阿里肖冰:如何實現(xiàn)分鐘級別的HBase宕機(jī)恢復(fù)
原創(chuàng)Apache HBase是一個面向線上服務(wù)的數(shù)據(jù)庫,其原生支持Hadoop的特性,使其成為那些基于Hadoop的擴(kuò)展性和靈活性進(jìn)行數(shù)據(jù)處理的應(yīng)用顯而易見的選擇,近幾年在全球得到了快速發(fā)展。
對任何一款數(shù)據(jù)存儲產(chǎn)品進(jìn)行評價時,高可用性(HA)都是一個核心的考量指標(biāo),也是核心業(yè)務(wù)應(yīng)用的先決條件。然而硬件故障、斷網(wǎng)斷電以及諸多不可預(yù)料的故障時刻都在挑戰(zhàn)著HBase的高可用性。從2011年開始,阿里就開始了在HBase上的應(yīng)用研究和探索之路,目前已擁有上萬臺HBase集群規(guī)模。經(jīng)歷過近五年時間的大量業(yè)務(wù)錘煉,阿里HBase在性能優(yōu)化、功能完善、高可用性改進(jìn)等方面,都積累了大量經(jīng)驗。
在WOT2016互聯(lián)網(wǎng)運維與開發(fā)者大會現(xiàn)場,51CTO記者獨家專訪到阿里巴巴集團(tuán)技術(shù)保障部系統(tǒng)工程師肖冰,探尋阿里HBase高可用性改善方面的技術(shù)細(xì)節(jié)。
嘉賓簡介
肖冰,阿里巴巴集團(tuán)技術(shù)保障部系統(tǒng)工程師,入職以來一直從事阿里HBase集群的一線運維工作,負(fù)責(zé)保障整個阿里集團(tuán)HBase集群的穩(wěn)定性和高可用。承擔(dān)HBase大促核心業(yè)務(wù)單元化改造、MTTR落地、混合存儲落地等重要工作。
肖冰介紹,阿里HBase團(tuán)隊的職責(zé)分工主要為兩個方向,一是運維團(tuán)隊,主要幫助阿里內(nèi)部的各業(yè)務(wù)方制訂存儲方案,并負(fù)責(zé)后期的穩(wěn)定護(hù)航;另外是HBase源碼開發(fā)團(tuán)隊,主要是做代碼層的HBase優(yōu)化,提升HBase整體性能。這兩支隊伍緊密合作,基于阿里巴巴自身業(yè)務(wù)場景和特點,對社區(qū)HBase進(jìn)行深度定制與改進(jìn),從解決方案、穩(wěn)定護(hù)航、發(fā)展支撐方面為集團(tuán)內(nèi)部的各業(yè)務(wù)部門提供一整套完善NoSQL服務(wù)。
阿里HBase主要用于存放大量線上關(guān)鍵業(yè)務(wù)的數(shù)據(jù),比如我們常用的支付寶錢包中用戶帳單、消費記錄、通訊錄聯(lián)系人、在淘寶購物時賣家向買家發(fā)送的物流詳情等數(shù)據(jù)。總的來說,Hbase面向的都是大數(shù)據(jù)量、大吞吐,并且存儲和讀取相對簡單的業(yè)務(wù)。它的優(yōu)勢在于服務(wù)能力能夠快速水平擴(kuò)展,并且單集群就可以支撐上百萬甚至上千萬的TPS、QPS。
阿里HBase集群高可用之路
阿里Hbase的運維監(jiān)控集中在兩個層面。一是監(jiān)控報警系統(tǒng),主要用來監(jiān)控網(wǎng)絡(luò)、CPU損耗等集群本身進(jìn)程的健康狀態(tài)。另外是對業(yè)務(wù)層面的監(jiān)控,也就是根據(jù)業(yè)務(wù)需求在代碼里面設(shè)置許多信息采集的錨點,來統(tǒng)計某一集群在一段時間的TPS、QPS、網(wǎng)絡(luò)IO是多少。通過這兩個層面監(jiān)控的配合,來精準(zhǔn)定位問題,解決問題。
為了使集群可用率達(dá)到四個九的標(biāo)準(zhǔn),阿里HBase主要通過單機(jī)故障的快速恢復(fù)機(jī)制、跨機(jī)房跨地域的集群部署以及快速透明的主備切換方式將這些問題攻破。
縮短節(jié)點宕機(jī)恢復(fù)速度
節(jié)點宕機(jī)、大請求等情況都會直接影響讀寫請求,威脅集群的可用率。肖冰講到,他們主要是通過并發(fā)的數(shù)據(jù)恢復(fù),來將整個集群的宕機(jī)速度從最初需要一個小時左右的時間,縮短至15、6分鐘內(nèi),就可以完成200臺以上集群從宕機(jī)到拉起的動作。
作何一個技術(shù)方案從設(shè)計到真正落地,都需要進(jìn)行不斷的試錯和調(diào)優(yōu),肖冰他們也是如此。“我們這個業(yè)務(wù)剛上線的時候,理論上來講恢復(fù)速度應(yīng)該要比之前的方式要快。但是很多情況下,數(shù)據(jù)恢復(fù)的速度比我們預(yù)想的要慢很多,甚至在某些場景下的速度還不如以前。我們需要基于實際情況不斷做優(yōu)化。”
比如說在進(jìn)行并發(fā)數(shù)據(jù)恢復(fù)時,如果對正常的用戶請求和恢復(fù)數(shù)據(jù)都執(zhí)行了寫入操作,這兩個寫入請求就會互相爭搶資源,從而導(dǎo)致整個集群的恢復(fù)速度被大大拖慢。為了解決這個問題,阿里HBase針對許多細(xì)節(jié)進(jìn)行優(yōu)化,比如設(shè)置限定開關(guān),考慮到應(yīng)該側(cè)重恢復(fù)業(yè)務(wù)數(shù)據(jù),所以先恢復(fù)寫的部分。通過設(shè)置開關(guān),外部流量就無法進(jìn)入集群,從而避免資源爭搶對數(shù)據(jù)恢復(fù)的影響;再如針對red buffer設(shè)置的優(yōu)化。寫red buffer時,如果red buffer設(shè)置過大也可能影響恢復(fù)速度。
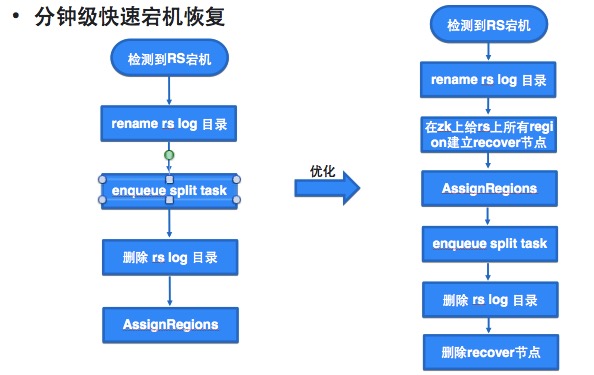
調(diào)度優(yōu)化解決大請求
大請求是指對系統(tǒng)資源消耗特別大的請求,典型的例子就是帶有Filter的Scan,這個Filter過濾掉了大量的數(shù)據(jù),導(dǎo)致一個Next操作會訪問成百上千個Block。當(dāng)Block大部分都在內(nèi)存時,這種Scan就會消耗大量CPU資源。在解決大請求方面,肖冰也給出了兩點優(yōu)化建議:
- 限制大請求的資源消耗,讓正常的請求可以獲取資源。通過sleep達(dá)到目的;
- 中斷掉對客戶端來說已經(jīng)超時的請求,這種請求繼續(xù)運行沒有意義。中斷請求釋放資源。
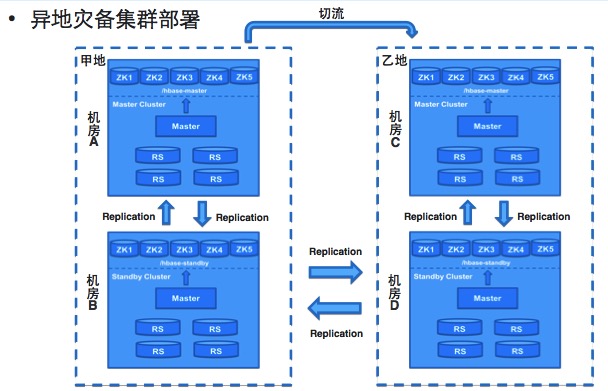
災(zāi)備部署
Hbase現(xiàn)在的集群容災(zāi)主要通過兩種方式。第一是同城的主備切換的容災(zāi)。客戶端通過配置ZK集群地址以及Parent Znode訪問HBase,為了實現(xiàn)客戶端在主備集群之間的無縫切換使用了虛擬Parent Znode(VZnode)代替了物理Parent Znode,VZnode存儲的內(nèi)容就是實際指向的物理Parent Znode,通過VZnode指向不同的物理Node實現(xiàn)客戶端在主備集群之間的無縫切換。
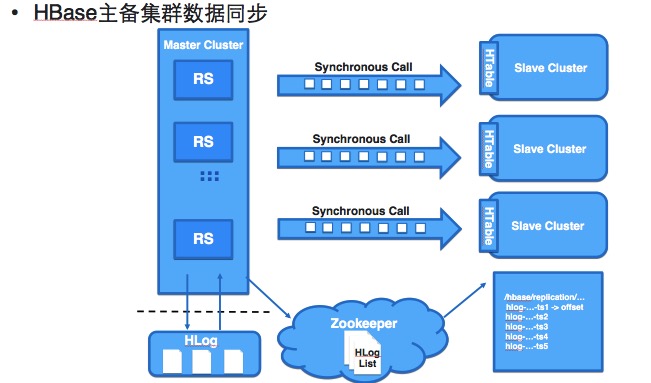
第二是異地的容災(zāi)。通過多地的集群部署,多地同時完成數(shù)據(jù)同步去提供存儲服務(wù)。
未來的優(yōu)化方向
采訪最后,肖冰與記者分享了未來阿里HBase的優(yōu)化方向,主要會集中在推動運維自動化及虛擬化部署兩個方面。
具體來說,一是將運維變更、資源申請、性能評估等這些日常的運維工作實現(xiàn)完全的自動化動化,提高運維效率。另一方面是把HBase現(xiàn)在由物理機(jī)的部署改成虛擬節(jié)點的部署,通過虛擬化更好地提高資源利用率,提高資源調(diào)動速度。