Spark 和 Hadoop 是朋友不是敵人

6月15日,IBM 宣布計劃大規(guī)模投資 Spark 相關(guān)技術(shù),此項聲明會促使越來越多的工程師學(xué)習 Spark 技術(shù),并且大量的企業(yè)也會采用 Spark 技術(shù)。
Spark 投資的良性循環(huán)會使 Spark 技術(shù)發(fā)展更加成熟,并且可以從整個大數(shù)據(jù)環(huán)境中獲益。然而,Spark 的快速增長給人們一個奇怪且固執(zhí)的誤解:Spark 將取代 Hadoop,而不是作為 Hadoop 的補充。這樣的誤解可以從類似“旨在比下 Hadoop 的新軟件”和“企業(yè)將放棄大數(shù)據(jù)技術(shù) Hadoop”的標題中看出來。
作為一個長期的大數(shù)據(jù)實踐者,雅虎投資 Hadoop 的早期倡導(dǎo)者,一個為企業(yè)提供大數(shù)據(jù)服務(wù)的公司的 CEO ,我想在這篇文章中提出幾個明確的觀點。
Spark 和 Hadoop 會和諧相處。
越來越多的企業(yè)選擇 Hadoop 做大數(shù)據(jù)平臺,而 Spark 是運行于 Hadoop 頂層的內(nèi)存處理方案。Hadoop ***的用戶 —— 包括 eBay 和雅虎 —— 都在 Hadoop 集群中運行著 Spark。Cloudera 和 Hortonworks 將 Spark 列為他們 Hadoop 發(fā)行的一部分。自從我們推出 Spark 之后,用戶一直在使用著 Spark。
將 Spark 置于和 Hadoop 對立的位置,就好像是說你的新電動汽車看起來很高級,所以你的車就不需要充電一樣。如果電動汽車真的普及的話,那只會帶來更多的用電需求。
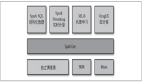
為什么這么迷惑呢?現(xiàn)在的 Hadoop 包括兩個主要的組件。***個是大規(guī)模儲存系統(tǒng),叫做 Hadoop Distributed File System (HDFS),它以低功耗、高性能的方式儲存數(shù)據(jù),并且能優(yōu)化大數(shù)據(jù)的種類和讀取速度。第二個是一個計算引擎,叫做 YARN,它能在儲存在 HDFS 上的數(shù)據(jù)頂層運行大規(guī)模并行程序。
YARN 可以承載任何數(shù)量的程序框架。原始的框架是 MapReduce,它由谷歌發(fā)明,用于處理大規(guī)模頁面抓取。Spark 是另一個類似的框架,另一個新的框架叫做 Tez。當人們談?wù)?Spark“干掉”Hadoop 時,他們往往指的是程序員更喜歡將 Spark 用在老的 MapReduce 框架上。
然而,MapReduce 不等同于 Hadoop。MapReduce 只是 Hadoop 集群處理數(shù)據(jù)的多種方式之一。Spark 可以是替代品。說得更寬點,商業(yè)分析師 —— 持續(xù)增長的大數(shù)據(jù)從業(yè)者 —— 會避免使用這兩個對于程序員來說十分低端的框架。相反,他們會使用更高級的語言,例如 SQL ,來讓 Hadoop 更容易訪問。
在過去的四年中,基于 Hadoop 的大數(shù)據(jù)技術(shù)達到了***的創(chuàng)新水平。我們已經(jīng)從 SQL 批處理轉(zhuǎn)向互動:從單一框架(MapReduce)轉(zhuǎn)到多框架(MapReduce、Spark 等等)。
我們已經(jīng)看到了 HDFS 優(yōu)異的性能和安全性的改善,并且我們還看到了頂層工具的井噴 , 例如 Datameer、H20 和 Tableau。大量不同領(lǐng)域的數(shù)據(jù)科學(xué)家和商業(yè)用戶使這些大數(shù)據(jù)工具變得更為易用。
Spark 對于 Hadoop 來說不是挑戰(zhàn),也不是來取代 Hadoop 的。相反,Hadoop 是 Spark 成長發(fā)展的基礎(chǔ)。我們希望兩個組織都能有長足的發(fā)展,并且成為將數(shù)據(jù)資產(chǎn)轉(zhuǎn)化為可執(zhí)行商業(yè)計劃的最有活力的平臺。