看,這樣的錯誤代價高昂,并且可能需要更高級的ceph專家去解決相應的問題。
Ceph常規排障
如果Ceph集群崩潰該怎么辦
由于Ceph在軟件層就內置了所有可用的冗余和故障保護功能,因此簡單的故障不太可能造成災難性的后果,并且一般的故障相對都是比較容易恢復的。但問題是,當遇到一系列意外事件導致集群停止響應存儲請求或使所有VM虛擬機脫機時,那又該怎么辦?
「保持冷靜」
Ceph非常強大,其Crush算法可確保數據的完整性和可用性。記住這一關鍵事實將有助于您確定中斷的原因。
最常見的災難性故障場景之一是群集丟失的OSD超過維護所需的冗余級別所需的OSD。在這種情況下,快速識別并更換有問題的OSD將使您的群集恢復工作狀態。同時也讓我們確定其他潛在故障觸發因素。
「記錄和狀態」
Ceph在mon(monitor)節點和osd(object storage daemon)節點上提供了多個日志和狀態查看命令,您應該首先利用Ceph相關命令行來查看群集的運行狀況。
要評估Ceph集群的當前狀態,請輸入:
- # ceph status
或者使用:
- # ceph -s
兩次命令的結果都應輸出類似于以下內容:
- cluster b370a29d-9287-4ca3-ab57-3d824f65e339
- health HEALTH_OK
- monmap e1: 1 mons at {ceph1=10.0.0.8:6789/0}, election epoch 2, quorum 0 ceph1
- osdmap e63: 2 osds: 2 up, 2 in
- pgmap v41332: 952 pgs, 20 pools, 17130 MB data, 2199 objects
- 115 GB used, 167 GB / 297 GB avail
- 1 active+clean+scrubbing+deep
- 951 active+clean
如果您看到健康狀況為“HEALTH_OK”,那就說明集群狀態健康。
在某些情況下,尤其是與OSD相關的情況下,將返回HEALTH_WARN或HEALTH_ERR。這可能是由于一些不影響群集整體性能的因素所致,例如OSD重新均衡或存儲池的PG的深度清理。這些都可以安全地忽略。
在某些情況下,Ceph的命令行界面可能根本不響應這兩個命令。如果您的Ceph的身份驗證有問題,或者運行Monitor服務的節點硬件有問題,通常會發生這種情況。在第二種情況下,則需要診斷Monitor節點服務器本身的硬件問題。
「mon(Monitor)調試」
當使用多個Ceph Mon運行時,Ceph則需要仲裁(Quorum)。仲裁是確保一致性的可靠方法,因為群集需要最少的“投票”數才能繼續進行replication。
可以使用以下幾個命令來確定Ceph Mon的狀態。
- # ceph mon stat
上述命令將輸出集群中所有mon的當前狀態,例如:
- e3: 3 mons at {pve1=10.103.6.109:6789/0,pve2=10.103.6.110:6789/0,pve3=10.103.6.111:6789/0}, election epoch 30, leader 0 pve1, quorum 0,1,2 pve1,pve2,pve3
上面表示有三個Ceph Mon已經啟動并成功運行。其中有一個仲裁節點,狀態顯示集群運行正常。您會注意到ceph mon stat的輸出中有幾條重要的信息,包括選舉之間的時間間隔(以秒為單位)。選舉在這些時間間隔內發生,以確定哪個監視器應該是集群的“leader”。
與使用仲裁作為確保一致性的方法的非技術機構一樣,每個節點都有一票表決權。在Ceph中,最佳實踐堅持我們利用大于或等于3的奇數個Ceph Mon節點。這確保了我們的群集在失去一個或者兩個仲裁節點的小概率事件中維持仲裁能力和一定程度的冗余。
如果我們真的失去了法定人數(quorum),或者沒有贏得法定人數的投票。那么,由于監視器在其Ceph運行中所起的重要作用,則會導致Ceph群集將完全無法響應。從跟蹤數據存放位置到維護OSD的實時Map。Ceph Mon節點還提供用于返回“Ceph health”和“Ceph -s”輸出功能。如果沒有一個正常工作的Ceph Mon仲裁,則所有命令都不會有任何返回值。
檢查監視器狀態的其他有用命令包括:
- #dumping the mon map
- # ceph mon dump
- dumped monmap epoch 3
- epoch 3
- fsid 4a1dc77a-37f8-4b5b-9476-853f7cace716
- last_changed 2020-8-18 10:50:36.846268
- created 2020-8-18 10:50:25.571368
- 0: 10.103.6.109:6789/0 mon.pve1
- 1: 10.103.6.110:6789/0 mon.pve2
- 2: 10.103.6.111:6789/0 mon.pve3
- # ceph quorum_status --format json-pretty #looking at quorum status
- {
- "election_epoch": 30,
- "quorum": [
- 0,
- 1,
- 2
- ],
- "quorum_names": [
- "pve1",
- "pve2",
- "pve3"
- ],
- "quorum_leader_name": "pve1",
- "monmap": {
- "epoch": 3,
- "fsid": "4a1dc77a-37f8-4b5b-9476-853f7cace716",
- "modified": "2020-8-18 10:50:36.846268",
- "created": "2020-8-18 10:50:25.571368",
- "features": {
- "persistent": [
- "kraken",
- "luminous"
- ],
- "optional": []
- },
- "mons": [
- {
- "rank": 0,
- "name": "pve1",
- "addr": "10.103.6.109:6789/0",
- "public_addr": "10.103.6.109:6789/0"
- },
- {
- "rank": 1,
- "name": "pve2",
- "addr": "10.103.6.110:6789/0",
- "public_addr": "10.103.6.110:6789/0"
- },
- {
- "rank": 2,
- "name": "pve3",
- "addr": "10.103.6.111:6789/0",
- "public_addr": "10.103.6.111:6789/0"
- }
- ]
- }
- }
「守護進程套接字(「Daemon Socket」)」
Ceph管理套接字(daemon socket)允許您直接連接到所有正在運行的Ceph守護進程。從OSD到Mon和MGR,Ceph守護程序管理套接字可以提供診斷功能,這些功能在Ceph Mon發生故障并且Ceph客戶端停止響應時可能會變得不可用。
以下命令可直接連接到Ceph守護程序,根據需求進行狀態查看。
- # ceph daemon {daemon-name} ##OR
- # ceph daemon {path-to-socket-file} ##For Example
- # ceph daemon osd.0 help
- {
- "calc_objectstore_db_histogram": "Generate key value histogram of kvdb(rocksdb) which used by bluestore",
- "compact": "Commpact object store's omap. WARNING: Compaction probably slows your requests",
- "config diff": "dump diff of current config and default config",
- "config diff get": "dump diff get : dump diff of current and default config setting ",
- "config get": "config get : get the config value",
- "config help": "get config setting schema and descriptions",
- "config set": "config set [ ...]: set a config variable",
- "config show": "dump current config settings",
- "dump_blacklist": "dump blacklisted clients and times",
- "dump_blocked_ops": "show the blocked ops currently in flight",
- "dump_historic_ops": "show recent ops",
- "dump_historic_ops_by_duration": "show slowest recent ops, sorted by duration",
- "dump_historic_slow_ops": "show slowest recent ops",
- "dump_mempools": "get mempool stats",
- "dump_objectstore_kv_stats": "print statistics of kvdb which used by bluestore",
- "dump_op_pq_state": "dump op priority queue state",
- "dump_ops_in_flight": "show the ops currently in flight",
- "dump_pgstate_history": "show recent state history",
- "dump_reservations": "show recovery reservations",
- "dump_scrubs": "print scheduled scrubs",
- "dump_watchers": "show clients which have active watches, and on which objects",
- "flush_journal": "flush the journal to permanent store",
- "flush_store_cache": "Flush bluestore internal cache",
- "get_command_descriptions": "list available commands",
- "get_heap_property": "get malloc extension heap property",
- "get_latest_osdmap": "force osd to update the latest map from the mon",
- "getomap": "output entire object map",
- "git_version": "get git sha1",
- "heap": "show heap usage info (available only if compiled with tcmalloc)",
- "help": "list available commands",
- "injectdataerr": "inject data error to an object",
- "injectfull": "Inject a full disk (optional count times)",
- "injectmdataerr": "inject metadata error to an object",
- "log dump": "dump recent log entries to log file",
- "log flush": "flush log entries to log file",
- "log reopen": "reopen log file",
- "objecter_requests": "show in-progress osd requests",
- "ops": "show the ops currently in flight",
- "perf dump": "dump perfcounters value",
- "perf histogram dump": "dump perf histogram values",
- "perf histogram schema": "dump perf histogram schema",
- "perf reset": "perf reset : perf reset all or one perfcounter name",
- "perf schema": "dump perfcounters schema",
- "rmomapkey": "remove omap key",
- "set_heap_property": "update malloc extension heap property",
- "set_recovery_delay": "Delay osd recovery by specified seconds",
- "setomapheader": "set omap header",
- "setomapval": "set omap key",
- "status": "high-level status of OSD",
- "trigger_scrub": "Trigger a scheduled scrub ",
- "truncobj": "truncate object to length",
- "version": "get ceph version"
例如,當多個Ceph monitor守護進程同時失敗時,Ceph守護程序可用于更新mon map。這將使您可以將新的mon map更新并導入到無法運行的Ceph Mon節點中,這也是Ceph中非常常見的一個故障解決方案。
「規避風險」
用戶應該盡量熟悉這兩種從Ceph群集崩潰或意外中斷中恢復的重要方法。這些工具功能強大,學習如何利用它們則能盡量減少數據丟失的風險,同時也能夠最快,最全的恢復Ceph集群。
當然,每一個故障場景都不同,本處僅僅是提供了一些常規的集群崩潰故障以及對應的解決方案。但更復雜的場景需要用戶根據自身所遇到的場景進行更加具體的分析以及處理。
Ceph — OSD Flapping(抖動)調試和恢復
下面我們將特別討論如果當您發現Ceph OSD因意外而進行peering,出現scrubbing或集群連接斷斷續續的情況時候該如何進行排查以及解決問題。其實,上述的這些行為也可以稱之為抖動(flapping),而且這因多種原因而引起的故障會損害群集的性能和持久性以及穩定性。
「故障」
當一個OSD或多個OSD開始抖動(flapping)時,您可能首先會注意到讀寫速度明顯下降。這是出于多種原因。當OSD在不停的抖動(flapping)期間停止時,您實際上已經失去了正在抖動(flapping)的所有OSD的總吞吐量,也就是說這些抖動(flapping) OSD不僅不能提供正常的存儲能力,還影響了整個集群的性能。尤其是在一個擁有數萬IOPS讀寫的大型集群上,這可能是災難性的。
OSD服務正常后,群集要做的第一件事就是嘗試進行恢復。恢復并不是一個非常簡單的過程,其中需要對在多個不同主機上的多個OSD中副本的塊進行校驗和驗證,以確保完整性。如果校驗和不匹配,則需要重新復制該塊。
此校驗和驗證和文件重新傳輸過程會引起Ceph集群的大量硬件資源消耗。最直接的體現是:服務器設備耗電量會大幅度增加,群集網絡上的網絡流量也會急劇增加。如果當前Ceph集群已經處于一個高負載的環境,這種額外的不必要的負載可能會導致性能進一步下降,甚至導致集群停止響應,極端情況會引起Ceph集群的一連串的崩潰。
那么,如何查看Ceph集群的癥狀,以查看性能問題是否與OSD的抖動(flapping)相關?第一種也是最簡單的方法是簡單地檢查群集的運行狀況。這可以通過使用Luminous及更高版本中提供的Ceph儀表板來完成。可通過“http://IPCEPHNODE:7000” (7000為訪問端口,在初始化的時候可以根據需求進行自定義)。您還可以在任何啟用了ceph-admin的主機上通過命令行查看Ceph群集的狀態。可以使用“ ceph -s”命令,該命令將輸出集群的當前運行狀況。如果正在進行修復或OSD當前被標記為down,該命令將向您發出輸出警報。
「原因和解決方法」
通常,導致OSD抖動(flapping)的原因與導致OSD失敗的原因相似。不良的硬件狀況,過多的發熱,網絡問題以及整個系統的負載都可能導致OSD抖動(flapping)。
從硬件的角度來看,底層的存儲磁盤可能出現物理故障。所有硬盤都可通過SMART屬性監視其當前狀態。這些值提供有關硬盤各種參數的信息,并可提供有關磁盤剩余壽命或任何可能的錯誤的信息。此外,可以執行各種SMART測試,以確定磁盤上的任何硬件問題。因此,可以利用Smartctl來確定當前環境中的SAS或者SATA磁盤是否處于不健康狀態——這可能導致OSD故障并不停重啟。通過登錄到可能受影響的主機并輸入“ smartctl -a /dev/sdX”(其中X是設備ID)來定位物理設備,從而檢查硬盤驅動器的SMART狀態。同時還可以通過grep正則匹配去過濾所需要的參數。通過該方式,不僅將輸出硬盤當前的狀態,同時會顯示即將發生故障。如果可以的話,請及時更換有故障的硬盤!
OSD抖動(flapping)的另一個原因可能很簡單,比如您的Ceph存儲網絡接口上的MTU不匹配。MTU或Maximum Transmission Unit,用來通知對方所能接受數據服務單元的最大尺寸,說明發送方能夠接受的有效載荷大小,也就是允許接口發送的最大數據包大小——有效地將數據包拆分為較小的塊,以適合系統指定的MTU。因為Ceph是一種處理大型數據塊的存儲技術,所以MTU越大,代表系統以最少的工作量就可以獲得更多的吞吐量。
如果整個集群中的任何地方的MTU不匹配,即一臺服務器的MTU設置為9000,另一臺服務器的MTU設置為1500,你最終會遇到這樣的情況:數據傳輸卡頓,并且Ceph集群的復制也會基本停止。這也可能是Ceph OSD抖動(flapping)的另外一個原因(健康檢查與低MTU的競爭帶寬)。
要檢查接口的MTU,請在命令行上鍵入“ ifconfig”或“ ip addr”。將MTU與接口匹配,并比較群集中所有主機接口的MTU配置是否一致。
「結論」
Ceph OSD的抖動是存儲使用過程中最常見的一種故障,該故障不一定會致命,但往往會對集群性能產生嚴重的影響。及時發現OSD抖動,合理解決問題,盡量避免對集群產生過多的影響。
「Ceph性能優化與增強」
上文介紹了Ceph的入門背景,討論了Ceph在云計算和對象存儲中的功能和主要組件,并簡要概述了其部署工具以及常規的故障現象以及對應的解決思路。下文,我們將研究Ceph的強大的功能,并探索最優的方法來提高存儲性能。
Ceph是一個非常復雜的存儲系統,它具有幾種我們可以用來提高性能的方式。幸運的是,Ceph的開箱即用非常好,許多性能設置幾乎利用了自動調整和縮放功能。在探索一些性能增強時,了解您的工作負載很重要,這樣您就可以選擇最適合您的選項。
「配置說明」
Ceph有幾種部署方案,其中最常見的是針對虛擬化環境,符合POSIX的文件系統和塊存儲的組合。這些場景中的每一個都有明顯不同的配置要求。例如,在CephFS提出的POSIX文件系統中,將文件系統元數據存儲在高速SSD或NVMe驅動器上是非常重要。對于虛擬化環境中使用RBD場景,Ceph的caching tier功能可以使用SSD或NVMe為后端普通廉價的存儲提供高速緩存的功能。
「通用硬件」
「Hyper-Threading(HT)」基本做云平臺的,VT和HT打開都是必須的,超線程技術(HT)就是利用特殊的硬件指令,把兩個邏輯內核模擬成兩個物理芯片,讓單個處理器都能使用線程級并行計算,進而兼容多線程操作系統和軟件,減少了CPU的閑置時間,提高的CPU的運行效率。
「關閉節能」關閉節能后,對性能還是有所提升的,所以堅決調整成性能型(Performance)。當然也可以在操作系統級別進行調整,詳細的調整過程請參考鏈接,但是不知道是不是由于BIOS已經調整的緣故,所以在CentOS 6.6上并沒有發現相關的設置。
- for CPUFREQ in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do [ -f <span class="katex math inline">CPUFREQ ] || continue; echo -n performance></span>CPUFREQ; done
「NUMA」簡單來說,NUMA思路就是將內存和CPU分割為多個區域,每個區域叫做NODE,然后將NODE高速互聯。node內cpu與內存訪問速度快于訪問其他node的內存,NUMA可能會在某些情況下影響ceph-osd。解決的方案,一種是通過BIOS關閉NUMA,另外一種就是通過cgroup將ceph-osd進程與某一個CPU Core以及同一NODE下的內存進行綁定。但是第二種看起來更麻煩,所以一般部署的時候可以在系統層面關閉NUMA。CentOS系統下,通過修改/etc/grub.conf文件,添加numa=off來關閉NUMA。
- kernel /vmlinuz-2.6.32-504.12.2.el6.x86_64 ro root=UUID=870d47f8-0357-4a32-909f-74173a9f0633 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM biosdevname=0 numa=off
「RAM」
為Ceph選擇的主機及其基礎服務應具有足夠的CPU線程,內存和網絡設備,以處理群集的預期吞吐量。Ceph建議每1TB OSD原始磁盤空間使用1GB RAM。如果主機具有96TB的原始磁盤空間,則應計劃至少需要96GB的RAM。我們建議每個OSD至少使用1個CPU內核。OSD可以定期消耗整個CPU來執行重新平衡操作。
「避免使用超融合!」
不建議以超融合方式在Ceph節點上運行其他應用程序,因為在由于磁盤故障而導致的群集重建過程中,每個OSD的OSD RAM使用量可能遠遠超過建議的1GB。如果其他應用程序爭奪RAM,則重建性能以及隨后的Ceph群集本身的讀寫性能都會受到嚴重影響。
「不要使用硬件RAID控制器!」
讓Ceph為您完成數據處理。使用硬件RAID控制器可能導致Ceph在RAID重建期間未意識到的不一致和性能下降。SAS HBA的價格為$100-$200,高性能的僅占很小的溢價。這將是確保Ceph集群性能的最佳配置。
「基礎存儲OSD」
當構建一個新的Ceph群集時,其中一個主要的工作是對象存儲守護程序(OSD)的底層存儲的選擇。容量需求可能決定了該解決方案所需要的底層存儲。預算可能允許購買大容量的SSD驅動器或NVMe。無論選擇了什么樣的底層存儲,累計底層存儲的性能都將直接影響Ceph集群的性能(OSD性能越佳,則Ceph集群性能也越佳)。
在需要使多個10G萬兆網絡接口的環境中,或者對于讀寫時延極低的應用程序,選擇SSD或NVMe磁盤可能更有意義。這些將為OSD提供企業級磁盤的完整吞吐量,包括在整個群集中的組合IOPS。
SATA和SAS類型磁盤確實提供了比SSD和NVMe更大的標準存儲容量,但是IOPS與吞吐量有限(受限于OSD所使用的存儲介質)。因此,群集中將需要更大的磁盤陣列,以提供與更快的磁盤相似的甚至遠超的性能。
「緩存層」
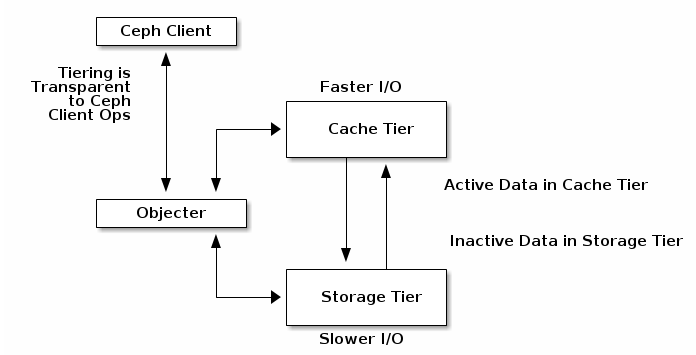
Ceph Luminous中的新增功能,對于出于預算原因或使用大容量磁盤的項目,可以充分提前預估存儲容量的用戶而言,緩存層(Cache Tier)是一項極佳的性能增強解決方案。構建緩存層(Cache Tier)需要為每個Ceph存儲節點提供少數量的SSD或NVMe磁盤,并修改Crush Map映射以創建單獨的存儲類。
最佳實踐表明,除非您能夠準確預測實際數據量,否則緩存應不小于活動存儲池的1/10到1/8的容量。因此,如果您有100TB的數據池,則應計劃為您的緩存層提供大約10TB的存儲空間。
「Crush Map」
CRUSH 算法通過計算數據存儲位置來確定如何存儲和檢索。CRUSH 授權 Ceph 客戶端直接連接 OSD ,而非通過一個集中服務器或代理。數據存儲、檢索算法的使用,使 Ceph 避免了單點故障、性能瓶頸、和伸縮的物理限制。
CRUSH 需要一張集群的 Map,且使用 CRUSH Map 把數據偽隨機地、盡量平均地分布到整個集群的 OSD 里。CRUSH Map 包含 OSD 列表、把設備匯聚為物理位置的“桶”列表、和指示 CRUSH 如何復制存儲池里的數據的規則列表。
CRUSH Map負責確保數據最終到達群集中應有的位置,并在將IO請求轉換為磁盤位置以進行數據檢索中發揮作用。正確的CRUSH Map將考慮設備的適當權重,通常由磁盤大小決定,盡管您可以根據磁盤IOPS等其他因素來修改權重(一般不建議這樣做)。
「系統調整」
一個經過適當調優的系統將是實現Ceph預期性能的關鍵。請特別關注網絡和sysctl優化。一些關鍵參數包括:
- 「系統MTU」 :將其設置為9000以允許大幀。眾所周知,存儲流量在TCP堆棧上非常頻繁,應允許其盡可能多地傳輸數據而不會造成碎片,以確保您能夠充分使用存儲網絡。
- 「Swappiness」 :通常,使用swap分區是不太好的。每當您從內存切換到磁盤時,操作系統就會用完執行基本功能所需的內存,并且不得不將其中的某些內存強制降低到速度慢得多的磁盤上。在查看性能時,不能忽略Ceph群集的RAM分配的正確大小。可以在linux系統中配置Sysctl相應的參數,以強制linux停止使用交換分區。我們建議值為1,默認值通常可以在20到40之間。數字越大,內核嘗試交換的頻率就越高。
- 「“ noatime”」 :在大多數已掛載的文件系統上使用此選項,以跟蹤磁盤上文件的上次訪問時間。由于這是由OSD自己單獨處理的,因此在速度較慢的磁盤上禁用noatime可以提高性能。
「Ceph架構調整」
關于Ceph的配置以及優化的思路整體涉及如下:
- Mon節點對于群集的正常運行至關重要。嘗試并使用獨立的Mon節點,請確保資源獨享;或者,如果它們在共享環境中運行,則需要隔離Mon進程。為了實現冗余,請在Ceph集群中將Mon節點盡量均勻分布。
- Journal日志因雙寫緣故,對影響影響較大。理想情況下,您應該在單獨的物理磁盤上運行操作系統,OSD數據和OSD日志,以最佳的方式提高整體吞吐量。可以考慮將SSD用作Journal分區來提供讀寫吞吐量。
- 如果使用的是bluestore而非filestore的話,也請考慮rocksdb與wal的存儲使用SSD分區。
- 糾錯碼是對象存儲的一種數據持久性特性。當存儲大量一次寫入、不經常讀取的數據時,請使用糾錯碼。但是請記住,這是一個折衷方案:糾錯碼可以大大降低每GB的成本,但與副本相比,其IOPS性能較低。
- 支持dentry和inode緩存可以提高性能,尤其是在具有許多較小對象的群集上。
- 使用緩存分層,可以根據需求在熱層和冷層之間自動遷移數據,從而提高群集的性能。為了獲得最佳性能,請將SSD用于高速緩存池,并將存儲池托管在具有較低延遲的服務器上。
- 部署奇數個Mon節點(3個或5個)以進行法定投票。添加更多的Mon可使您的群集更持久。但是,這有時會降低性能,因為Mon之間還有更多數據要保持同步。
- 排查群集中的性能問題時,請始終從最低級別(磁盤,網絡或其他硬件)開始,然后逐步升級至更高級別(塊設備和對象網關)。
- PG和PGP數量一定要根據OSD的數量進行調整,不合理的PG數目會導致數據分布不均衡。
- Ceph OSD存在木桶原理,單個OSD的性能下降可能會影響整個集群的性能,所以要及時發現低性能的OSD,然后更換或者直接踢出集群。
「結論」
根據以上幾種方法可以正確實現Ceph以提供您期望的性能。利用磁盤緩存,緩存分層和適當配置的系統,可以確保磁盤性能不會成為基礎架構的瓶頸。
寫在最后
雖然開源存儲對于希望減少集中式商業存儲上的用戶而言來說是一個福音,但文檔和支持可能會受到限制。在沒有商業支持的前提下,除了靠社區的支持外,剩下的就靠用戶對軟件本身的熟悉程度。只有不斷的嘗試,不斷的優化,不斷的回饋社區,才能使開源軟件發展的更好。
參考:
https://ceph.readthedocs.io
http://www.slideshare.net/Inktank_Ceph/dell-ceph-22nd-london-v5
http://ceph.com/docs/master/start/hardware-recommendations/
http://www.inktank.com/inktank-ceph-enterprise/inktank-ceph-enterprise-1-2-arrives-with-erasure-coding-and-cache-tiering