Spark的誤解-不僅Spark是內存計算,Hadoop也是內存計算
市面上有一些初學者的誤解,他們拿Spark和Hadoop比較時就會說,Spark是內存計算,內存計算是Spark的特性。請問在計算機領域,MySQL,Redis,SSH框架等等他們不是內存計算嗎?依據馮諾依曼體系結構,有什么技術的程序不是在內存中運行,需要數據從硬盤中拉取,然后供CPU進行執行?所有說Spark的特點是內存計算相當于什么都沒有說。
那么Spark的真正特點是什么?拋開Spark的執行模型的方式,它的特點無非就是多個任務之間數據通信不需要借助硬盤而是通過內存,大大提高了程序的執行效率。而Hadoop由于本身的模型特點,多個任務之間數據通信是必須借助硬盤落地的。那么Spark的特點就是數據交互不會走硬盤。只能說多個任務的數據交互不走硬盤,但是Spark的shuffle過程和Hadoop一樣仍然必須走硬盤的。
誤解一:Spark是一種內存技術
大家對Spark***的誤解就是spark一種內存技術。其實沒有一個Spark開發者正式說明這個,這是對Spark計算過程的誤解。Spark是內存計算沒有錯誤,但是這并不是它的特性,只是很多專家在介紹spark的特性時,簡化后就成了spark是內存計算。
什么樣是內存技術?就是允許你將數據持久化在RAM中并有效處理的技術。然而Spark并不具備將數據數據存儲在RAM的選項,雖然我們都知道可以將數據存儲在HDFS, HBase等系統中,但是不管是將數據存儲在磁盤還是內存,都沒有內置的持久化代碼。它所能做的事就是緩存數據,而這個并不是數據持久化。已經緩存的數據可以很容易地被刪除,并且在后期需要時重新計算。
但是有人還是會認為Spark就是一種基于內存的技術,因為Spark是在內存中處理數據的。這當然是對的,因為我們無法使用其他方式來處理數據。操作系統中的API都只能讓你把數據從塊設備加載到內存,然后計算完的結果再存儲到塊設備中。我們無法直接在HDD設備上計算;所以現代系統中的所有處理基本上都是在內存中進行的。
然Spark允許我們使用內存緩存以及LRU替換規則,但是你想想現在的RDBMS系統,比如Oracle ,你認為它們是如何處理數據的?它們使用共享內存段作為table pages的存儲池,所有的數據讀取以及寫入都是通過這個池的,這個存儲池同樣支持LRU替換規則;所有現代的數據庫同樣可以通過LRU策略來滿足大多數需求。但是為什么我們并沒有把Oracle 稱作是基于內存的解決方案呢?再想想操作系統IO,你知道嗎?所有的IO操作也是會用到LRU緩存技術的。
Spark在內存中處理所有的操作嗎?Spark的核心:shuffle,其就是將數據寫入到磁盤的。shuffle的處理包括兩個階段:map 和 reduce。Map操作僅僅根據key計算其哈希值,并將數據存放到本地文件系統的不同文件中,文件的個數通常是reduce端分區的個數;Reduce端會從 Map端拉取數據,并將這些數據合并到新的分區中。所有如果你的RDD有M個分區,然后你將其轉換成N個分區的PairRDD,那么在shuffle階段將會創建 M*N 個文件!雖然目前有些優化策略可以減少創建文件的個數,但這仍然無法改變每次進行shuffle操作的時候你需要將數據先寫入到磁盤的事實!
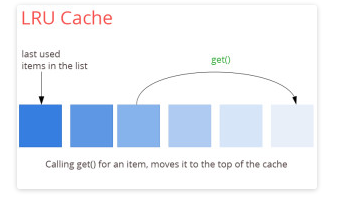
所以結論是:Spark并不是基于內存的技術!它其實是一種可以有效地使用內存LRU策略的技術。
誤解二:Spark要比Hadoop快 10x-100x
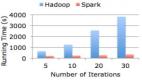
大家在Spark的官網肯定看到了如下所示的圖片
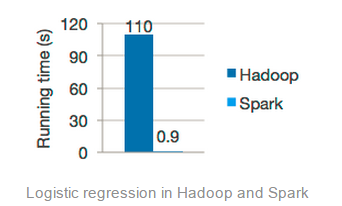
這個圖片是分別使用 Spark 和 Hadoop 運行邏輯回歸(Logistic Regression)機器學習算法的運行時間比較,從上圖可以看出Spark的運行速度明顯比Hadoop快上百倍!但是實際上是這樣的嗎?大多數機器學習算法的核心部分是什么?其實就是對同一份數據集進行相同的迭代計算,而這個地方正是Spark的LRU算法所驕傲的地方。當你多次掃描相同的數據集時,你只需要在***訪問時加載它到內存,后面的訪問直接從內存中獲取即可。這個功能非常的棒!但是很遺憾的是,官方在使用Hadoop運行邏輯回歸的時候很大可能沒有使用到HDFS的緩存功能,而是采用極端的情況。如果在Hadoop中運行邏輯回歸的時候采用到HDFS緩存功能,其表現很可能只會比Spark差3x-4x,而不是上圖所展示的一樣。
根據經驗,企業所做出的基準測試報告一般都是不可信的!一般獨立的第三方基準測試報告是比較可信的,比如:TPC-H。他們的基準測試報告一般會覆蓋絕大部分場景,以便真實地展示結果。
一般來說,Spark比MapReduce運行速度快的原因主要有以下幾點:
- task啟動時間比較快,Spark是fork出線程;而MR是啟動一個新的進程;
- 更快的shuffles,Spark只有在shuffle的時候才會將數據放在磁盤,而MR卻不是。
- 更快的工作流:典型的MR工作流是由很多MR作業組成的,他們之間的數據交互需要把數據持久化到磁盤才可以;而Spark支持DAG以及pipelining,在沒有遇到shuffle完全可以不把數據緩存到磁盤。
- 緩存:雖然目前HDFS也支持緩存,但是一般來說,Spark的緩存功能更加高效,特別是在SparkSQL中,我們可以將數據以列式的形式儲存在內存中。
所有的這些原因才使得Spark相比Hadoop擁有更好的性能表現;在比較短的作業確實能快上100倍,但是在真實的生產環境下,一般只會快 2.5x ~ 3x!
版權聲明:
作者:劉洋 合作微信號:intsmaze 本文版權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接,否則保留追究法律責任的權利。