深入 Linux 內核理解 socket 的本質
本文將從一個初學者的角度開始聊起,讓大家了解 Socket 是什么以及它的原理和內核實現。

一、Socket 的概念
Socket 就如同我們日常生活中的插頭與插座的連接關系。在網絡編程中,Socket 是一種實現網絡通信的接口或機制。 想象一下,插頭插入插座后,電流得以流通,實現了能量的傳遞。而在網絡世界里,當一個程序使用 Socket 與另一臺機子建立“連接”時,就如同插頭成功插入了插座,數據能夠在兩者之間進行流通和交換。

例如,當我們在網上聊天時,發送方的程序通過 Socket 將消息發送出去,接收方的程序通過對應的 Socket 接收這些消息。又比如在下載文件時,下載程序通過 Socket 與提供文件的服務器建立連接,從而能夠獲取到所需的文件數據。
二、Socket 的使用場景
我們想要將數據從 A 電腦的某個進程發到 B 電腦的某個進程。如果需要確保數據能發給對方,就選可靠的 TCP 協議;如果數據丟了也沒關系,就選擇不可靠的 UDP 協議。初學者一般首選 TCP。
這時就需要用 socket 進行編程,首先創建關于 TCP 的 socket:
#include <iostream>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
int main() {
int sock_fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if (sock_fd == -1) {
std::cerr << "Failed to create socket" << std::endl;
return 1;
}
// 后續代碼...
return 0;
}這個方法會返回 sock_fd,它是 socket 文件的句柄。
對于服務端,得到 sock_fd 后,依次執行 bind()、listen()、accept() 方法,等待客戶端的連接請求;對于客戶端,得到 sock_fd 后,執行 connect() 方法向服務端發起建立連接的請求,此時會發生 TCP 三次握手。
連接建立完成后,客戶端可以執行 send() 方法發送消息,服務端可以執行 recv() 方法接收消息,反之亦然。

三、Socket 的設計
現在我們拋開socket,重新設計一個內核網絡傳輸功能。我們想要將數據從 A 電腦的某個進程發到 B 電腦的某個進程,從操作上來看,就是發數據給遠端和從遠端接收數據,也就是寫數據和讀數據。
但這里有兩個問題:
- 接收端和發送端可能不止一個,因此需要用 IP 和端口做區分,IP 用來定位是哪臺電腦,端口用來定位是這臺電腦上的哪個進程。
- 發送端和接收端的傳輸方式有很多區別,如可靠的 TCP 協議、不可靠的 UDP 協議,甚至還需要支持基于 icmp 協議的 ping 命令。
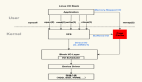
為了支持這些功能,需要定義一個數據結構 sock,在 sock 里加入 IP 和端口字段。這些協議雖然各不相同,但有一些功能相似的地方,可以將不同的協議當成不同的對象類(或結構體),將公共的部分提取出來,通過“繼承”的方式復用功能。
于是,定義了一些數據結構:
sock 是最基礎的結構,維護一些任何協議都有可能會用到的收發數據緩沖區。
在 Linux 內核 2.6 相關的源碼中,sock 結構體的定義可能類似于:
struct sock {
// 相關字段
struct sk_buff_head sk_receive_queue; // 接收數據緩沖區
struct sk_buff_head sk_write_queue; // 發送數據緩沖區
// 其他可能的字段
};inet_sock 特指用了網絡傳輸功能的 sock,在 sock 的基礎上還加入了 TTL、端口、IP 地址這些跟網絡傳輸相關的字段信息。比如 Unix domain socket,用于本機進程之間的通信,直接讀寫文件,不需要經過網絡協議棧。
可能的定義:
struct inet_sock {
struct sock sk; // 繼承自 sock
__be32 port; // 端口
__be32 saddr; // IP 地址
// 其他相關字段
};inet_connection_sock 是指面向連接的 sock,在 inet_sock 的基礎上加入面向連接的協議里相關字段,比如 accept 隊列、數據包分片大小、握手失敗重試次數等。雖然現在提到面向連接的協議就是指 TCP,但設計上 Linux 需要支持擴展其他面向連接的新協議。
例如:
struct inet_connection_sock {
struct inet_sock inet; // 繼承自 inet_sock
struct request_sock_queue accept_queue; // accept 隊列
// 其他相關字段
};tcp_sock 就是正兒八經的 TCP 協議專用的 sock 結構,在 inet_connection_sock 基礎上還加入了 TCP 特有的滑動窗口、擁塞避免等功能。同樣 UDP 協議也會有一個專用的數據結構,叫 udp_sock。
大概如下:
struct tcp_sock {
struct inet_connection_sock icsk; // 繼承自 inet_connection_sock
// TCP 特有的字段,如滑動窗口、擁塞避免等相關字段
};
有了這套數據結構,將它跟硬件網卡對接一下,就實現了網絡傳輸的功能。
四、提供 Socket 層
由于這里面的代碼復雜,還操作了網卡硬件,需要較高的操作系統權限,再考慮到性能和安全,于是將它放在操作系統內核里。
為了讓用戶空間的應用程序使用這部分功能,將這部分功能抽象成簡單的接口,將內核的 sock 封裝成文件。創建 sock 的同時也創建一個文件,文件有個文件描述符 fd,通過它可以唯一確定是哪個 sock。將fd暴露給用戶,用戶就可以像操作文件句柄那樣去操作這個 sock 。
struct file{
//文件相關的字段
.....
void *private_data; //指向sock
}創建socket時,其實就是創建了一個文件結構體,并將private_data字段指向sock。

有了 sock_fd 句柄后,提供了一些接口,如 send()、recv()、bind()、listen()、connect() 等,這些就是 socket 提供出來的接口。
所以說,socket 其實就是個代碼庫或接口層,它介于內核和應用程序之間,提供了一堆接口,讓我們去使用內核功能,本質上就是一堆高度封裝過的接口。
我們平時寫的應用程序里代碼里雖然用了socket實現了收發數據包的功能,但其 實真正執行網絡通信功能的,不是應用程序,而是linux內核。

在操作系統內核空間里,實現網絡傳輸功能的結構是sock,基于不同的協議和應用場景,會被泛化為各種類型的xx_sock,它們結合硬件,共同實現了網絡傳輸功能。為了將這部分功能暴露給用戶空間的應用程序使用,于是引入了socket層,同時將sock嵌入到文件系統的框架里,sock就變成了一個特殊的文件,用戶就可以在用戶空間使用文件句柄,也就是socket_fd來操作內核sock的網絡傳輸能力。
五、Socket 如何實現網絡通信
以最常用的 TCP 協議為例,實現網絡傳輸功能分為建立連接和數據傳輸兩個階段。
1. 建立連接
在客戶端,執行 socket 提供的 connect(sockfd, "ip:port") 方法時,會通過 sockfd 句柄找到對應的文件,再根據文件里的信息指向內核的 sock 結構,通過這個 sock 結構主動發起三次握手。
在服務端,握手次數還沒達到“三次”的連接叫半連接,完成好三次握手的連接叫全連接,它們分別會用半連接隊列和全連接隊列來存放,這兩個隊列會在執行 listen() 方法的時候創建好。當服務端執行 accept() 方法時,就會從全連接隊列里拿出一條全連接。
雖然都叫隊列,但半連接隊列其實是個哈希表,而全連接隊列其實是個鏈表。
在 Linux 內核 2.6 版本的源碼中,相關的代碼實現可能位于網絡子系統的部分。例如,建立連接的過程可能涉及到 tcp_connect() 等函數。
2. 數據傳輸
為了實現發送和接收數據的功能,sock 結構體里帶了一個發送緩沖區和一個接收緩沖區,其實就是個鏈表,上面掛著一個個準備要發送或接收的數據。
當應用執行 send() 方法發送數據時,會通過 sock_fd 句柄找到對應的文件,根據文件指向的 sock 結構,找到這個 sock 結構里帶的發送緩沖區,將數據放到發送緩沖區,然后結束流程,內核看心情決定什么時候將這份數據發送出去。

接收數據流程也類似,當數據送到 Linux 內核后,先放在接收緩沖區中,等待應用程序執行 recv() 方法來拿。
當應用進程執行 recv() 方法嘗試獲取(阻塞場景下)接收緩沖區的數據時,如果有數據,取走就好;如果沒數據,就會將自己的進程信息注冊到這個 sock 用的等待隊列里,然后進程休眠。如果這時候有數據從遠端發過來了,數據進入到接收緩沖區時,內核就會取出 sock 的等待隊列里的進程,喚醒進程來取數據。

當多個進程通過 fork 的方式 listen 了同一個 socket_fd,在內核它們都是同一個 sock,多個進程執行 listen() 之后,都會將自身的進程信息注冊到這個 socket_fd 對應的內核 sock 的等待隊列中。在 Linux 2.6 以前,會喚醒等待隊列里的所有進程,但最后其實只有一個進程會處理這個連接請求,其他進程又重新進入休眠,會消耗一定的資源,這就是驚群效應。在 Linux 2.6 之后,只會喚醒等待隊列里的其中一個進程,這個問題被修復了。
服務端 listen 的時候,那么多數據到一個 socket 怎么區分多個客戶端的?以 TCP 為例,服務端執行 listen 方法后,會等待客戶端發送數據來。客戶端發來的數據包上會有源 IP 地址和端口,以及目的 IP 地址和端口,這四個元素構成一個四元組,可以用于唯一標記一個客戶端。服務端會創建一個新的內核 sock,并用四元組生成一個 hash key,將它放入到一個 hash 表中。下次再有消息進來的時候,通過消息自帶的四元組生成 hash key 再到這個 hash 表 里重新取出對應的 sock 就好了。

六、Socket 怎么實現“繼承”
Linux 內核是 C 語言實現的,而 C 語言沒有類也沒有繼承的特性,是通過結構體里的內存是連續的這一特點來實現“繼承”的效果。將要繼承的“父類”,放到結構體的第一位,然后通過結構體名的長度來強行截取內存,這樣就能轉換結構體,從而實現類似“繼承”的效果。

例如:
struct tcp_sock {
/* inet_connection_sock has to be the first member of tcp_sock */
struct inet_connection_sock inet_conn;
// 其他字段
};
struct inet_connection_sock {
/* inet_sock has to be the first member! */
struct inet_sock icsk_inet;
// 其他字段
};
// sock 轉為 tcp_sock
static inline struct tcp_sock *tcp_sk(const struct sock *sk) {
return (struct tcp_sock *)sk;
}七、總結
socket 中文套接字,可理解為一套用于連接的數字。
sock 在內核,socket_fd 在用戶空間,socket 層介于內核和用戶空間之間。
在操作系統內核空間里,實現網絡傳輸功能的結構是 sock,基于不同的協議和應用場景,會被泛化為各種類型的 xx_sock,它們結合硬件,共同實現了網絡傳輸功能。為了將這部分功能暴露給用戶空間的應用程序使用,于是引入了 socket 層,同時將 sock 嵌入到文件系統的框架里,sock 就變成了一個特殊的文件,用戶就可以在用戶空間使用文件句柄,也就是 socket_fd 來操作內核 sock 的網絡傳輸能力。
服務端可以通過四元組來區分多個客戶端。
內核通過 C 語言“結構體里的內存是連續的”這一特點實現了類似繼承的效果。