逆水行舟,看前行中的Spark
近兩年,Spark技術發展速度驚人,用戶越來越多,社區也愈加活躍,生態更加豐富,這些都證明了Spark的魅力。在生態建設上,Spark取得了極大的成功,主要體現在Application、Environment及Data Source三個方面。此外,值得一提的是,Spark的貢獻者目前已經超過650人,而另一方面,圍繞Spark創業的公司同樣隨之增多,“Spark as a Service”的概念被越來越多的人接受,Spark的未來值得期待。在本文中,國內最早的Spark研究者與使用者、七牛云存儲技術總監陳超將為您解讀Spark技術及其生態系統的***進展。(本文已被選登在程序員電子版2015年9月A刊)。
到目前為止,Spark看起來一帆風順,但事實上,大數據這個領域從來不缺強者,其中***代表性的無疑當屬Flink(https://flink.apache.org)。Flink采了MPP的思想,具備很多有意思的設計和特性。本文不準備用過多的篇幅介紹Flink,主要給大家分享Spark最近幾個極其重要的改進。注意,下面所提到的改進有些已經實現,而有些尚未完成。
1. Project Tungsten
Spark近期的發展中,最引人矚目的當屬鎢絲計劃(Project Tungsten)。Kay Ousterhout在名為“Making Sense of Performance in Data Analytics Frameworks”的論文中談到,類似Spark這樣的計算框架,其瓶頸主要在于CPU與內存,而不是大家之前所認為的磁盤IO及網絡開銷,因為帶寬增大、SSD或者磁盤陣列的使用均可以緩解這個問題。但是在序列化、反序列化及Hash等場景下,CPU確實能形成瓶頸,Tungsten的啟動就是為了解決這些問題。Tungsten主要包含以下三個方面。
內存管理與二進制處理。
毋庸置疑,JVM確實是個非常優秀的平臺,但是短板也非常明顯,那就是GC,而Java對象的內存開銷同樣不能忽視。基于這個問題,Spark選擇自己管理內存,所用的工具就是sun.misc.Unsafe。如果大家對細節有興趣,可以關注BytesToBytesMap結構。需要注意,它是append-only的,并且key與value都是連續的字節區域。自己管理內存不僅緩解了GC的壓力,也顯著地降低了內存使用。但這里必須提醒大家,Unsafe千萬不能濫用,否則后果很嚴重。
緩存友好的計算。
目前,大家看到緩存似乎都只想到將數據加載到內存就完事了。事實上,更佳的做法應該是CPU級別的緩存。因此,Spark自1.4版本開始便在這個點上發力,其中,最重要的當屬在 Aggregations、Joins和Shuffle時可以更有效地排序和哈希。Spark引入了UnsafeShuffleManager這個新的ShuffleManager。它的好處是可以直接對二進制數據進行排序,從而減少了內存占用,也省去了反序列化的過程。這里大家可以注意下UnsafeShuffleExternalSorter,可以稱得上整個優化的基礎。實際上,CPU反復從內存讀取數據在一定程度上阻礙了CPU的Pipeline操作。
代碼生成(Code Gen)。
熟悉LLVM的朋友應該能較好地理解這一點,之前的Spark SQL已經在使用該部分了。近日發布的Spark 1.5中,Code Gen得到了更加廣泛的應用。需要Code Gen的原因很簡單,它能免去昂貴的虛函數調用,當然,也就不存在對Java基本類型裝箱之類的操作了。Spark SQL將Code Gen用于表達式的求值,效果顯著。值得一提的是,在Spark 1.5中,Spark SQL將Code Gen默認打開了。
Tungsten的部分就先談到這里,整個項目的完成需要等到1.6版本。不過1.4與1.5已經逐步融入了Tungsten的部分優化,讓大家可以及時感受Tungsten帶來的各種改進。
2. Dynamic Resource Allocation
嚴格地講,動態資源分配(Dynamic Resource Allocation)這個特性在Spark 1.2時就出現了,那時只支持在YARN上對資源做動態分配。在Spark 1.5中,Standalone及Mesos也將支持這個特性,個人認為此舉有較大意義,但大家仍需充分了解該特性的使用場景。
在Spark中,動態資源分配的粒度是Executor,通過spark.dynamicAllocation.enabled開啟,通過spark.dynamicAllocation.schedulerBacklogTimeout及 spark.dynamicAllocation.sustainedSchedulerBacklogTimeout兩個參數進行時間上的控制。另外,Spark對于YARN及Mesos的支持均得到了顯著地增強。
3. Adaptive Query Plan
適應查詢計劃(Adaptive Query Plan)是一個“可能”的特性。“可能”的原因是這一特性可能要等到Spark 1.6版本或者之后的版本才會有。首先,陳述幾個問題,如何自動確定并行度(Level of Parallelism);如何自動選擇采用Broadcast Join還是Hash Join;Spark如何感知數據的行為。
目前,Spark需要在執行Job前確定Job的DAG,即在執行前,由Operator到DAG的轉換就已經完成了,這樣顯然不夠靈活。因此,更好的方案是允許提交獨立的DAG stage,同時收集它們執行結果的一些統計信息。基于這些信息,Spark可以動態決定Reduce Task的數量,同時也可以動態地選擇是采用Broadcast還是Shuffle。對于Spark SQL來講,它應該能在聚合時自動設置Reduce Task的數量,并且在Join時自動選擇策略。主要的思路是,在決定Reduce Task的數量及采用的Shuffle策略前,先讓Map運算,然后輸出較大數量的Partition作為Map階段的結果。接下來,Spark會檢查Map Stages輸出的Partition的大小(或者其它一些狀態),然后基于這些信息做出***選擇。
估計大家已經看出,這里其實需要修改DAGScheduler的實現,因為目前的DAGScheduler僅支持接收一張完整的DAG圖,而上述討論的問題要求DAGScheduler支持接收Map Stages,且能收集Map Stages輸出結果的相關信息。Shuffle也需要支持能一次Fetch多個Map輸出的Partition,而目前的HashShuffleFetcher一次性只能獲取1個Partition。當然,這里還會涉及到其它改動,就不一一列出了。Adaptive Query Plan的重要性在于,Spark會替用戶確定運行時所需的一些參數及行為,從而用戶無需操心。還記得Flink那句宣傳語,即“用戶對內核唯一需要了解的事就是不需要了解內核”。
結語
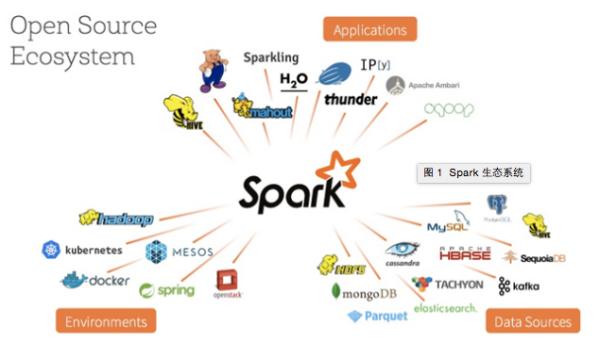
概括來講,Spark的護城河其實有兩條——其一是先進的技術,另一條則是豐富的生態系統。從上圖可以看出,無論是這段時間在容器領域無比火爆的Kubernete及Docker,還是在NoSQL領域的兩面錦旗HBase及Cassandra,亦或是其它如消息隊列Kafka、分布式搜索引擎Elasticsearch及各機器學習框架都與Spark產生了聯系,并且這樣的趨勢還在快速蔓延中。這意味著,Spark可能出現在大數據處理的各個領域,并給各個領域帶來明顯提升。
同時我了解到,很多朋友都在關注Spark在GPU方面的發展。關于這一點,現在業界也有了一些嘗試,但仍然有較長的路要走,讓我們一起期待在這個領域未來會發生些什么。
逆水行舟,不進則退。Spark在不停地進步著,真誠希望國內能有更多的工程師參與到Spark的開發中,同時也渴望看到更多有意思的Spark應用案例。目前,幾乎可以肯定,在大數據領域選擇Spark確實為一個明智之舉。