新浪微博王傳鵬:認識每一個“你” 微博中的用戶模型
原創【講師簡介】
王傳鵬,新浪微博推薦及廣告技術總監。2006年從北航畢業,然后加入霍尼韋爾北京研中心做工程,之后同合伙人一起創辦云存儲網絡硬盤(99盤)。在公司被收購后,加入當當網負責推薦和廣告工作。于2011年加入新浪微博商業產品部,負責推薦和廣告,直至現在。
馮揚,微博推薦開發技術專家。目前,負責新浪微博搭建微博推薦平臺與建立針對推薦的用戶模型兩方面工作。前者是 指在微博現有的技術基礎和分層架構上,設計微博的標準化推薦架構,搭建推薦平臺,解決推薦業務中物料和特征數據接入、推薦計算、模型訓練、橫向對比等方面 的問題;后者是針對微博推薦業務中所需的基礎數據,尤其是用戶相關的基礎數據挖掘,為推薦服務。
【演講干貨】
王傳鵬在演講一開始,就像大家說明由于微博推薦開發技術專家馮揚家里有私事不能參加,由他來進行此次的演講。此次演講的主題由微博用戶模型的維度劃分、建模目標和方法、用戶模型在微博推薦中的應用三部分組成。
微博用戶模型的維度劃分如下圖:
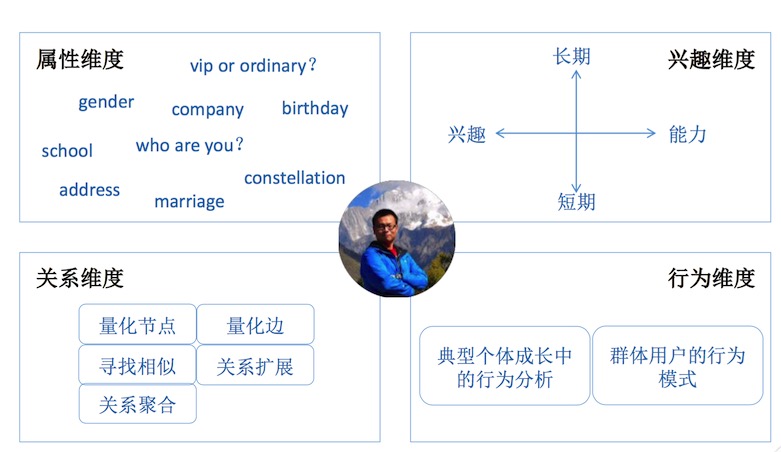
用戶屬性&用戶興趣(用戶畫像)
用戶畫像
屬性和興趣維度的用戶模型都可以歸入用戶畫像(User Profile)的范疇,即對用戶的信息進行標簽化。一方面,標簽化是對用戶信息進行結構化,方便計算機的識別和處理;另一方面,標簽本身也具有準確性和非二義性,也有利于人工的整理、分析和統計。
興趣維度
用戶屬性指相對靜態和穩定的人口屬性,例如:性別、年齡區間、地域、受教育程度、學校、公司……這些信息的收集和建立主要依靠產品本身的引導、調查、第三方提供等,在此基礎上需要進行補充和交叉驗證。
用戶興趣則是更加動態和易變化的特征,首先興趣受到人群、環境、熱點事件、行業……等方面的影響,一旦這些因素發生變化,用戶的興趣容易產生遷移;其次,用戶的行為(特指在互聯網上的行為)多樣且碎片化,不同行為反映出來的興趣差異較大,在用戶興趣分析的過程中,主要考慮如下幾個方面:
(1) 標簽來源:不是所有的詞都適合充當用戶標簽,這些詞本身應該具有區分性和非二義性;此外,還需要考慮來源的全面性,除了用戶主動提供的興趣標簽外,用戶在使用微博的過程中的行為,構建的用戶關系等也能夠反應用戶的興趣,因此也要將其考慮在內。
(2) 權重計算:得到了用戶的興趣標簽,還需要針對用戶給這些標簽進行權重賦值,用來區分不同標簽對于該用戶的重要程度。
(3) 時效性:隨著時間的變化,用戶的興趣會發生轉移,有些興趣會貫穿用戶使用社交媒體的全過程,而有些興趣則是受熱點時間、環境因素等的影響。
(4) 興趣和能力的區分:用戶具有某方面的興趣,只代表了他愿意接受這方面的信息,并不能代表他具有產生相關內容的能力。區分興趣和能力,能有助于預測興趣相關內容潛在的生產者和傳播者。
社交關系模型
關系維度
如果將微博中的用戶視作節點,用戶之間的關系視作節點之間的邊,那么這些節點和邊將構成一個社交的網絡拓撲結構,或稱作社交圖譜。微博中的信息就是在這個圖譜上進行傳播。
從社交的維度建立用戶模型,需要從不同的角度細致和全面地描述這個社交圖譜的特征,反應影響信息傳播的各層面上的因素,尋找節點之間的關聯想,以及刻畫圖譜本身的結構特征。其中包括:
(1) 用戶個體對信息傳播的影響:不同用戶在信息傳播過程中的重要性不一樣,影響大的用戶對于信息的傳播較影響小的用戶更具有促進作用。
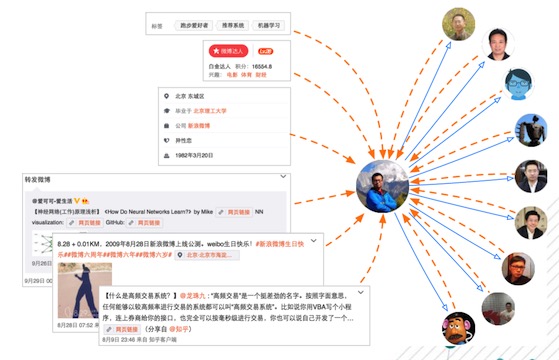
(2) 量化用戶關系的遠近:衡量存在直接關聯(關注、被關注、互粉……)用戶之間的關系遠近,關系越近的用戶之間越容易產生信息傳播行為。
(3) 延伸用戶之間的關系:通過用戶之間的直接關系(關注、被關注、互粉……),讓本身并不存在直接關系的用戶產生關聯。
(4) 尋找相似的用戶:微博中非對等的關系本身可以認為是一種認證,用戶基于興趣、線下關系、或某種其它原因反應到線上的一種關聯。那么在關系維度上的相似用戶至少能反應他們在某種因素上的一致性。
(5) 識別關系圈:從關系圖譜的本身的結構出發,從中發掘關聯緊密的群體,有助于信息的精準投放和推廣。
以上關于關系建模的任務可以看作是逐步深入的,從“個體”-->“關聯”-->“相似”-->“群體”的逐漸深入。
用戶行為模型
行為維度
分析用戶的行為,建立行為模式有兩個任務:針對典型個體行為進行時序分片,分析用戶成長的相關因素;針對典型群體的行為進行統計,構建其行為模型。
(1) 典型個體的行為時序分析
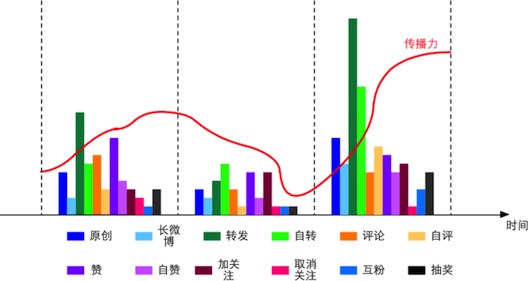
所謂典型個體是指某段時間內,成長比較突出的微博用戶。例如從一個新用戶從新注冊到粉絲過百、過千需要有一個積累過程,有些用戶積累較快,有些較慢,而這些積累較快的用戶可以作為典型個體;或者某些用戶在某一階段傳播力有限,但在某時刻傳播力激增,無論是互動還是內容傳播覆蓋面都變化很大,這種也可以作為典型個體。
針對典型個體,需要挖掘與其用戶成長相關的行為因素。基本方法是對時間進行分片,獲取用戶在不同時間片上的行為統計,以及在各個時間分片上的用戶成長指標(粉絲數、互動率、傳播力等),如圖2所示。在此基礎上針對用戶行為的統計量的變化,利用關聯性分析或回歸來分析用戶成長與哪些因素有關。
(2) 典型群體行為模式分析
針對典型個體,從用戶的基本信息、人口信息、興趣維度,可以將相似的典型用戶劃分為同一的群體,稱作典型群體,針對典型群體中的用戶按照成長程度進行劃分,按不同的成長階段統計用戶行為,即建立了該典型群體的行為模型。
例如,對于“北京,年齡在20~30歲,女性,電商領域,普通賬號”這樣的典型群體,從粉絲數、傳播力、互動率等維度將其劃分到初創、成長、快速提升、成熟……等階段,針對不同成長階段內的行為組合進行統計,結果構成該群體的行為模式。
用戶模型在微博推薦中的應用
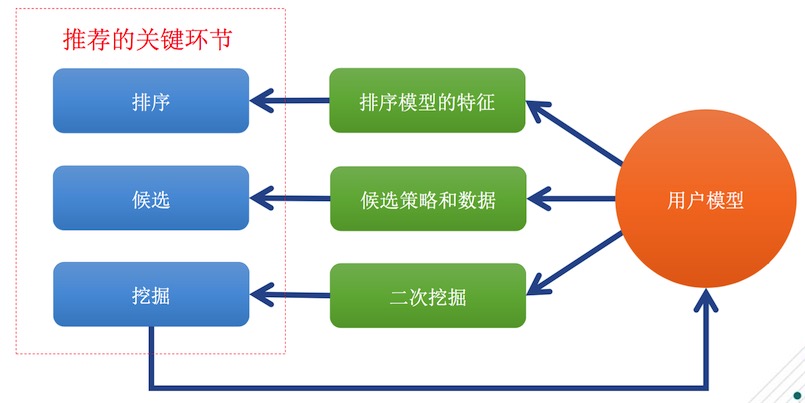
推薦主要由排序、候選、挖掘三部分構成,在這三個階段過程中排序時會用到排序模型、候選的策略和數據、挖掘這里比較重要的是二次挖掘。當用戶模型產生之后,可以更加深入的統計出有用的信息,這樣一來,用戶模型就得到了相應的應用。在排序時候,我們會用到用戶模型的各種特征。在候選時候,你有可能感興趣的人,好友關注都是通過候選方法通過關系圈擴展得來的。還有內容推薦,好友贊微博也是通過候選實現的。
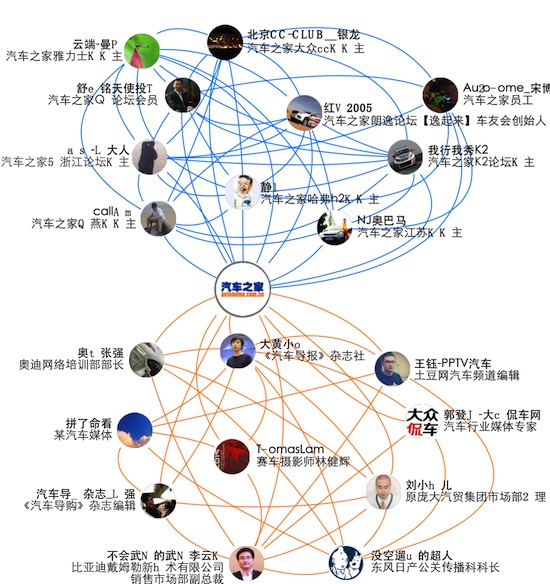
二次挖掘應用舉例
在挖掘的時候,所有的數據都將派上用場。比如說領域關系圈的二次挖掘,在這里是先有能力標簽、之后通過標簽把相應的用戶找到,設立為種子用戶。之后再利用一度和二度的關系及相似用戶的擴充,這樣就會得到一個領域關系圈。