













反欺詐架構中的數據架構及其技術挑戰
譯文作者:布加迪編譯
反欺詐系統架構方面的一半工作可能花在了穩健而靈活的數據基礎設施上。要是沒有數據,規則和模型就玩不轉。許多時候,你需要從不同的角度和不同的距離來看待同一批數據,還需要能夠不斷以低成本獲取新數據;你遲早會發現自己擁有海量數據,因此擁有一套可擴展、穩健的基礎設施來管理這些數據是核心。
【51CTO.com快譯】數據、規則和模型,這些是反欺詐軟件系統的基本構建模塊。我會在一系列文章中介紹這些基礎模塊。
關鍵:合適的數據在合適的時間以合適的格式呈現
反欺詐系統架構方面的一半工作可能花在了穩健而靈活的數據基礎設施上。要是沒有數據,規則和模型就玩不轉。許多時候,你需要從不同的角度和不同的距 離來看待同一批數據,還需要能夠不斷以低成本獲取新數據;你遲早會發現自己擁有海量數據,因此擁有一套可擴展、穩健的基礎設施來管理這些數據是核心。
這么說可能過于簡單了。下面我們來看看你要處理的一些常見類型的數據:
聚集
- 例子:客戶的終生支出(合計)、SKU的爭議數(計數)、客戶使用的所有IP地址(聚集和重復數據刪除),以及某國別的最新采購期(最小/最大)。
- 目的:對于迅速從不同角度了解某個帳戶或實體很有用,你可以了解大局以及相應交易與之相比如何。
- 技術挑戰:
- ·實時聚集,還是預聚集?
- “實時”的優點:可獲得粒度更細的最新數據。
- “實時”的缺點:尤其是聚集的數據量很龐大時,操作開銷很大;原始數據源與反欺詐決策緊密相關。
- 預聚集的優點:可以將開銷很大的數據處理交給異步處理機制,那樣決策時數據檢索起來速度快,成本低;決策服務完全依賴聚集和專用的欺詐數據,而不是原始事務數據源。
- 預聚集的缺點:由于具有異步性,聚集的數據可能過時。
- 通 常來說,數據在決策時讀取,但是因影響數據的活動而出現帶外變更(添加、更新和刪除)。比如說,在結賬決策點,你可能想要評估這個用戶退了多少次商品。退 貨的流程有別于正常結賬,而且本身有全然不同的生命周期。因此,結賬時聚集退貨數量沒有意義。此外,某個正常用戶帳戶的退貨數量應該遠低于結賬數量,所以 按結賬數量計算退貨數量是一種過分行為,浪費資源。
- 通常來說,預聚集比實時聚集更具擴展性。
- ·實時聚集,還是預聚集?
- 盡可能使用增量聚集
- 簡單的例子就是用戶的最大采購量。一般來說,你會保存用戶輸入的最大數,如果新的數量大于之前的最大數,你就換成新的數量;不然,你就忽視。每當需要聚集時檢索用戶的所有交易,并從中找到最大數沒有太多的意義。
- 一個比較復雜的例子是SKU的爭議數。每當你收到一個新的爭議,你可能只想為最后一個數+1,而不是查詢SKU的所有爭議。當然了,這需要觸發系統(可能是消息分發框架)來保證分發,而且只分發一次。
- Lambda架構
想要集兩者之眾長?使用Lambda架構怎么樣?通過聚集批處理層(通常是舊數據,在“較慢”但更具可擴展的“大數據”基礎設施上執行)和速度層(實時增量聚集最新數據,在Samza或Spark Streaming之類的流處理基礎設施上執行),這就能同時獲得可擴展性和新鮮度。
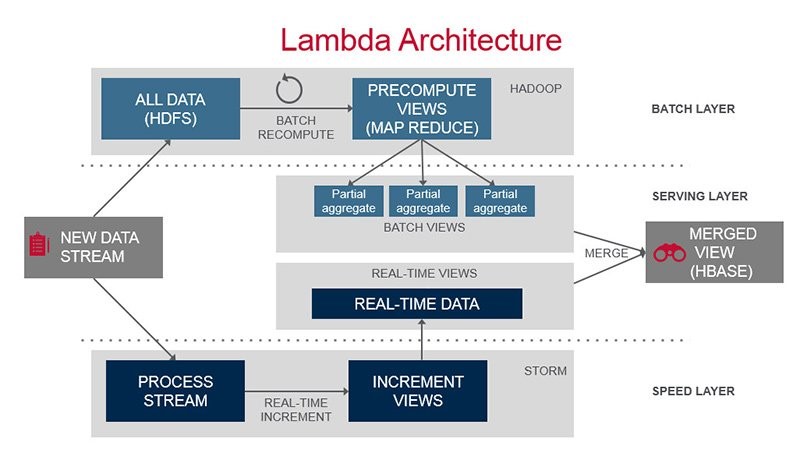
- 例子:在過去90秒內來自某個IP地址的企圖登錄次數;過去10分鐘來自某個用戶的企圖“添加信用卡”的次數;過去24小時內來自同一個Geohash的新注冊次數。
- 目的:騙子們常常采用蠻力惡意活動來攻擊商家。比如說,蠻力登錄攻擊的癥狀是,同一個IP地址在短短的時間內多次企圖登錄。騙子們還在短短的時間內,通過未起疑心的商家的“增添信用卡”流程,測試竊取的信用卡號碼。
- 速度與聚集有何不同?速度通常衡量某個活動在一段比較短的時間內(比如秒鐘、分鐘或小時)發生得多快,而聚集通常與更長的時間段有關。
- 技術挑戰:
- 由于它處理較短的時間,可用性延遲是有待優化的主要方面。你也許能夠使用同一個消息分發系統,就像在聚集使用場合下那樣,以觸發速度計算,但是要認真評估和監控端到端延遲。畢竟,60秒鐘的延遲會讓你的目標速度“過去60秒鐘的登錄次數”毫無用處。
- 如果異步處理系統帶來了無法忍受的延遲,你可能需要考慮實時查詢數據。沒錯,它存在與我們在上面聚集使用場合下談論的同樣缺點,不過幸好時間短,因而查詢性能仍比較好。
- 速 度計算的另一個常見要求是,可以靈活地擁有不同的多個維度,也就是說可以交叉分析(slice and dice)。比如說,你可能想要知道在過去5分鐘來自同一個IP地址的登錄次數,但是可能還想知道在過去5分鐘登錄同一帳戶的次數;那么,何不計算同一 IP地址登錄到同一帳戶的次數。這就需要你用預定義的維度/存儲桶聚集數據(事先知道訪問模式),或者以一種查詢起來非常靈活的方式來存儲原始數據(換句 話說,你沒必要事先定義訪問模式)。至于后一種實施方法,ElasticSearch之類的技術會行得通。
查詢
- 例子:有了一個IP地址,找到地理位置信息(經度、緯度、國家和城市);從信用卡的BIN(銀行識別號)到發卡行名稱和銀行所在國;從郵 政編碼到地理位置信息。除了你免費獲得(來自公共數據)或通過購買獲得的外部查詢數據外,許多內部生成的查詢數據也非常有用,比如說來自IP地址的壞事務 在事務總數中的比例,來自某個國家的虛假注冊數量,等等。
- 目的:查詢數據(外部或內部)是合成的情報,它剖析了某些工具的風險狀況,或者提供了可用于進一步評估的生成數據。從IP地址到地理位置的查詢推導,以及從(開票)郵政編碼到地理位置的推導,讓你能夠計算出交易地址與開票地址之間的距離。
- 技術挑戰:
- 大多數查詢數據并不經常變化。比如說,BIN查詢可能每月最多更新一次,IP內部風險可能沒必要為每個事務重新計算,但是可以每天重新計算。所以,這種類型的模式對批處理來說很理想。
- 許多數據會海量查詢,比如說每筆事務。由于它們相對靜態,緩存是一種出色的策略。內存提供的緩存顯著縮短了延遲。視數據集的大小和延遲要求而定,它們可以與決策服務一同緩存(速度最快),或者通過集中式緩存層來緩存。
- 如果內存不適合緩存數據集,又需要文件系統,仍可以通過索引數據在內存中文件中位置來進行優化,那樣第一輪是從內存獲得數據的位置,然后直接訪問文件中的該位置。查看mmap(https://en.wikipedia.org/wiki/Mmap)。
- 即便數據集在單個節點裝不下,也可以進行分區后分發。數據可以在其中一個節點上,目錄節點可以將查詢請求轉發給含有數據的那個節點。
- ·然查詢數據不常變化,但是它們通常很龐大。這樣一來,更新起來有難度。最笨拙的辦法就是,更新期間,翻新整個數據集。你可能想要考慮創建一個全新版本的數據集,將它與工作版本并行上傳,然后在新版本驗證完畢后換掉。這確保更新過程中沒有停機時間。
- 在外部,你可能想要簡化自動獲取更新的過程,通過通知新版本可用性來調度或觸發。
- 在內部,計算查詢數據對分析型數據基礎設施來說是完美任務,比如數據倉庫及/或Hadoop。同樣,你需要一條管道,以盡可能少的人力,將生成數據傳輸到生產環境。
圖形
- 例子:誰從同一個IP地址注冊,誰使用同樣的信用卡,誰是在你網站上展示同樣異常瀏覽模式的用戶。
- 目的:用戶基本上是好的,騙子只是少數。不斷回到你的平臺來欺騙的是一小撮壞人,他們使用不同的身份(假冒或真實的身份)。檢測誰是你所知道的騙子,是防止欺詐的一種有效方法。
- 技術挑戰:
- 關系數據庫并不以圖形關系見長,尤其是需要多度關聯的情況下(A與B關聯,B與C關聯,因而A與C關聯)。
- 圖形數據庫(比如Neo4j)非常適合這個用途。或者,Triplestore又叫RDF(資源描述框架)也可以。
- 要考慮的方面:
- 為 你的圖形關系正確建模。比如說,你可能試圖通過將通過IP地址1.2.3.4與用戶B關聯的用戶A建模成“A->B”, IP 1.2.3.4作為該鏈接的屬性。然而,想添加同樣使用1.2.3.4的用戶C,你就需要表示A->C和B->C,這2個鏈接每個都有屬性 1.2.3.4。這種情況下的IP地址“隱藏起來”或不是顯式的。因而,同樣的IP地址重復、單獨表示。為這種場景建模的更好方法就是 A->IP(.2.3.4)、B->IP(1.2.3.4)、C->IP(1.2.3.4)。由于IP(1.2.3.4)是圖形中的同 一個節點,A、B和C通過它關聯起來。想發現誰通過IP地址與A關聯起來,這是個簡單圖形,從A開始遍歷,沿著外出到IP節點的邊緣,然后從IP節點進入 到用戶節點。
- 很難擴展圖形數據庫。傳統的數據庫擴展方法是分段(sharding)。由于圖形的性質(互相關聯的節點),幾乎不可能對 圖形分段。你可能想要考慮根據你的獨特數據進行分區。比如說,如果欺騙攻擊由特定的國家來區別,或受制于特定的國家,也許可以把屬于同一個國家的實體扔入 到單一圖形數據庫節點,每個國家及/或地區有各自的節點。
日志
- 例子:決策時的所有數據點及數值;用戶的會話和點擊流數據。
- 目的:值得關注的活動發生時,可以深入了解狀態信息非常重 要,因為事后,數據點可能被新的數值覆蓋。知道時間點的數值有助于a)調查研究和b)訓練你的模型。用戶如何使用你的服務和網站,他們訪問哪些頁面,訪問 順序怎樣,他們花了多少時間,這些都是值得關注的數據,可以區別正常使用模式和欺詐使用模式。
- 技術挑戰:
- 數據庫可以用來跟蹤這些數據點,但是這些是日志數據,從不變化,支持事務的聯機數據庫是大材小用。
- 日志系統是非常適合于此的完美工具。可以將它們記入到文件系統日志文件,讓它們定期傳輸到長期存儲系統,比如Flume和HDFS;或者使用Kafka將它們發布到數據流,讓它們在處理后,永久性保存到長期存儲系統。
至于規則和模型,敬請關注下幾期文章。
原文標題:Data Architecture in an Anti-Fraud Architecture
【51CTO.com獨家譯文,合作站點轉載請注明來源】
責任編輯:Ophira
來源:
51CTO.com





















