認識每一個“你”:微博中的用戶模型
原創社交媒體(Social Media)相對于傳統互聯網媒體的最大區別是通過建立人與人之間的聯系,極大提升了信息生產量以及傳播效率。身處社交媒體中的每個人或組織同時扮演著信息生產者、傳播者與接受者的角色。

在社交媒體背景下,用戶生產、傳播和接收信息更加便捷,使得之前相對集中的用戶興趣和行為變得更加碎片化和離散,因此社交媒體中的用戶模型的構建和應用也發生了巨大的變化。
微博經歷了6年的發展,已經成為了國內社交媒體的中堅力量。本文從微博的角度出發,對微博中用戶模型的目的、維度和建模任務進行描述,并作為后續微博用戶模型相關文章的總述。
1 構建用戶模型的目的
刻畫每個用戶,是任何一家社交類型的服務都需要面對的問題。不同的公司針對各自業務會有不同的需求,構建用戶模型的動機和目標也會存在一定差異。從微博自身的角度來講,構建用戶模型的目的包括:
(1) 完善及擴充微博用戶信息
用戶模型的首要動機就是了解用戶,這樣才能夠提供更優質的服務。但是在微博中用戶的信息提供得不盡完整,有些是因為平臺的引導機制造成的(例如填寫公司學校信息的時候,相應的機構名或者學校名并不在列表內),有時候又是用戶不愿意或懶得提供(例如針對一些非必選項),而且對于用戶自行輸入的內容又很難進行規范化……此外,一些隱性或變化頻繁的信息(例如用戶的興趣、商業偏好、地理位置的變化等等)也需要通過用戶的行為挖掘出來。
(2) 分析微博生態
除了了解用戶,還需要了解自己。在掌握用戶信息的基礎上,平臺就可以對自身的狀況進行分析,從相對宏觀的基礎上把握微博的生態環境,為后續的優化和發展提供方向性。例如通過對用戶信息的聚類,能夠對微博用戶進行人群的劃分,掌握不同人群的活躍程度,信息的傳播和引爆方式,行為及興趣偏好等等。
(3) 支撐微博業務
在微博中的各項業務都與用戶模型有著直接與間接的關系,無論是基于興趣的推薦提升用戶價值,精準的廣告投放提升商業價值,還是針對特定群體的內容運營,用戶模型都是其必不可少的基礎支撐。直接地,用戶模型可以用于興趣匹配、關系匹配的推薦和投放;間接地,可以基于用戶模型中相似的興趣、關系及行為模式去推動信息及賬號的傳播和成長。
#p#
2 微博用戶模型的維度劃分
一個用戶可以從多個方面去刻畫,也就是說用戶模型可以從多個維度來考慮和構建。
作為社交媒體,微博用戶在平臺上通過某些行為(如發微博、點擊圖片、播放視頻、瀏覽信息流……)生產或獲取信息,也通過其它一些行為(如轉發、評論、贊……)將信息傳播出去,信息的傳播是通過用戶之間的社交關系所進行的,并且在生產、消費、傳播信息的過程中對信息的選擇和過濾體現了用戶在興趣方面的傾向性。由此,我們可以將微博用戶模型按照圖1所示的四個維度進行劃分,即屬性維度、興趣維度、社交維度和行為維度。
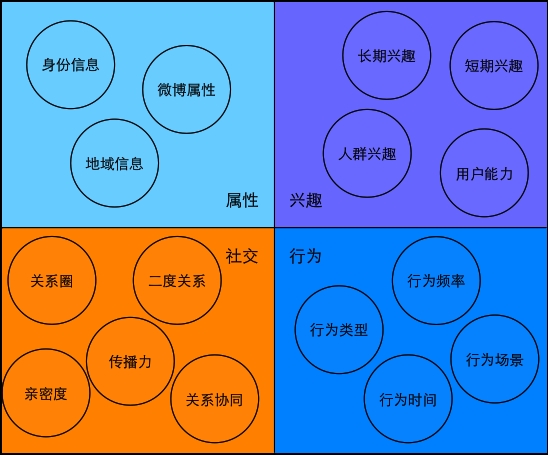
圖1 微博用戶模型的維度劃分
用戶屬性和用戶興趣是通常用戶畫像中包含的兩個維度。前者刻畫用戶的靜態屬性特征,例如用戶的身份信息(性別、年齡、受教育程度、學校、工作單位……),后者則用于刻畫用戶在信息篩選方面的傾向(例如用戶的興趣標簽、能力標簽等)。
社交維度是從社交關系及信息傳播的角度來刻畫用戶的。在社交媒體中,用戶不在僅僅是一個個體,用戶以及用戶之間的社交關系構成了一張網絡,信息在這張網絡中高速流動,但是這種流動并不是無差別的,信息的起始點,所經歷的關鍵節點以及這些節點構成的關系圈都是影響信息流動的重要因素。社交維度就是要量化這些因素以及其影響程度。
行為維度是一個比較新的研究方向,目的是發現影響用戶屬性、信息變化的行為因素,分析典型用戶群體的行為模式。一方面可以通過行為模式的復用來促進用戶在微博平臺的成長;另一方面也有利于平臺認識用戶,和發現新的或異常的用戶行為。
#p#
3 用戶建模的任務
3.1 屬性和興趣維度(用戶畫像)
屬性和興趣維度的用戶模型都可以歸入用戶畫像(User Profile)的范疇,即對用戶的信息進行標簽化。一方面,標簽化是對用戶信息進行結構化,方便計算機的識別和處理;另一方面,標簽本身也具有準確性和非二義性,也有利于人工的整理、分析和統計。
用戶屬性指相對靜態和穩定的人口屬性,例如:性別、年齡區間、地域、受教育程度、學校、公司……這些信息的收集和建立主要依靠產品本身的引導、調查、第三方提供等,在此基礎上需要進行補充和交叉驗證。
用戶興趣則是更加動態和易變化的特征,首先興趣受到人群、環境、熱點事件、行業……等方面的影響,一旦這些因素發生變化,用戶的興趣容易產生遷移;其次,用戶的行為(特指在互聯網上的行為)多樣且碎片化,不同行為反映出來的興趣差異較大,在用戶興趣分析的過程中,主要考慮如下幾個方面:
(1) 標簽來源:不是所有的詞都適合充當用戶標簽,這些詞本身應該具有區分性和非二義性;此外,還需要考慮來源的全面性,除了用戶主動提供的興趣標簽外,用戶在使用微博的過程中的行為,構建的用戶關系等也能夠反應用戶的興趣,因此也要將其考慮在內。
(2) 權重計算:得到了用戶的興趣標簽,還需要針對用戶給這些標簽進行權重賦值,用來區分不同標簽對于該用戶的重要程度。
(3) 時效性:隨著時間的變化,用戶的興趣會發生轉移,有些興趣會貫穿用戶使用社交媒體的全過程,而有些興趣則是受熱點時間、環境因素等的影響。
(4) 興趣和能力的區分:用戶具有某方面的興趣,只代表了他愿意接受這方面的信息,并不能代表他具有產生相關內容的能力。區分興趣和能力,能有助于預測興趣相關內容潛在的生產者和傳播者。
3.2 社交維度
如果將微博中的用戶視作節點,用戶之間的關系視作節點之間的邊,那么這些節點和邊將構成一個社交的網絡拓撲結構,或稱作社交圖譜。微博中的信息就是在這個圖譜上進行傳播。
從社交的維度建立用戶模型,需要從不同的角度細致和全面地描述這個社交圖譜的特征,反應影響信息傳播的各層面上的因素,尋找節點之間的關聯想,以及刻畫圖譜本身的結構特征。其中包括:
(1) 用戶個體對信息傳播的影響:不同用戶在信息傳播過程中的重要性不一樣,影響大的用戶對于信息的傳播較影響小的用戶更具有促進作用。
(2) 量化用戶關系的遠近:衡量存在直接關聯(關注、被關注、互粉……)用戶之間的關系遠近,關系越近的用戶之間越容易產生信息傳播行為。
(3) 延伸用戶之間的關系:通過用戶之間的直接關系(關注、被關注、互粉……),讓本身并不存在直接關系的用戶產生關聯。
(4) 尋找相似的用戶:微博中非對等的關系本身可以認為是一種認證,用戶基于興趣、線下關系、或某種其它原因反應到線上的一種關聯。那么在關系維度上的相似用戶至少能反應他們在某種因素上的一致性。
(5) 識別關系圈:從關系圖譜的本身的結構出發,從中發掘關聯緊密的群體,有助于信息的精準投放和推廣。
以上關于關系建模的任務可以看作是逐步深入的,從“個體”-->“關聯”-->“相似”-->“群體”的逐漸深入。
3.3 行為維度
分析用戶的行為,建立行為模式有兩個任務:針對典型個體行為進行時序分片,分析用戶成長的相關因素;針對典型群體的行為進行統計,構建其行為模型。
(1) 典型個體的行為時序分析
所謂典型個體是指某段時間內,成長比較突出的微博用戶。例如從一個新用戶從新注冊到粉絲過百、過千需要有一個積累過程,有些用戶積累較快,有些較慢,而這些積累較快的用戶可以作為典型個體;或者某些用戶在某一階段傳播力有限,但在某時刻傳播力激增,無論是互動還是內容傳播覆蓋面都變化很大,這種也可以作為典型個體。
針對典型個體,需要挖掘與其用戶成長相關的行為因素。基本方法是對時間進行分片,獲取用戶在不同時間片上的行為統計,以及在各個時間分片上的用戶成長指標(粉絲數、互動率、傳播力等),如圖2所示。在此基礎上針對用戶行為的統計量的變化,利用關聯性分析或回歸來分析用戶成長與哪些因素有關。
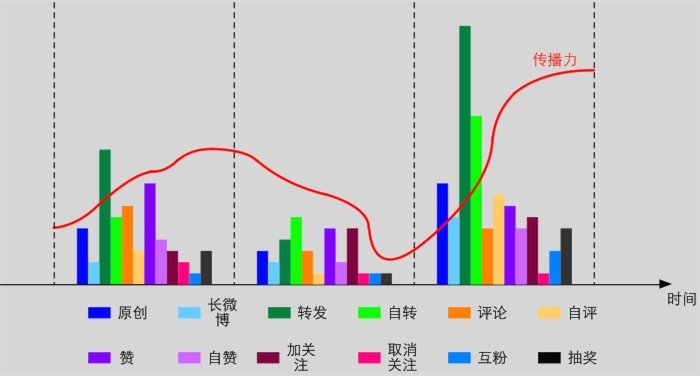
圖2 時間分片上的用戶行為統計
(2) 典型群體行為模式分析
針對典型個體,從用戶的基本信息、人口信息、興趣維度,可以將相似的典型用戶劃分為同一的群體,稱作典型群體,針對典型群體中的用戶按照成長程度進行劃分,按不同的成長階段統計用戶行為,即建立了該典型群體的行為模型。
例如,對于“北京,年齡在20~30歲,女性,電商領域,普通賬號”這樣的典型群體,從粉絲數、傳播力、互動率等維度將其劃分到初創、成長、快速提升、成熟……等階段,針對不同成長階段內的行為組合進行統計,結果構成該群體的行為模式。
4 小結
構建用戶模型是社交媒體中的基礎工作,涉及到數據、統計、挖掘等各方面的技術和手段。本文針對微博的特點和業務需要,針對其中的用戶模型構建的目標和任務進行了簡述。全文并沒有涉及具體的方法和原理,后續會有相應的技術文章進行介紹。
需要指出的是,不同于傳統互聯網媒體,微博作為社交媒體最大的優勢在于引入了非對等的用戶關系,這種關系不僅令傳播更加高效,也令考慮關系因素成為了用戶建模中(無論是在屬性、興趣、社交還是行為維度上)非常重要手段。
想要進一步了解相關內容可關注——微博:wbrecom 公眾號:微博推薦平臺