













深入內核:CBO對于Cost值相同索引的選擇
崔華,網名 dbsnake
Oracle ACE Director,ACOUG 核心專家
編輯手記:感謝崔華授權我們獨家轉載其精品文章,也歡迎大家向“Oracle”社區投稿。
這里我們稍微討論一下CBO對于Cost值相同的索引的選擇,可能會有朋友認為在同樣Cost的情況下,Oracle會按照索引名的字母順序來選擇索引,實際上并不完全是這樣,CBO對于Cost值相同的索引的選擇和Oracle的版本有關。
原理說明
MOS上文章“Handling of equally ranked (RBO) or costed (CBO) indexes [ID 73167.1]”明確指出——When the CBO detects 2 indexes that cost the same, it makes the decision based on the following:
(up to release 9.2.06) indexes ascii name so that index ‘AAA’ would be chosen over index ‘ZZZ’. See Bug 644757
(starting with 9.2.0.7 and in 10gR1) bigger NDK for fully matched indexes (not for fast full scans). See Bug 2720661
(in 10gR2 and above) index with lower number of leaf blocks. See Bug 6734618
這意味著對于Oracle 10gR2及其以上的版本,CBO對于Cost值相同的索引的選擇實際上會這樣:
1-如果Cost值相同的索引的葉子塊數量不同,則Oracle會選擇葉子塊數量較少的那個索引;
2-如果Cost值相同的索引的葉子塊數量相同,則Oracle會選擇索引名的字母順序在前面的那個索引。
測試驗證
這個非常容易驗證,我們來看一個實例。在一個11.2.0.3的環境中創建一個測試表T1:
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.3.0
Connected as nbs
SQL> create table t1 as select * from dba_objects;
Table created
對T1增加一列object_id_1,并將其值修改成和列object_id的值一致:
SQL> alter table t1 add (object_id_1 number);
Table altered
SQL> update t1 set object_id_1=object_id;
83293 rows updated
SQL> commit;
Commit complete
分別在列object_id和列object_id_1上創建名為a_idx_t1和b_idx_t1的B樹索引:
SQL> create index a_idx_t1 on t1(object_id);
Index created
SQL> create index b_idx_t1 on t1(object_id_1);
Index created
對表T1收集一下統計信息:
SQL> exec dbms_stats.gather_table_stats(ownname => ‘NBS’, tabname => ‘T1’, estimate_percent => 100, cascade => TRUE, no_invalidate => false);
PL/SQL procedure successfully completed
此時索引a_idx_t1和b_idx_t1的統計信息顯然是完全一致的(這意味著走這兩個索引的同類型執行計劃的Cost值會相同),從如下查詢結果中我們可以看到,它們的葉子塊的數量均為185:
SQL> select index_name,leaf_blocks from dba_indexes where table_owner=’NBS’ and table_name=’T1′;
INDEX_NAMELEAF_BLOCKS
—————————— ———–
A_IDX_T1185
B_IDX_T1 185
在當前情形下,如果我們執行目標SQL:
“select * from t1 where object_id=1000 and object_id_1=1000”
顯然此時Oracle既可以走索引a_idx_t1,也可以走索引b_idx_t1。
從如下查詢結果中我們可以看到,此時Oracle選擇了走索引a_idx_t1:
SQL> set autotrace traceonly explain
SQL> select * from t1 where object_id=1000 and object_id_1=1000;
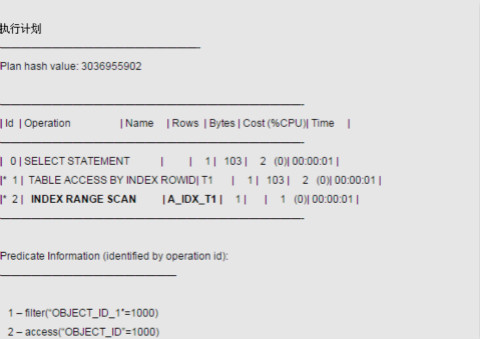
這就驗證了我們之前提到的結論——對于Oracle 10gR2及其以上的版本,如果Cost值相同的索引的葉子塊數量相同,則Oracle會選擇索引名的字母順序在前面的那個索引。
現在我們把索引b_idx_t1的葉子塊數量從之前的185改為現在的184:
SQL> exec dbms_stats.set_index_stats(ownname => ‘NBS’, indname => ‘B_IDX_T1’, numlblks => 184);
PL/SQL procedure successfully completed
從如下查詢結果中我們可以看到,上述改動生效了:
SQL> select index_name,leaf_blocks from dba_indexes where table_owner=’NBS’ and table_name=’T1′;
INDEX_NAMELEAF_BLOCKS
—————————— ———–
A_IDX_T1185
B_IDX_T1184
然后我們再次執行上述目標SQL:
SQL> select * from t1 where object_id=1000 and object_id_1=1000;

從上述顯示內容中我們可以看到,上述SQL的執行計劃從之前的走對索引a_idx_t1的索引范圍掃描變為了現在的走對索引b_idx_t1的索引范圍掃描,這就驗證了我們之前提到的結論:對于Oracle 10gR2及其以上的版本,如果Cost值相同的索引的葉子塊數量不同,則Oracle會選擇葉子塊數量較少的那個索引。

















